DragonianVoice
ve api

Chinese | English
This repository has permanently stopped maintaining the UI project and will become a pure Lib project. The code repository address is: DragonianLib, but the Release about SVC and TTS is still released in this repository.
This repository is: 1. TTS (Tacotron2, Vits, EmotionalVits, BERTVits2, GPtSoVits); 2. SVC (SoVitsSvc, RVC, DiffusionSvc, FishDiffusion, ReflowSvc); 3. SVS (DiffSinger) Onnx framework reasoning repository, currently supports C/Cpp/C# calls.
The latest version of this repository has been linked to fish-speech, and uses the ggml framework to rewrite fish-speech to form the fish-speech.cpp subproject
Note: SVS-enabled branch: MoeVoiceStudio MoeVoiceStudioCore
Regarding Cuda support, please visit the OnnxRuntime official repository.
After experiments, Dml will cause some unsupported operators in Onnx to not report errors when used, but will return an unexpected result, which will lead to errors in the inference results of SoVits3.0 and SoVits4.0 on DmlEP. However, the Onnx export in the latest SoVits repository has replaced these operators, so SoVits3.0 and SoVits4.0 recovery support Dml use, but the Onnx model must be re-exported using the latest (2023/7/17) version of SoVitsOnnx export
Due to the characteristics of Diffusion and Reflow models, if the total number of steps you infer is greater than the maximum number of steps you trained in the model (actual number of steps = total number of steps/acceleration magnification, this total number of steps is not the actual number of steps you took during inference, but K_Step), which will cause the output audio to explode or cause very high noise. Therefore, it is recommended that you carefully observe the MaxStep (or K_Step_Max) in your model configuration file before inference.
This project is an open source and offline project, and all developers and maintainers of this project (hereinafter referred to as contributors) have no control over this project . Contributors of this project have never provided any organization or individual with any help in all forms including but not limited to data set extraction, data set processing, computing power support, training support, reasoning, etc.; contributors of this project do not know or know the purpose of the user using the project. Therefore, all audio synthesized based on this project has nothing to do with the contributors of this project. All problems caused by this are at the user's own responsibility .
This project itself does not have any function of speech synthesis, but is only used to start the user's own training and production of the Onnx model. The model training and the production of the Onnx model are not related to the contributors of this project, and are all the users' own behaviors. The contributors of this project have not participated in the model training and production of all users.
This project is run completely offline and cannot collect any user information and cannot obtain user input data. Therefore, the contributors of this project are not aware of all user inputs and models, so they are not responsible for any user input.
This project also does not come with any model, and any model included with the secondary release and the model used for this project have nothing to do with the developer of this project.
This project currently fully supports calling its own methods to implement command line reasoning or other software. Everyone is welcome to recommend PR to this project
Author's other projects: AiToolKits
If you want to participate in the development, you can join the QQ group: 263805400 or directly add PR
The model needs to be converted to an ONNX model. For details, see the source repository of the project you selected. The PTH model cannot be used directly! ! ! ! ! ! ! ! ! ! ! ! !
Each branch of this project:
XP supremacists are ecstatic, who doesn't like Dragon Girl?
The original intention of this project was to realize the need for various voice synthesis projects without the need for the Ministry of Environment, and now it is planned to be made as an auxiliary editor for SVC.
Since this project is a "personal" and "unprofessional" project after all, you have more professional software, or you are a Python Cli enthusiast, or you are a big shot in the related field. I know that this software is not professional enough and is likely to not meet your needs or even useless to you.
This project is not an irreplaceable project. On the contrary, you can use various tools to replace the functions of this project. I do not expect this project to become a leading project in related fields. I just continue to develop the project with enthusiasm. But enthusiasm will always disappear for a day, but the project promises to keep maintenance until my enthusiasm completely disappears (regardless of whether anyone uses it, even if the number of users is 0)
There may be various problems in the design of this project, so everyone also needs to actively order fried rice to help me improve the functions. I will accept most of the optimization of functions and experience.
This project is open source and free forever. If there is a paid version of this project in other places, please report it immediately and do not purchase it. This project is free forever. If you want to fill the white leaves with Crazy Thursday, you can go to Aifa Dian https://afdian.net/a/NaruseMioShirakana
It is not provided, training the model is relatively simple, and there is no need to spend money in vain. Just follow the online tutorial step by step.
- Originality. The proportion of your own stuff throughout the project (for AI, the creation of using models that are entirely trained by you independently belongs to you; the creation of using models that are others belongs to others). The aspects covered include but are not limited to programs, art, audio, planning, etc. For example, applying Unity and other engine templates to replace skins is electronic waste.
