Unet TTS
1.0.0
Courriel: [email protected]
Notre algorithme proposé a des capacités de transfert de haut-parleurs et de style puissantes, en particulier une excellente imitation des émotions hors du domaine.
Code
Cahier de colab
Résultats du mandarin
Lien papier
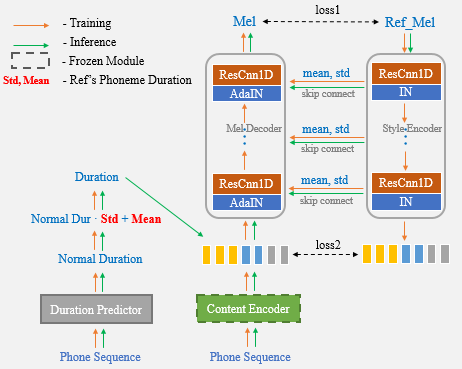
Le clonage vocal unique vise à transformer la voix du haut-parleur et le style de parole dans la parole synthétisée à partir d'un système de texte à dispection (TTS), où seul un enregistrement de tir de la parole cible peut être utilisé. Le transfert hors du domaine est toujours une tâche difficile, et un aspect important qui a un impact sur la précision et la similitude de la parole synthétique est les représentations conditionnelles portant des indices de haut-parleur ou de style extraits des références limitées. Dans cet article, nous présentons un nouvel algorithme de clonage vocal unique appelé Unet-TTS qui a une bonne capacité de généralisation pour les haut-parleurs et les styles invisibles. Sur la base d'une structure en U-Net connectée à Skip, le nouveau modèle peut découvrir efficacement les détails de caractéristiques spectrales au niveau du haut-parleur et au niveau de l'énoncé de l'audio de référence, permettant une inférence précise des caractéristiques acoustiques complexes ainsi que de l'imitation des styles de parole dans la parole synthétique. Selon les évaluations subjectives et objectives de la similitude, le nouveau modèle surpasse à la fois le haut-parleur incorpore et la modélisation de style non supervisé (TPS) sur un corpus émotionnel invisible.