Unet TTS
1.0.0
이메일 : [email protected]
우리의 제안 된 알고리즘에는 강력한 스피커 및 스타일 전송 기능, 특히 도메인 이외의 감정에 대한 탁월한 모방이 있습니다.
암호
Colab 노트북
만다린 결과
종이 링크
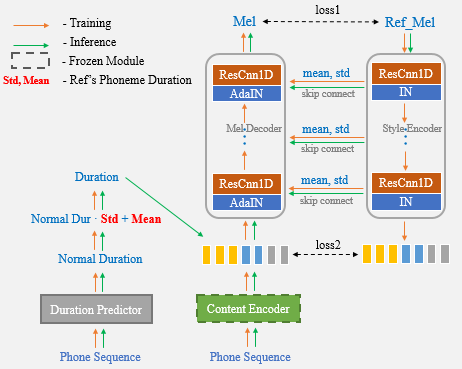
원샷 음성 복제는 대상 연설에서 샷 녹음 만 사용할 수있는 TTS (Text-To-Steece) 시스템에서 합성 된 스피커 음성과 말하기 스타일을 변환하는 것을 목표로합니다. 도메인 외 전송은 여전히 어려운 작업이며, 합성 음성의 정확성과 유사성에 영향을 미치는 중요한 측면 중 하나는 제한된 참조에서 추출한 스피커 또는 스타일 신호를 전달하는 조건부 표현입니다. 이 논문에서는 보이지 않는 스피커와 스타일에 대한 일반화 능력이 우수한 Unet-Tts라는 새로운 원샷 음성 클로닝 알고리즘을 제시합니다. 건너 뛰기 연결 U-Net 구조를 기반으로, 새로운 모델은 참조 오디오에서 스피커 레벨 및 발언 수준 스펙트럼 기능 세부 정보를 효율적으로 발견 할 수있어 복잡한 음향 특성의 정확한 추론과 말하기 스타일을 합성 음성으로 모방 할 수 있습니다. 유사성에 대한 주관적 및 객관적인 평가에 따르면, 새로운 모델은 스피커 임베딩과 감독되지 않은 스타일 모델링 (GST)이 보이지 않는 감정적 코퍼스에 대한 접근 방식을 능가합니다.