Unet TTS
1.0.0
E -mail: [email protected]
Nosso algoritmo proposto possui poderosos recursos de transferência de alto-falante e estilo, especialmente uma excelente imitação de emoções fora do domínio.
Código
Caderno de Colab
Resultados de mandarim
Link em papel
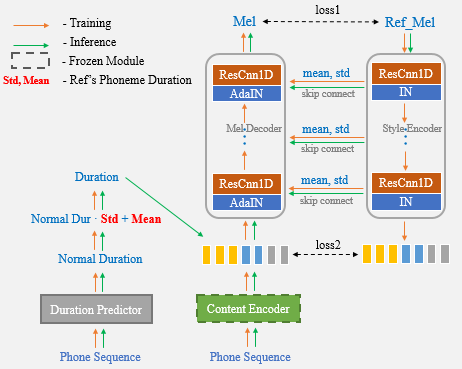
A clonagem de voz de um tiro pretende transformar a voz do alto-falante e o estilo de fala em fala sintetizado a partir de um sistema de texto em fala (TTS), onde apenas uma gravação de tiro do discurso de destino pode ser usada. A transferência fora do domínio ainda é uma tarefa desafiadora, e um aspecto importante que afeta a precisão e a semelhança da fala sintética são as representações condicionais que transportam pistas de alto-falante ou estilo extraídas das referências limitadas. Neste artigo, apresentamos um novo algoritmo de clonagem de voz de um tiro, chamado UNET-TTS, que tem boa capacidade de generalização para alto-falantes e estilos invisíveis. Com base em uma estrutura de rede U conectada por pular, o novo modelo pode descobrir com eficiência os detalhes do recurso espectral no nível do alto-falante e no nível de enunciado do áudio de referência, permitindo a inferência precisa de características acústicas complexas, bem como imitação de estilos de palestras na fala sintética. De acordo com avaliações subjetivas e objetivas de similaridade, o novo modelo supera as abordagens de modelagem de estilo e estilo não supervisionado (GST) em um corpus emocional invisível.