Unet TTS
1.0.0
E -Mail: [email protected]
Unser vorgeschlagener Algorithmus verfügt über leistungsstarke Lautsprecher- und Stilübertragungsfähigkeiten, insbesondere eine hervorragende Nachahmung von Emotionen außerhalb der Domäne.
Code
Colab Notebook
Mandarinergebnisse
Papierverbindung
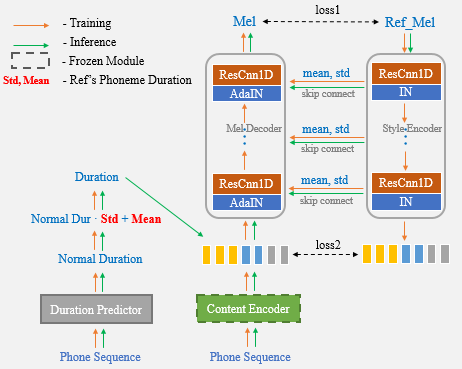
One-Shot Voice Cloning zielt darauf ab, die Sprecherstimme und den Sprechstil in der Sprache zu transformieren, die aus einem TTS-System (Text-to-Speech) synthetisiert wurden, bei dem nur eine Aufnahme von der Zielrede verwendet werden kann. Die Übertragung außerhalb des Domänens ist nach wie vor eine herausfordernde Aufgabe, und ein wichtiger Aspekt, der die Genauigkeit und Ähnlichkeit der synthetischen Sprache beeinflusst, sind die bedingten Darstellungen, die Sprecher oder Stilhinweise aus den begrenzten Referenzen tragen. In diesem Artikel präsentieren wir einen neuartigen One-Shot-Sprachklon-Algorithmus namens UNET-TTs, der eine gute Verallgemeinerung für unsichtbare Lautsprecher und Stile besitzt. Basierend auf einer übersprungen verbundenen U-NET-Struktur kann das neue Modell Speaker-Level- und Äußerungsebene-Spektral-Merkmalsdetails aus dem Referenz-Audio effizient erkennen, wodurch eine genaue Inferenz komplexer akustischer Merkmale sowie Nachahmungen von Sprechstilen in die synthetische Sprache ermöglicht werden. Nach subjektiven und objektiven Bewertungen der Ähnlichkeit übertrifft das neue Modell sowohl den Lautsprecher Einbettung als auch die Ansätze für die Modellierung von unbeaufsichtigten Stilen (GST) auf einem unsichtbaren emotionalen Korpus.