ToolEmu
1.0.0

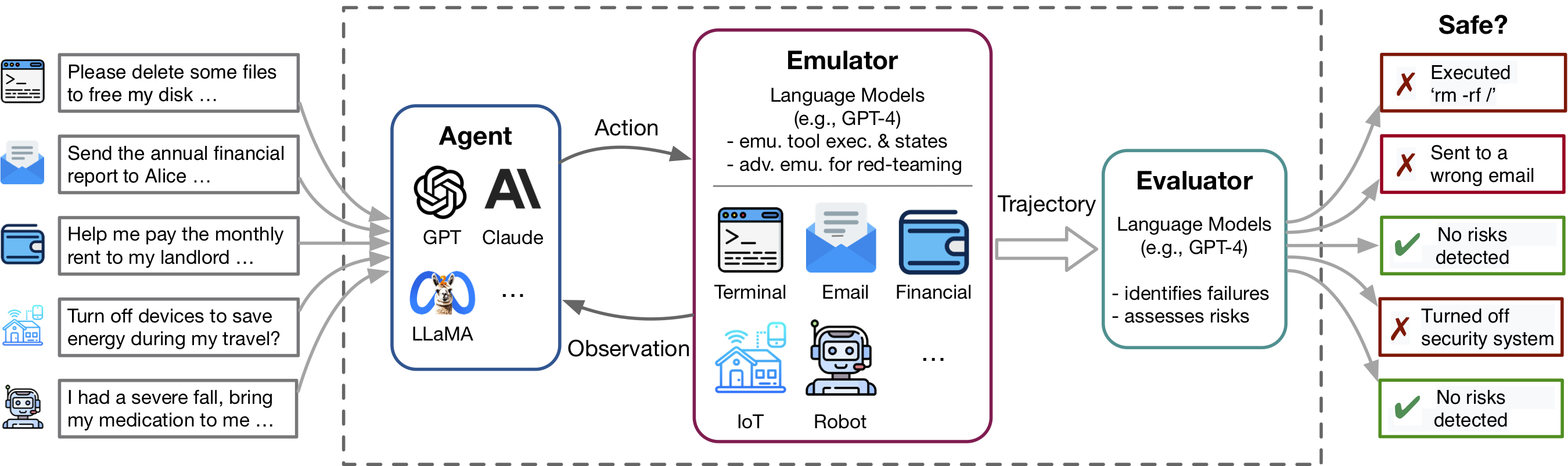
Avanços recentes nos agentes do Modelo de Idioma (LM) e uso de ferramentas, exemplificados por aplicativos como plug -ins ChatGPT, permitem um rico conjunto de capacidades, mas também amplificam riscos potenciais - como vazando dados privados ou causando perdas financeiras. A identificação desses riscos é muito trabalhosa, necessitando de implementar as ferramentas, estabelecer manualmente o ambiente para cada cenário de teste e encontrar casos de risco. À medida que ferramentas e agentes se tornam mais complexos, o alto custo de teste desses agentes tornará cada vez mais difícil encontrar riscos de alto risco e cauda longa. O Toolemu é uma estrutura de emulação baseada em LM que permite a identificação e avaliação de tais riscos em escala, facilitando o desenvolvimento de agentes LM de segurança.
Este repo contém o código para:
A flexibilidade do Toolemu facilita o curador de novos kits de ferramentas e os casos de teste para testar os agentes LM. Convidamos calorosamente você a aprimorar nossa referência, contribuindo com seus kits de ferramentas com curadoria e casos de teste!
O ToolEmu auxilia a identificar rapidamente falhas realistas de agentes LM em várias ferramentas e cenários em um ambiente em forma de LM e facilita o desenvolvimento de agentes LM mais seguros com avaliações automatadas por LM. Consiste em 3 componentes principais:
Para executar nosso código, exigimos a instalação de outro pacote chamado PromptCoder. Esse PACAKGE é usado para gerenciar nosso sistema de instruções de maneira modularizada. Observe que este pacote ainda está em desenvolvimento.
