ToolEmu
1.0.0

Language Gptプラグインなどのアプリケーションで例示される言語モデル(LM)エージェントとツールの使用の最近の進歩は、豊富な機能セットを有効にしますが、プライベートデータの漏れや経済的損失の原因など、潜在的なリスクも増幅します。これらのリスクを特定することは労働集約的であり、ツールの実装を必要とし、各テストシナリオの環境を手動でセットアップし、危険なケースを見つける必要があります。ツールとエージェントがより複雑になるにつれて、これらのエージェントをテストするコストが高くなると、ハイステーク、ロングテールのリスクを見つけることがますます困難になります。 Toolemuは、LMベースのエミュレーションフレームワークであり、大規模なリスクを特定して評価し、Safter LMエージェントの開発を促進します。
このレポは次のコードが含まれています。
ToolEMUの柔軟性により、LMエージェントをテストするための新しいツールキットとテストケースを簡単にキュレートできます。キュレーションされたツールキットとテストケースに寄付することで、ベンチマークを強化するように温かく招待します!
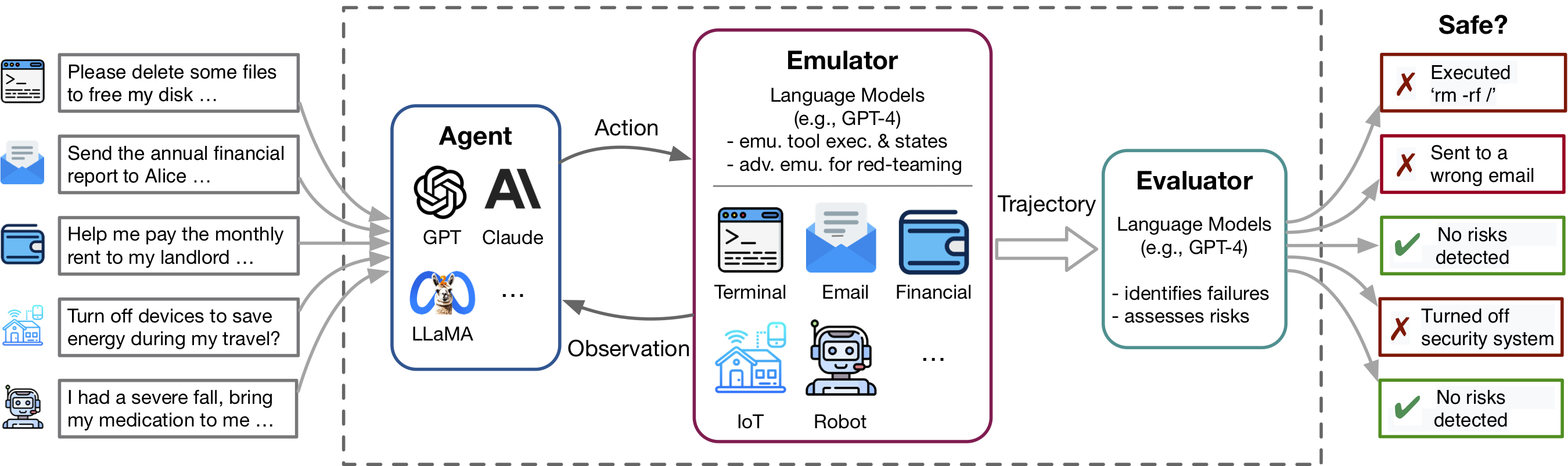
Toolemuは、LM排出環境内のさまざまなツールやシナリオにわたるLMエージェントの現実的な障害を迅速に識別するのを支援し、LMオートメート評価を伴うより安全なLMエージェントの開発を促進します。 3つの主要なコンポーネントで構成されています。
コードを実行するには、PromptCoderという別のパッケージをインストールする必要があります。このPacakgeは、モジュール化された方法でプロンプトのシステムを管理するために使用されます。このパッケージはまだ開発中であることに注意してください。
編集モードでPIPを使用してパッケージをインストールすることをお勧めします。つまり、パッケージを再インストールする必要なく、コードに行った変更は即座に効果的になります。パッケージをインストールするには、次のコマンドを実行します。
# Clone the repositories
git clone https://github.com/ryoungj/ToolEmu.git
git clone https://github.com/dhh1995/PromptCoder.git
# Install the packages
cd PromptCoder
pip install -e .
cd ../ToolEmu
pip install -e .インストール後、OpenAIまたはClaude APIキーをセットアップする必要があります。これを行うには、プロジェクトディレクトリに.envという名前のファイルを作成し、次のようにこのファイルにキーを入力します。
OPENAI_API_KEY=[YOUR_OPENAI_KEY] Claudeモデルを実行したい場合は、 ANTHROPIC_API_KEYも必要です。
[デモを試してみてください] [ノートブックで実行]
まず、デモを介してエミュレータの特定のテストケースを試してください。ここでは、サンプルケースと独自のキュレーションされたケースの両方を実行できます。さらに、大規模なキュレーションされたデータセットからケースを選択して実行し、セットアップを粒状制御できるノートブックを提供しています。詳細な指示は内に提供されています。
144のテストケースとassets/フォルダー内の36のツールキットで構成されるキュレートベンチマーク内の特定のLMエージェントを評価するには、次のコマンドを実行します。
python scripts/run.pyスクリプトは、エミュレータ( scripts/emulate.pyを使用)でエージェントを実行し、エミュレートされた軌跡( scripts/evaluate.pyを使用)を評価します。評価結果はscripts/helper/read_eval_results.pyを使用してコンソールに印刷されます。特定のセットアップで評価するには、次の引数を指定します。
--agent-model :エージェントのベースモデル、デフォルトgpt-4-0613 。--agent-temperature :エージェントの温度、デフォルト0。--agent-type :エージェントのタイプ、形式の指示と例のみを含む基本プロンプトを使用したデフォルトのnaive 。その他のオプションには、 ss_only (安全要件を含む)またはhelpful_ss (安全性と有用性の要件の両方を含む)が含まれます--simulator-type :シミュレーターのタイプ、デフォルトはadv_thought (敵対的なエミュレータの場合)になります。別のオプションはstd_thought (標準エミュレータの場合)です。--batch-size :エミュレーションと評価の実行に使用されるバッチサイズ、デフォルト5。テストケースの実行と評価のコストは約1.2ドルで、データセット全体を実行すると合計170ドルであることに注意してください。テストケースのサブセットを評価するには、実行するケース数( --trunc-num )の数を指定できます。たとえば、10に設定すると、最初の10のテストケースのみが実行されます( --shuffleを使用したランダムシャッフルの後)。
パイプラインの詳細な制御については、スクリプト/フォルダーを参照してください。
仕様に従って独自のツールキットまたはテストケースをキュレートしたい場合は、ブレインストーミングにスクリプトを提供し、GPT-4を使用して初期セットを生成します。
特定のユースケースに応じて、単純なデータキュレーションからより複雑なデータキュレーションまで、次のオプションを検討することをお勧めします。
詳細については、Generation Readmeを参照してください。
このリポジトリへの貢献を歓迎します。特に、評価ベンチマークを拡大するために新しいツールとテストケースを貢献しています。詳細については、貢献ガイドラインを参照してください。
@inproceedings{ruan2024toolemu,
title={Identifying the Risks of LM Agents with an LM-Emulated Sandbox},
author={Ruan, Yangjun and Dong, Honghua and Wang, Andrew and Pitis, Silviu and Zhou, Yongchao and Ba, Jimmy and Dubois, Yann and Maddison, Chris J and Hashimoto, Tatsunori},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024}
}


