DragonianVoice
ve api

จีน | ภาษาอังกฤษ
ที่เก็บนี้ได้หยุดการบำรุงรักษาโครงการ UI อย่างถาวรและจะกลายเป็นโครงการ LIB บริสุทธิ์ ที่อยู่ที่เก็บรหัสคือ: Dragonianlib แต่การเปิดตัวเกี่ยวกับ SVC และ TTS ยังคงเปิดตัวในที่เก็บนี้
พื้นที่เก็บข้อมูลนี้คือ: 1. TTS (TACOTRON2, VITS, EmotionalVits, BertVits2, GPTSovits); 2. SVC (SovitsSVC, RVC, DiffusionsVC, FishDiffusion, reflowsVC); 3. SVS (diffsinger) ONNX Framework Resitisting Respository ปัจจุบันรองรับการโทร C/CPP/C#
เวอร์ชันล่าสุดของที่เก็บนี้เชื่อมโยงกับการพูดปลาและใช้กรอบ GGML เพื่อเขียนคำพูดปลาเพื่อสร้างโครงการย่อย fish-speech.cpp
หมายเหตุ: สาขาที่เปิดใช้งาน SVS: Moevoicestudio Moevoicestudiocore
เกี่ยวกับการสนับสนุน CUDA กรุณาเยี่ยมชมที่เก็บอย่างเป็นทางการของ OnnxRuntime
หลังจากการทดลอง DML จะทำให้ผู้ประกอบการที่ไม่ได้รับการสนับสนุนบางรายใน ONNX ไม่รายงานข้อผิดพลาดเมื่อใช้ แต่จะส่งคืนผลลัพธ์ที่ไม่คาดคิดซึ่งจะนำไปสู่ข้อผิดพลาดในผลการอนุมานของ SOVITS3.0 และ SOVITS4.0 ใน DMLEP อย่างไรก็ตามการส่งออก ONNX ในที่เก็บ SoVITS ล่าสุดได้แทนที่ผู้ให้บริการเหล่านี้ดังนั้น SoVITS3.0 และ SOVITS4.0 รองรับการใช้งานการกู้คืน DML แต่โมเดล ONNX จะต้องส่งออกอีกครั้งโดยใช้การส่งออก SovitsonNX รุ่นล่าสุด (2023/7/17)
เนื่องจากลักษณะของแบบจำลองการแพร่กระจายและการรีดกลับหากจำนวนขั้นตอนทั้งหมดที่คุณอนุมานมากกว่าจำนวนขั้นตอนสูงสุดที่คุณฝึกฝนในแบบจำลอง (จำนวนขั้นตอนจริง = จำนวนขั้นตอนทั้งหมด/การขยายการขยายจำนวนขั้นตอนทั้งหมดนี้ไม่ใช่จำนวนขั้นตอนที่คุณทำในระหว่างการอนุมาน ดังนั้นขอแนะนำให้คุณสังเกต MaxStep (หรือ K_STEP_MAX) อย่างระมัดระวังในไฟล์กำหนดค่าโมเดลของคุณก่อนการอนุมาน
