Unet TTS
1.0.0
Correo electrónico: [email protected]
Nuestro algoritmo propuesto tiene potentes capacidades de transferencia de altavoces y estilo, especialmente una excelente imitación de emociones fuera de dominio.
Código
Cuaderno de colab
Resultados de mandarín
Enlace de papel
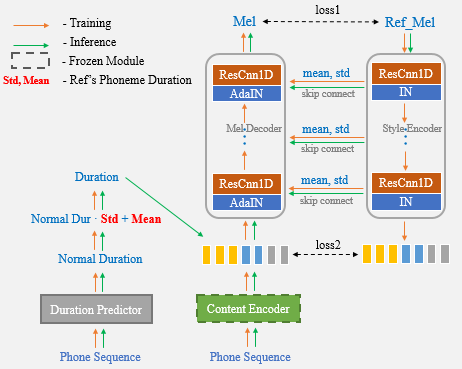
La clonación de voz de una sola vez tiene como objetivo transformar la voz de los altavoces y el estilo de hablar en el habla sintetizada de un sistema de texto a voz (TTS), donde solo se puede usar una grabación de disparo del discurso objetivo. La transferencia fuera del dominio sigue siendo una tarea desafiante, y un aspecto importante que afecta la precisión y similitud del habla sintética son las representaciones condicionales que llevan señales de altavoz o estilo extraídas de las referencias limitadas. En este artículo, presentamos un nuevo algoritmo de clonación de voz de un solo disparo llamado UNET-TTS que tiene una buena capacidad de generalización para oradores y estilos invisibles. Basado en una estructura de red U conectada a Skip, el nuevo modelo puede descubrir eficientemente los detalles de características espectrales a nivel de altavoz y de nivel de expresión del audio de referencia, lo que permite una inferencia precisa de características acústicas complejas, así como la imitación de estilos de habla en el habla sintética. Según las evaluaciones de similitud tanto subjetivas como objetivas, el nuevo modelo supera a los enfoques de incrustación de altavoces y modelado de estilo (GST) sin supervisión en un corpus emocional invisible.