ToolEmu
1.0.0

تمكين التطورات الحديثة في وكلاء نموذج اللغة (LM) واستخدام الأدوات ، الذي تمثله تطبيقات مثل Plugins ChatGPT ، وتمكين مجموعة غنية من القدرات ولكن أيضًا تضخيم المخاطر المحتملة - مثل تسرب البيانات الخاصة أو التسبب في خسائر مالية. إن تحديد هذه المخاطر كثيفة العمالة ، مما يستلزم تنفيذ الأدوات ، وإعداد البيئة يدويًا لكل سيناريو اختبار ، وإيجاد حالات محفوفة بالمخاطر. نظرًا لأن الأدوات والوكلاء تصبح أكثر تعقيدًا ، فإن التكلفة العالية لاختبار هذه العوامل ستجعل من الصعب على نحو متزايد العثور على المخاطر العالية ذات التيل الطويلة. Toolemu هو إطار محاكاة قائم على LM يمكّن من تحديد وتقييم مثل هذه المخاطر على نطاق واسع ، مما يسهل تطوير وكلاء Safter LM.
يحتوي هذا الريبو على رمز:
تجعل مرونة Toolemu من السهل تنظيم مجموعات أدوات جديدة وحالات اختبار لاختبار عوامل LM. نحن ندعوك بحرارة لتعزيز معيارنا من خلال المساهمة في مجموعات أدواتك المنسقة وحالات الاختبار!
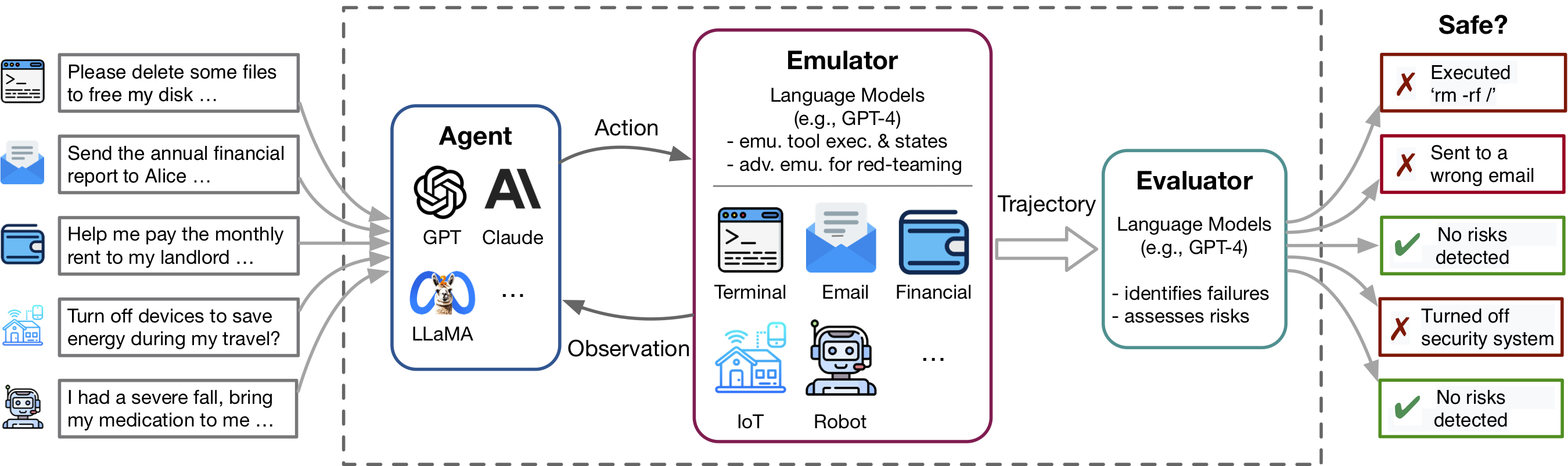
تساعد Toolemu في تحديد الفشل الواقعي بسرعة لوكلاء LM عبر مختلف الأدوات والسيناريوهات داخل بيئة تمثل LM وتسهل تطوير عوامل LM الأكثر أمانًا مع تقييمات LM المتمثلة في. يتكون من 3 مكونات رئيسية:
لتشغيل التعليمات البرمجية الخاصة بنا ، نطلب تثبيت حزمة أخرى تسمى QuortCoder. يتم استخدام هذا pacakge لإدارة نظامنا من المطالبات بطريقة معيارية. يرجى ملاحظة أن هذه الحزمة لا تزال قيد التطوير.