โครงการนี้เป็น โครงการโอเพ่นซอร์สและออฟไลน์และนักพัฒนาและผู้ดูแลโครงการทั้งหมดของโครงการนี้ (ต่อไปนี้จะเรียกว่าผู้มีส่วนร่วม) ไม่สามารถควบคุมโครงการนี้ได้ ผู้มีส่วนร่วมของโครงการนี้ไม่เคยให้ความช่วยเหลือแก่องค์กรหรือบุคคลใด ๆ ทุกรูปแบบรวมถึง แต่ไม่ จำกัด เพียงการสกัดชุดข้อมูลการประมวลผลชุดข้อมูลการสนับสนุนพลังงานการคำนวณการสนับสนุนการฝึกอบรมการให้เหตุผล ฯลฯ ; ผู้มีส่วนร่วมของโครงการนี้ไม่ทราบหรือรู้วัตถุประสงค์ของผู้ใช้โดยใช้โครงการ ดังนั้นเสียงทั้งหมดที่สังเคราะห์ขึ้นอยู่กับโครงการนี้ไม่มีส่วนเกี่ยวข้องกับผู้มีส่วนร่วมของโครงการนี้ ปัญหาทั้งหมดที่เกิดจากสิ่งนี้เป็นไปตามความรับผิดชอบของผู้ใช้
โครงการนี้ไม่มีฟังก์ชั่นใด ๆ ของการสังเคราะห์เสียงพูด แต่ใช้เพื่อเริ่มการฝึกอบรมและการผลิตแบบจำลอง ONNX ของผู้ใช้เท่านั้น การฝึกอบรมแบบจำลองและการผลิตโมเดล ONNX ไม่เกี่ยวข้องกับผู้มีส่วนร่วมของโครงการนี้และเป็นพฤติกรรมของผู้ใช้ทั้งหมด ผู้มีส่วนร่วมของโครงการนี้ไม่ได้มีส่วนร่วมในการฝึกอบรมแบบจำลองและการผลิตของผู้ใช้ทุกคน
โครงการนี้ทำงานแบบออฟไลน์อย่างสมบูรณ์และไม่สามารถรวบรวมข้อมูลผู้ใช้ใด ๆ และไม่สามารถรับข้อมูลผู้ใช้ป้อนข้อมูลได้ ดังนั้นผู้มีส่วนร่วมของโครงการนี้ไม่ได้ตระหนักถึงอินพุตและรุ่นของผู้ใช้ทั้งหมดดังนั้นพวกเขาจึงไม่รับผิดชอบต่อการป้อนข้อมูลของผู้ใช้ใด ๆ
โครงการนี้ยังไม่ได้มาพร้อมกับรุ่นใด ๆ และรุ่นใด ๆ ที่มาพร้อมกับการเปิดตัวรองและโมเดลที่ใช้สำหรับโครงการนี้ไม่มีส่วนเกี่ยวข้องกับผู้พัฒนาโครงการนี้
ปัจจุบันโครงการนี้สนับสนุนการเรียกใช้วิธีการของตนเองอย่างเต็มที่เพื่อใช้การให้เหตุผลบรรทัดคำสั่งหรือซอฟต์แวร์อื่น ๆ ทุกคนยินดีที่จะแนะนำ PR สำหรับโครงการนี้
โครงการอื่น ๆ ของผู้แต่ง: Aitoolkits
หากคุณต้องการเข้าร่วมในการพัฒนาคุณสามารถเข้าร่วมกลุ่ม QQ: 263805400 หรือเพิ่ม PR โดยตรง
แบบจำลองจะต้องถูกแปลงเป็นโมเดล ONNX สำหรับรายละเอียดโปรดดูที่เก็บข้อมูลแหล่งที่มาของโครงการที่คุณเลือก โมเดล PTH ไม่สามารถใช้โดยตรง! - - - - - - - - - - - -
แต่ละสาขาของโครงการนี้:
XP Supremacists มีความสุขใครไม่ชอบ Dragon Girl?
