Unet TTS
1.0.0
Email: [email protected]
Algoritma yang kami usulkan memiliki kemampuan transfer speaker dan gaya yang kuat, terutama imitasi yang sangat baik dari emosi di luar domain.
Kode
Colab Notebook
Hasil Mandarin
Tautan kertas
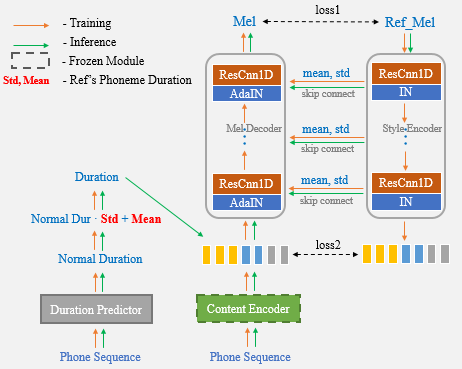
Kloning suara One-Shot bertujuan untuk mengubah suara speaker dan gaya berbicara dalam ucapan yang disintesis dari sistem teks-ke-pidato (TTS), di mana hanya rekaman bidikan dari ucapan target yang dapat digunakan. Transfer di luar domain masih merupakan tugas yang menantang, dan salah satu aspek penting yang memengaruhi keakuratan dan kesamaan pidato sintetis adalah representasi bersyarat yang membawa pembicara atau isyarat gaya yang diekstraksi dari referensi terbatas. Dalam makalah ini, kami menyajikan algoritma kloning suara satu-shot novel yang disebut UNET-TTS yang memiliki kemampuan generalisasi yang baik untuk speaker dan gaya yang tidak terlihat. Berdasarkan struktur U-Net yang terhubung dengan Skip, model baru ini dapat secara efisien menemukan detail fitur spektral tingkat speaker dan level ucapan dari audio referensi, memungkinkan inferensi akurat dari karakteristik akustik kompleks serta imitasi gaya berbicara ke dalam pidato sintetis. Menurut evaluasi kesamaan subyektif dan obyektif, model baru ini mengungguli kedua pemodelan speaker embedding dan tidak diawasi (GST) mendekati corpus emosional yang tidak terlihat.