Unet TTS
1.0.0
البريد الإلكتروني: [email protected]
تحتوي خوارزميةنا المقترحة على قدرات نقل قوية ونقل الأسلوب ، وخاصة التقليد الممتاز للعواطف خارج المجال.
شفرة
دفتر كولاب
نتائج الماندرين
رابط الورق
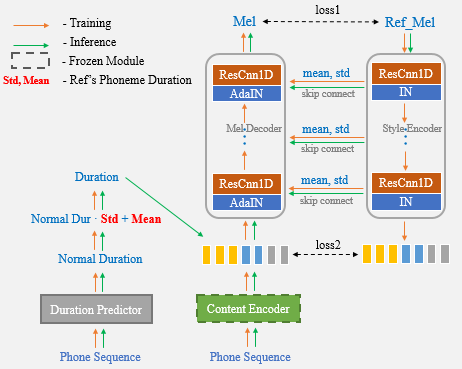
يهدف استنساخ صوت واحد إلى تحويل صوت مكبر الصوت وأسلوب التحدث في الكلام المصنوع من نظام من النص إلى كلام (TTS) ، حيث يمكن استخدام تسجيل لقطة من الكلام المستهدف فقط. لا يزال النقل خارج المجال مهمة صعبة ، وأحد الجوانب المهمة التي تؤثر على دقة وتشابه الكلام الاصطناعي هو التمثيلات المشروطة التي تحمل العظة أو الإشارات النمطية المستخرجة من المراجع المحدودة. في هذه الورقة ، نقدم خوارزمية استنساخ صوتية واحدة تسمى UNET-TTS والتي لديها قدرة تعميم جيدة للمكبرات والأساليب غير المرئية. استنادًا إلى بنية U-NET المتصلة ، يمكن للنموذج الجديد اكتشاف تفاصيل الميزة الطيفية على مستوى المتحدث بكفاءة من الصوت المرجعي ، مما يتيح الاستدلال الدقيق للخصائص الصوتية المعقدة بالإضافة إلى تقليد أنماط التحدث في الكلام الصناعي. وفقًا لكل من التقييمات الذاتية والموضوعية للتشابه ، يتفوق النموذج الجديد على كل من المتحدثين الذين يدمجون ونمذجة النمذجة غير الخاضعة للإشراف (GST) على مجموعة عاطفية غير مرئية.