ความตั้งใจดั้งเดิมของโครงการนี้คือการตระหนักถึงความจำเป็นในการสังเคราะห์เสียงต่าง ๆ โดยไม่จำเป็นต้องมีกระทรวงสิ่งแวดล้อมและตอนนี้มีการวางแผนที่จะทำในฐานะบรรณาธิการเสริมสำหรับ SVC
เนื่องจากโครงการนี้เป็นโครงการ "ส่วนตัว" และ "ไม่เป็นมืออาชีพ" หลังจากทั้งหมดคุณมีซอฟต์แวร์มืออาชีพมากขึ้นหรือคุณเป็นผู้ที่ชื่นชอบ Python CLI หรือคุณเป็นช็อตใหญ่ในสาขาที่เกี่ยวข้อง ฉันรู้ว่าซอฟต์แวร์นี้ไม่เป็นมืออาชีพและมีแนวโน้มที่จะไม่ตอบสนองความต้องการของคุณหรือแม้แต่ไร้ประโยชน์กับคุณ
โครงการนี้ไม่ใช่โครงการที่ไม่สามารถถูกแทนที่ได้ ในทางตรงกันข้ามคุณสามารถใช้เครื่องมือต่าง ๆ เพื่อแทนที่ฟังก์ชั่นของโครงการนี้ ฉันไม่คาดหวังว่าโครงการนี้จะเป็นโครงการชั้นนำในสาขาที่เกี่ยวข้อง ฉันเพิ่งพัฒนาโครงการด้วยความกระตือรือร้นต่อไป แต่ความกระตือรือร้นจะหายไปตลอดทั้งวัน แต่โครงการสัญญาว่าจะบำรุงรักษาจนกว่าความกระตือรือร้นของฉันจะหายไปอย่างสมบูรณ์ (ไม่ว่าใครจะใช้มันแม้ว่าจำนวนผู้ใช้จะเป็น 0)
อาจมีปัญหาต่าง ๆ ในการออกแบบโครงการนี้ดังนั้นทุกคนก็ต้องสั่งข้าวผัดอย่างแข็งขันเพื่อช่วยฉันปรับปรุงฟังก์ชั่น ฉันจะยอมรับการเพิ่มประสิทธิภาพของฟังก์ชั่นและประสบการณ์ส่วนใหญ่
โครงการนี้เป็นโอเพ่นซอร์สและฟรีตลอดไป หากมีรุ่นที่ชำระเงินของโครงการนี้ในสถานที่อื่นโปรดรายงานทันทีและไม่ซื้อ โครงการนี้ฟรีตลอดไป หากคุณต้องการเติมใบสีขาวด้วย Crazy Thursday คุณสามารถไปที่ Aifa Dian https://afdian.net/a/narusemioshirakana
มันไม่ได้ให้การฝึกอบรมแบบจำลองนั้นค่อนข้างง่ายและไม่จำเป็นต้องใช้จ่ายเงินอย่างไร้ประโยชน์ เพียงทำตามการสอนออนไลน์ทีละขั้นตอน
- ความคิดริเริ่ม สัดส่วนของสิ่งของของคุณเองทั่วทั้งโครงการ (สำหรับ AI การสร้างแบบจำลองที่ได้รับการฝึกฝนโดยคุณเป็นของคุณอย่างอิสระการสร้างแบบจำลองที่เป็นของคนอื่น ๆ ) แง่มุมที่ครอบคลุมรวมถึง แต่ไม่ จำกัด เฉพาะโปรแกรมศิลปะเสียงการวางแผน ฯลฯ ตัวอย่างเช่นการใช้ความสามัคคีและเทมเพลตเครื่องยนต์อื่น ๆ เพื่อแทนที่สกินคือของเสียอิเล็กทรอนิกส์
- ทัศนคติของนักพัฒนา ทัศนคติของผู้เขียนคือการทำเงินและออกไปหรือไร้ประโยชน์ ตัวอย่างเช่นฉันได้ตีแท็กนับไม่ถ้วนเช่น "ในประเทศ", "First", "แข็งแกร่งที่สุด" และ "โฮมเมด" ซึ่งส่งผลให้สิ่งที่แย่มากหรือปานกลางและผู้เขียนเห็นได้ชัดว่าไม่มีความคิดที่จะทำให้โครงการดีซึ่งเป็นของเสียทางอิเล็กทรอนิกส์
- คัดค้านพฤติกรรมการค้าทั้งหมดของโมเดล AI ที่ผ่านการฝึกอบรมโดยใช้ชุดข้อมูลที่ไม่ได้รับอนุญาต
