Unet TTS
1.0.0
提案されているアルゴリズムには、強力なスピーカーとスタイルの転送機能、特にドメイン外の感情の優れた模倣があります。
コード
コラブノートブック
マンダリンの結果
紙のリンク
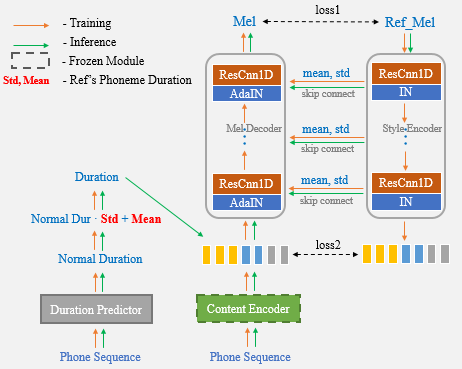
One-Shot Voice Cloningは、ターゲットスピーチからのショット録音のみを使用できるテキスト対スピーチ(TTS)システムから合成されたスピーチのスピーカー音声とスピーキングスタイルを変換することを目的としています。ドメイン外の転送は依然として困難なタスクであり、合成音声の精度と類似性に影響を与える重要な側面の1つは、限られた参照から抽出されたスピーカーまたはスタイルの手がかりを運ぶ条件付き表現です。この論文では、目に見えないスピーカーとスタイルに優れた一般化能力を持つUNET-TTSと呼ばれる新しいワンショット音声クローンアルゴリズムを紹介します。スキップ接続されたU-NET構造に基づいて、新しいモデルは、参照オーディオからスピーカーレベルのレベルのスペクトル機能の詳細を効率的に発見することができ、複雑な音響特性の正確な推論と合成スピーチへの模倣スタイルの模倣を可能にします。類似性の主観的および客観的評価の両方によれば、新しいモデルは、目に見えない感情的なコーパスで、スピーカーの埋め込みと監視されていないスタイルモデリング(GST)の両方のアプローチよりも優れています。