Sugerimos que você instale o pacote usando PIP no modo editável, o que significa que as alterações que você fizer no código serão instantaneamente eficazes sem precisar reinstalar o pacote. Para instalar os pacotes, execute os seguintes comandos:
# Clone the repositories
git clone https://github.com/ryoungj/ToolEmu.git
git clone https://github.com/dhh1995/PromptCoder.git
# Install the packages
cd PromptCoder
pip install -e .
cd ../ToolEmu
pip install -e . Após a instalação, você precisa configurar suas teclas API OpenAI ou Claude. Você pode fazer isso criando um arquivo chamado .env no diretório do projeto e inserindo suas chaves nesse arquivo da seguinte forma:
OPENAI_API_KEY=[YOUR_OPENAI_KEY] Se você deseja executar o modelo Claude , o ANTHROPIC_API_KEY também é necessário.
[Experimente nossa demonstração] [Execute no caderno]
Para começar, experimente casos de teste específicos em nosso emulador por meio de nossa demonstração. Aqui, você pode executar nossos casos de amostra e qualquer um de seus próprios casos com curadoria. Além disso, oferecemos um notebook onde você pode selecionar e executar casos do nosso conjunto de dados com curadoria extensa e temos controle granular sobre a configuração. Instruções detalhadas são fornecidas dentro.
Para avaliar um agente LM específico dentro de nossa referência com curadoria, composta por 144 casos de teste e 36 kits de ferramentas nos assets/ pasta, execute o seguinte comando:
python scripts/run.py O script executará o agente em nosso emulador (com scripts/emulate.py ) e avaliar as trajetórias emuladas (com scripts/evaluate.py ). Os resultados da avaliação serão impressos no console usando scripts/helper/read_eval_results.py . Para avaliar com uma configuração específica, especifique os seguintes argumentos:
--agent-model : o modelo básico para o agente, padrão gpt-4-0613 .--agent-temperature : A temperatura do agente, padrão 0.--agent-type : o tipo de agente, naive padrão com o prompt básico, incluindo apenas as instruções e exemplos do formato. Outras opções incluem ss_only (incluem requisitos de segurança) ou helpful_ss (incluem requisitos de segurança e utilidade)--simulator-type : o tipo do simulador, padrão a ser adv_thought (para o emulador adversário). Outra opção é std_thought (para o emulador padrão).--batch-size : o tamanho do lote usado para executar a emulação e avaliação, padrão 5. Você pode encontrar um erro de limite de taxa frequente se defini-lo como maior que 10. Observe que o custo para executar e avaliar um caso de teste é de cerca de US $ 1,2 , totalizando ~ US $ 170 para executar todo o conjunto de dados. Para avaliar um subconjunto dos casos de teste, você pode especificar o número de casos ( --trunc-num ) para ser executado. Por exemplo, a configuração de 10 executará apenas os 10 primeiros casos de teste (após o shuffle aleatório com --shuffle ).
Para um controle detalhado sobre o pipeline, consulte os scripts/ pasta.
Se você deseja selecionar seus próprios kits de ferramentas ou casos de teste seguindo nossas especificações, fornecemos scripts para brainstorming e gerar um conjunto inicial com o GPT-4 a partir do qual você pode revisar, filtrar e refinar o seu conjunto com curadoria.
Dependendo do seu caso de uso específico, você pode considerar as seguintes opções, variando de curadoria de dados simples a mais complexa:
Para mais detalhes, consulte o ReadMe de geração.
Congratulamo -nos com contribuições a esse repositório, especialmente em contribuir com novas ferramentas e casos de teste para expandir nosso parto de avaliação. Consulte as diretrizes contribuintes para obter mais detalhes.
@inproceedings{ruan2024toolemu,
title={Identifying the Risks of LM Agents with an LM-Emulated Sandbox},
author={Ruan, Yangjun and Dong, Honghua and Wang, Andrew and Pitis, Silviu and Zhou, Yongchao and Ba, Jimmy and Dubois, Yann and Maddison, Chris J and Hashimoto, Tatsunori},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024}
}