หากคุณสามารถมั่นใจได้ว่าสิ่งที่คุณกำลังทำไม่ใช่ขยะอิเล็กทรอนิกส์ แต่ถูกกฎหมายและเป็นไปตามข้อกำหนดและไม่มีข้อผิดพลาดทางการเมืองที่ร้ายแรงฉันจะให้การสนับสนุนทางเทคนิคภายในความสามารถของฉัน
ไม่รองรับเส้นทางจีน? ในความเป็นจริงโครงการอภิปรัชญาสนับสนุนเส้นทางจีน แต่รุ่นของ OnnxRuntime ก่อนเดือนมีนาคม 2566 ไม่สนับสนุนเส้นทางจีนเนื่องจากเวอร์ชันของ OnnxRuntime ใช้ฟังก์ชั่น A-Series ของ Win32API และฟังก์ชั่น A-Series ไม่สนับสนุนเส้นทางที่ไม่ได้เข้ารหัส ปัญหานี้ไม่ใช่สิ่งที่ฉันสามารถแก้ไขได้หรือฉันควรแก้ปัญหา มีเพียง Microsoft เท่านั้นที่สามารถแก้ไขข้อผิดพลาดนี้ได้ โชคดีที่ onnxruntime ล่าสุดใช้ฟังก์ชั่น W Series เพื่อแก้ปัญหาเส้นทางจีน
เนื่องจากความเข้ากันได้ไม่ดีของ CUDA โปรแกรมที่ใช้ CUDA จะต้องติดตั้งและรวบรวมเมื่อติดตั้งและรวบรวมโปรแกรมหรือ CUDA เวอร์ชันล่าสุดยังไม่ได้รับการแก้ไข ปัญหานี้สามารถรอให้ Nvidia ให้ความสนใจกับความเข้ากันได้
Moevoicestudiocore ให้การโทรในภาษา C ++ ในรูปแบบของ LIB
อ้างอิงคลาสที่เกี่ยวข้องต่อไปนี้ตามต้องการ
# include < Modules/Models/header/Tacotron.hpp >
# include < Modules/Models/header/Vits.hpp >
# include < Modules/Models/header/VitsSvc.hpp >
# include < Modules/Models/header/DiffSvc.hpp >
# include < Modules/Models/header/DiffSinger.hpp >
InferClass::Tacotron2;
InferClass::Vits;
InferClass::VitsSvc;
InferClass::DiffusionSvc;
InferClass::DiffusionSinger;
/*
构造函数第一个是配置文件json
第二个是进度条回调
第三个是参数回调 (若为TTS 此参数为空即可)
第四个参数为设备
使用调用Inference函数即可
*/สำหรับการกำหนดค่ารุ่นโปรดดูการกำหนดค่า #Model
ตัวอย่าง: ตัวอย่างบรรทัดคำสั่ง RVC
หยุดการอัปเดต (เนื่องจากการดาวน์โหลดและอัปโหลดความเร็ว): Vocoder & Hiddenunitbert
หยุดอัปเดต (เพราะ HuggingFace เป็นที่กำแพง): HuggingFace
คลังสินค้าล่าสุด: Openi
ส่งออกที่ตั้งไว้ด้วยตัวเอง:
input_names ควรเป็น ["source"] , output_names ควรเป็น ["embed"] , dynamic_axes ควรเป็น {"source":[0,2],}input_names ควรเป็น ["c","f0"] , output_names ควรเป็น ["audio"] , dynamic_axes ควรเป็น {"c":[0,1],"f0":[0,1],}input_names ควรเป็น ["x"] , output_names ควรเป็น ["audio"] , dynamic_axes ควรเป็น {"x":[0,1],}รุ่น VEC และโมเดล Hubert ถูกวางไว้ในโฟลเดอร์ Hubert และรุ่น Hifigan ถูกวางไว้ในโฟลเดอร์ Hifigan หากคุณต้องการใช้ตัวทำนาย F0 สองตัวคือ FCPE หรือ RMVPE คุณต้องสร้างโฟลเดอร์ F0Predictor ในไดเรกทอรีรูทและวางโมเดล ONNX ไว้ในนั้น