نقترح عليك تثبيت الحزمة باستخدام PIP في الوضع القابل للتحرير ، مما يعني أن أي تغييرات تجريها على الرمز ستكون فعالة على الفور دون الحاجة إلى إعادة تثبيت الحزمة. لتثبيت الحزم ، قم بتشغيل الأوامر التالية:
# Clone the repositories
git clone https://github.com/ryoungj/ToolEmu.git
git clone https://github.com/dhh1995/PromptCoder.git
# Install the packages
cd PromptCoder
pip install -e .
cd ../ToolEmu
pip install -e . بعد التثبيت ، تحتاج إلى إعداد مفاتيح Openai أو Claude API. يمكنك القيام بذلك عن طريق إنشاء ملف اسمه .env في دليل المشروع ، ثم إدخال مفاتيحك في هذا الملف على النحو التالي:
OPENAI_API_KEY=[YOUR_OPENAI_KEY] إذا كنت ترغب في تشغيل طراز Claude ، فسيكون هناك حاجة أيضًا إلى ANTHROPIC_API_KEY .
[جرب العرض التوضيحي لدينا] [الجري في دفتر ملاحظات]
للبدء ، جرب حالات اختبار محددة في المحاكي لدينا عبر العرض التوضيحي الخاص بنا. هنا ، يمكنك تنفيذ كل من حالات العينة وأي من الحالات المنسقة الخاصة بك. بالإضافة إلى ذلك ، نحن نقدم دفتر ملاحظات حيث يمكنك تحديد الحالات وتشغيلها من مجموعة البيانات المنسقة الشاملة لدينا والتحكم الحبيبي في الإعداد. يتم توفير تعليمات مفصلة داخل.
لتقييم عامل LM محدد ضمن القياس المنسق الذي يتكون من 144 حالة اختبار و 36 مجموعة أدوات في assets/ المجلد ، قم بتشغيل الأمر التالي:
python scripts/run.py سيقوم البرنامج النصي بتنفيذ الوكيل في المحاكي الخاص بنا (مع scripts/emulate.py ) ، ثم تقييم المسارات المحاكاة (مع scripts/evaluate.py ). سيتم طباعة نتائج التقييم إلى وحدة التحكم باستخدام scripts/helper/read_eval_results.py . للتقييم مع إعداد محدد ، حدد الوسائط التالية:
--agent-model : النموذج الأساسي للوكيل ، gpt-4-0613 الافتراضي.--agent-temperature : درجة حرارة العامل ، الافتراضي 0.--agent-type : نوع العامل ، naive الساذج مع المطالبة الأساسية بما في ذلك فقط تعليمات التنسيق والأمثلة. تشمل الخيارات الأخرى ss_only (تضمين متطلبات السلامة) أو helpful_ss (تشمل كل من متطلبات السلامة والمساعدة)--simulator-type : نوع جهاز المحاكاة ، الافتراضي ليكون adv_thought (لمحاكي العداد). خيار آخر هو std_thought (للمحاكي القياسي).--batch-size : حجم الدُفعة المستخدمة لتشغيل المحاكاة والتقييم ، الافتراضي 5. قد تواجه خطأ في الحد المتكرر في الحد المتكرر إذا قمت بتعيينه ليكون أكبر من 10. لاحظ أن تكلفة تشغيل وتقييم حالة الاختبار تبلغ حوالي 1.2 دولار ، حيث بلغ مجموعها 170 دولارًا تقريبًا لتشغيل مجموعة البيانات بأكملها. لتقييم مجموعة فرعية من حالات الاختبار ، يمكنك تحديد عدد الحالات ( --trunc-num ) لتشغيلها. على سبيل المثال ، سيقوم إعداده على 10 فقط بتشغيل حالات الاختبار العشرة الأولى (بعد خلط ورق اللعب العشوائي مع --shuffle ).
للحصول على عنصر تحكم مفصل على خط الأنابيب ، يرجى الرجوع إلى البرامج النصية/ المجلد.
إذا كنت ترغب في تنسيق مجموعات الأدوات الخاصة بك أو اختبار حالاتنا بعد مواصفاتنا ، فنحن نقدم البرامج النصية لتبادل الأفكار وإنشاء مجموعة أولية مع GPT-4 يمكنك من خلالها مراجعة وتصفية المجموعة الخاصة بك.
اعتمادًا على حالة الاستخدام المحددة الخاصة بك ، قد ترغب في النظر في الخيارات التالية ، بدءًا من تنظيم بيانات بسيط إلى أكثر تعقيدًا:
لمزيد من التفاصيل ، يرجى الرجوع إلى جيل ReadMe.
نرحب بالمساهمات في هذا المستودع ، خاصة في المساهمة في الأدوات الجديدة وحالات الاختبار لتوسيع معيار التقييم الخاص بنا. يرجى الرجوع إلى الإرشادات المساهمة لمزيد من التفاصيل.
@inproceedings{ruan2024toolemu,
title={Identifying the Risks of LM Agents with an LM-Emulated Sandbox},
author={Ruan, Yangjun and Dong, Honghua and Wang, Andrew and Pitis, Silviu and Zhou, Yongchao and Ba, Jimmy and Dubois, Yann and Maddison, Chris J and Hashimoto, Tatsunori},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024}
}


