Unet TTS
1.0.0
อีเมล: [email protected]
อัลกอริทึมที่เราเสนอมีลำโพงที่ทรงพลังและความสามารถในการถ่ายโอนสไตล์โดยเฉพาะอย่างยิ่งการเลียนแบบอารมณ์นอกโดเมนที่ยอดเยี่ยม
รหัส
สมุดบันทึก colab
ผลลัพธ์ของแมนดาริน
ลิงค์กระดาษ
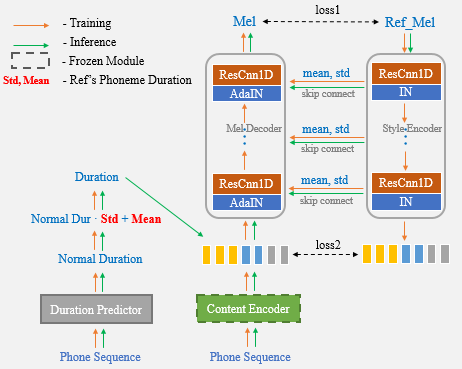
การโคลนนิ่งเสียงเดียวมีจุดมุ่งหมายเพื่อเปลี่ยนเสียงลำโพงและสไตล์การพูดในคำพูดที่สังเคราะห์จากระบบ text-to-speech (TTS) ซึ่งมีเพียงการบันทึกการยิงจากคำพูดเป้าหมายเท่านั้น การถ่ายโอนนอกโดเมนยังคงเป็นงานที่ท้าทายและสิ่งสำคัญอย่างหนึ่งที่ส่งผลกระทบต่อความแม่นยำและความคล้ายคลึงกันของคำพูดสังเคราะห์คือการเป็นตัวแทนแบบมีเงื่อนไขที่มีลำโพงหรือตัวชี้นำสไตล์ที่สกัดจากการอ้างอิงที่ จำกัด ในบทความนี้เรานำเสนออัลกอริทึมการโคลนเสียงแบบหนึ่งนัดที่เรียกว่า UNET-TTS ที่มีความสามารถในการวางนัยทั่วไปที่ดีสำหรับลำโพงและสไตล์ที่มองไม่เห็น ขึ้นอยู่กับโครงสร้าง U-NET ที่เชื่อมต่อกับ SKIP รุ่นใหม่สามารถค้นพบรายละเอียดคุณสมบัติสเปกตรัมระดับลำโพงและระดับเสียงจากเสียงอ้างอิงได้อย่างมีประสิทธิภาพทำให้สามารถอนุมานได้อย่างแม่นยำของลักษณะอะคูสติกที่ซับซ้อนรวมถึงการเลียนแบบรูปแบบการพูดในคำพูดสังเคราะห์ จากการประเมินทั้งอัตนัยและวัตถุประสงค์ของความคล้ายคลึงกันโมเดลใหม่มีประสิทธิภาพสูงกว่าทั้งการฝังลำโพงและการสร้างแบบจำลองสไตล์ที่ไม่ได้รับการดูแล (GST) เข้าใกล้คลังอารมณ์ที่มองไม่เห็น