xxx.json เป็นไฟล์กำหนดค่าสำหรับรุ่น มันจะต้องเขียนตามเทมเพลตด้วยตัวคุณเองและในเวลาเดียวกันก็จำเป็นต้องแปลงโมเดลเป็น ONNX ด้วยตัวคุณเอง Folder : บันทึกชื่อโฟลเดอร์ของรุ่นName : ชื่อที่แสดงของโมเดลใน UIType : หมวดหมู่รุ่นRate : อัตราการสุ่มตัวอย่าง (จะต้องเหมือนกับเมื่อคุณฝึกอบรมถ้าคุณไม่เข้าใจเหตุผลขอแนะนำให้เรียนรู้ความรู้เกี่ยวกับเสียงคอมพิวเตอร์) {
"Folder" : "Atri" ,
"Name" : "亚托莉-Tacotron2" ,
"Type" : "Tacotron2" ,
"Rate" : 22050 ,
"Symbol" : "_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" ,
"Cleaner" : "" ,
"AddBlank" : false ,
"Hifigan" : "hifigan"
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Tacotron2中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的hifigan放置到hifigan文件夹
//AddBlank:是否在音素之间插0作为分隔 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Vits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Vits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Pits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Pits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "NyaruTaffy" ,
"Name" : "NyaruTaffy" ,
"Type" : "RVC" ,
"Rate" : 40000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"SoVits2" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"HiddenSize" : 256 ,
"Cluster" : "Index"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 32000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 48000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"SoVits4.0V2" : false ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件)
//SoVits4.0V2: 是否为SoVits4.0V2模型 {
"Folder" : "DiffShiroha" ,
"Name" : "白羽" ,
"Type" : "DiffSvc" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"MelBins" : 128 ,
"Cleaner" : "" ,
"Hifigan" : "nsf_hifigan" ,
"Hubert" : "hubert" ,
"Characters" : [ ] ,
"Pndm" : 100 ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"V2" : true
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Pndm:加速倍数,如果是V1模型则必填且必须为导出时设置的加速倍率
//V2:是否为V2模型,V2模型就是后来我分4个模块导出的那个
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256) {
"Folder" : "utagoe" ,
"Name" : "utagoe" ,
"Type" : "DiffSinger" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hifigan" : "singer_nsf_hifigan" ,
"Characters" : [ ] ,
"MelBins" : 128
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的singer_nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到) {
"Folder" : "HimenoSena" ,
"Name" : "HimenoSena" ,
"Type" : "BertVits" ,
"Symbol" : [
"_" ,
"AA" ,
"E" ,
"EE" ,
"En" ,
"N" ,
"OO" ,
"V" ,
"a" ,
"a:" ,
"aa" ,
"ae" ,
"ah" ,
"ai" ,
"an" ,
"ang" ,
"ao" ,
"aw" ,
"ay" ,
"b" ,
"by" ,
"c" ,
"ch" ,
"d" ,
"dh" ,
"dy" ,
"e" ,
"e:" ,
"eh" ,
"ei" ,
"en" ,
"eng" ,
"er" ,
"ey" ,
"f" ,
"g" ,
"gy" ,
"h" ,
"hh" ,
"hy" ,
"i" ,
"i0" ,
"i:" ,
"ia" ,
"ian" ,
"iang" ,
"iao" ,
"ie" ,
"ih" ,
"in" ,
"ing" ,
"iong" ,
"ir" ,
"iu" ,
"iy" ,
"j" ,
"jh" ,
"k" ,
"ky" ,
"l" ,
"m" ,
"my" ,
"n" ,
"ng" ,
"ny" ,
"o" ,
"o:" ,
"ong" ,
"ou" ,
"ow" ,
"oy" ,
"p" ,
"py" ,
"q" ,
"r" ,
"ry" ,
"s" ,
"sh" ,
"t" ,
"th" ,
"ts" ,
"ty" ,
"u" ,
"u:" ,
"ua" ,
"uai" ,
"uan" ,
"uang" ,
"uh" ,
"ui" ,
"un" ,
"uo" ,
"uw" ,
"v" ,
"van" ,
"ve" ,
"vn" ,
"w" ,
"x" ,
"y" ,
"z" ,
"zh" ,
"zy" ,
"!" ,
"?" ,
"u2026" ,
"," ,
"." ,
"'" ,
"-" ,
"SP" ,
"UNK"
] ,
"Cleaner" : "" ,
"Rate" : 44100 ,
"CharaMix" : true ,
"Characters" : [
"u56fdu89c1u83dcu5b50" ,
"u59ecu91ceu661fu594f" ,
"u65b0u5802u5f69u97f3" ,
"u56dbu6761u51dbu9999" ,
"u5c0fu97a0u7531u4f9d"
] ,
"LanguageMap" : {
"ZH" : [
0 ,
0
] ,
"JP" : [
1 ,
6
] ,
"EN" : [
2 ,
8
]
} ,
"Dict" : "BasicDict" ,
"BertPath" : [
"chinese-roberta-wwm-ext-large" ,
"deberta-v2-large-japanese" ,
"bert-base-japanese-v3"
]
} // ${xxx}是什么意思大家应该都知道吧,总之以下是多个不同项目需要的模型文件(需要放置在对应的模型文件夹下)。
// Tacotron2:
${Folder} _decoder_iter.onnx
${Folder} _encoder.onnx
${Folder} _postnet.onnx
// Vits: 单角色VITS
${Folder} _dec.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// Vits: 多角色VITS
${Folder} _dec.onnx
${Folder} _emb.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// SoVits:
${Folder} _SoVits.onnx
// RVC:
${Folder} _RVC.onnx
// DiffSvc:
${Folder} _diffSvc.onnx
// DiffSvc: V2
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
${Folder} _after.onnx
// DiffSinger: OpenVpiVersion
${Folder} _diffSinger.onnx
// DiffSinger:
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
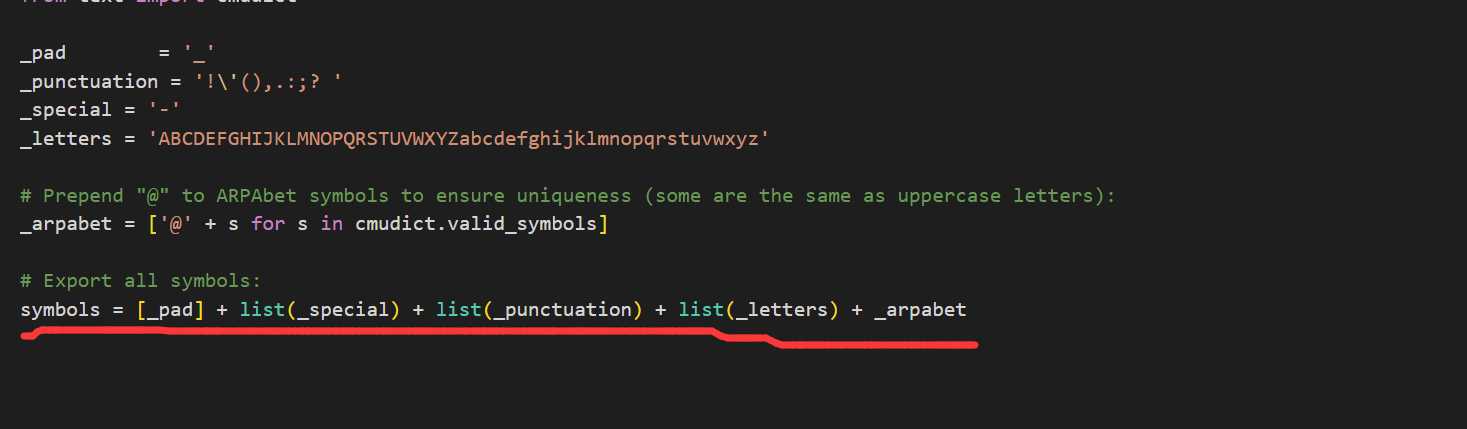
${Folder} _after.onnx例如:_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
打开你训练模型的项目,打开textsymbol.py,如图按照划线的List顺序将上面的4个字符串连接即可
/*
Cleaner请放置于根目录的Cleaners文件夹内,应该是一个按照要求定义的动态库(.dll),dll应当命名为Cleaner名,Cleaner名即为模型定义Json文件中Cleaner一栏填写的内容。
所有的插件dll需要定义以下函数,函数名必须为PluginMain,Dll名必须为插件名(或Cleaner名):
*/
const wchar_t * PluginMain ( const wchar_t *);
// 该接口只要求输入输出一致,并不要求功能一致,也就是说,你可以在改Dll中实现任何想要的功能,比方说ChatGpt,机器翻译等等。
// 以ChatGpt为例,PluginMain函数传入了一个输入字符串input,将该输入传入ChatGpt,再将ChatGpt的输出传入PluginMain,最后返回输出。
wchar_t * PluginMain ( wchar_t * input){
wchar_t * tmpOutput = ChatGpt (input);
return Clean (tmpOutput);
}
// 注意:导出dll时请使用 extern "C" 关键字来防止C++语言的破坏性命名。 git clone https: // github.com/NaruseMioShirakana/MoeVoiceStudio.git
//自行配置OnnxRuntime和FFMPEG的Dll
//使用VisualStudio构建ไม่มีองค์กรหรือบุคคลใดที่อาจละเมิดสิทธิภาพบุคคลของผู้อื่นโดยการกล่าวโทษการหมิ่นประมาทหรือการใช้เทคโนโลยีสารสนเทศเพื่อปลอมแปลงพวกเขา ภาพบุคคลของผู้ถือขวาแนวตั้งจะไม่ถูกสร้างใช้หรือเปิดเผยโดยไม่ได้รับความยินยอมจากผู้ถือภาพบุคคลยกเว้นตามที่กฎหมายกำหนดไว้เป็นอย่างอื่น โดยไม่ได้รับความยินยอมจากผู้ถือภาพบุคคลที่ถูกต้องผู้ถือที่ถูกต้องของงานภาพบุคคลจะไม่ใช้หรือเปิดเผยภาพบุคคลของผู้ถือภาพบุคคลโดยการเผยแพร่การคัดลอกการออกการให้เช่าการจัดนิทรรศการ ฯลฯ การคุ้มครองเสียงของบุคคลธรรมดาจะต้องอยู่ภายใต้บทบัญญัติที่เกี่ยวข้องเกี่ยวกับการคุ้มครองสิทธิ
[ชื่อเสียงที่ถูกต้อง] วิชาโยธาได้รับสิทธิชื่อเสียง ไม่มีองค์กรหรือบุคคลใดที่จะละเมิดสิทธิชื่อเสียงของผู้อื่นโดยการดูถูกการใส่ร้ายหรือวิธีการอื่น ๆ
[งานละเมิดสิทธิชื่อเสียง] หากงานวรรณกรรมและศิลปะที่ตีพิมพ์โดยผู้กระทำความผิดนั้นถูกอธิบายโดยคนจริงหรือคนที่เฉพาะเจาะจงและมีเนื้อหาที่ดูถูกเหยียดหยามหรือใส่ร้ายซึ่งละเมิดสิทธิชื่อเสียงของผู้อื่นเหยื่อมีสิทธิ์ที่จะขอให้ผู้กระทำความผิดต้องรับผิดชอบ งานวรรณกรรมและศิลปะที่ตีพิมพ์โดยผู้กระทำความผิดไม่ได้อธิบายคนที่เฉพาะเจาะจงว่าเป็นวัตถุประสงค์ของคำอธิบายและเฉพาะในกรณีที่แปลงนั้นคล้ายกับสถานการณ์ของบุคคลที่เฉพาะเจาะจงพวกเขาจะไม่รับผิดชอบต่อความรับผิดทางแพ่ง
วัสดุภาพที่ Moess ใช้มาจาก:
เกณฑ์สำหรับการตัดสินรายได้ต่ำคือ: เนื้อหาใด ๆ ที่สร้างขึ้นโดยใช้ AI จำนวนมากเนื้อหาต้นฉบับต่ำความหมายไม่ทราบเนื้อหามีคุณภาพต่ำ ฯลฯ ↩
เกณฑ์การตัดสิน E-SPAM: 1. ความคิดริเริ่ม สัดส่วนของสิ่งของของคุณเองทั่วทั้งโครงการ (สำหรับ AI การสร้างแบบจำลองที่ได้รับการฝึกฝนโดยคุณเป็นของคุณอย่างอิสระการสร้างแบบจำลองที่เป็นของคนอื่น ๆ ) แง่มุมที่ครอบคลุมรวมถึง แต่ไม่ จำกัด เฉพาะโปรแกรมศิลปะเสียงการวางแผน ฯลฯ ตัวอย่างเช่นการใช้ความสามัคคีและเทมเพลตเครื่องยนต์อื่น ๆ เพื่อแทนที่สกินคือของเสียอิเล็กทรอนิกส์