- Developer attitude. The author's attitude is to make money and leave or be simply vain. For example, I have hit countless tags, such as "domestic", "first", "strongest" and "homemade", which resulted in very bad or mediocre things, and the author obviously has no idea of making the project well, which is electronic waste.
- Oppose all commercial behaviors of AI models trained using unauthorized data sets.
If you can be sure that what you are doing is not electronic waste, but is legal and compliant, and there are no serious political mistakes, I will provide some technical support within my ability.
Chinese path is not supported? In fact, the project ontology supports Chinese paths, but the version of OnnxRuntime before March 2023 does not support Chinese paths, because these versions of OnnxRuntime use Win32Api's A-series functions, and A-series functions do not support non-ANSI-encoded paths. This problem is not something I can solve or should I solve. Only Microsoft can fix this bug. Fortunately, the latest OnnxRuntime uses W series functions to solve the Chinese path problem.
Due to the extremely poor compatibility of Cuda, a Cuda-based program must be installed and compiled when installing and compiling the program, or the latest version of Cuda has not been modified. This problem can only be waited for Nvidia to pay attention to compatibility.
MoeVoiceStudioCore provides calls in C++ language in the form of Lib
Reference the following corresponding classes as needed
# include < Modules/Models/header/Tacotron.hpp >
# include < Modules/Models/header/Vits.hpp >
# include < Modules/Models/header/VitsSvc.hpp >
# include < Modules/Models/header/DiffSvc.hpp >
# include < Modules/Models/header/DiffSinger.hpp >
InferClass::Tacotron2;
InferClass::Vits;
InferClass::VitsSvc;
InferClass::DiffusionSvc;
InferClass::DiffusionSinger;
/*
构造函数第一个是配置文件json
第二个是进度条回调
第三个是参数回调 (若为TTS 此参数为空即可)
第四个参数为设备
使用调用Inference函数即可
*/For model configuration, please refer to #Model Configuration
demo: RVC command line example
Stop updates (due to download and upload speed): Vocoder & HiddenUnitBert
Stop update (because HuggingFace is walled): HuggingFace
Latest warehouse: Openi
Export the preset yourself:
input_names should be ["source"] , output_names should be ["embed"] , dynamic_axes should be {"source":[0,2],}input_names should be ["c","f0"] , output_names should be ["audio"] , dynamic_axes should be {"c":[0,1],"f0":[0,1],}input_names should be ["x"] , output_names should be ["audio"] , dynamic_axes should be {"x":[0,1],}Vec model and Hubert model are placed in the Hubert folder, and Hifigan model is placed in the Hifigan folder. If you need to use the two F0 predictors, FCPE or RMVPE, you need to create the F0Predictor folder in the root directory and place the onnx model in it.
xxx.json is a configuration file for the model. It needs to be written according to the template yourself, and at the same time, it needs to convert the model to Onnx yourself. Folder : Save the folder name of the modelName : The display name of the model in the UIType : Model CategoryRate : The sampling rate (it must be exactly the same as when you were training. If you don’t understand the reason, it is recommended to learn computer audio-related knowledge) {
"Folder" : "Atri" ,
"Name" : "亚托莉-Tacotron2" ,
"Type" : "Tacotron2" ,
"Rate" : 22050 ,
"Symbol" : "_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" ,
"Cleaner" : "" ,
"AddBlank" : false ,
"Hifigan" : "hifigan"
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Tacotron2中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的hifigan放置到hifigan文件夹
//AddBlank:是否在音素之间插0作为分隔 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Vits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Vits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Pits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Pits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "NyaruTaffy" ,
"Name" : "NyaruTaffy" ,
"Type" : "RVC" ,
"Rate" : 40000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"SoVits2" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"HiddenSize" : 256 ,
"Cluster" : "Index"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 32000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 48000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"SoVits4.0V2" : false ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件)
//SoVits4.0V2: 是否为SoVits4.0V2模型 {
"Folder" : "DiffShiroha" ,
"Name" : "白羽" ,
"Type" : "DiffSvc" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"MelBins" : 128 ,
"Cleaner" : "" ,
"Hifigan" : "nsf_hifigan" ,
"Hubert" : "hubert" ,
"Characters" : [ ] ,
"Pndm" : 100 ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"V2" : true
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Pndm:加速倍数,如果是V1模型则必填且必须为导出时设置的加速倍率
//V2:是否为V2模型,V2模型就是后来我分4个模块导出的那个
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256) {
"Folder" : "utagoe" ,
"Name" : "utagoe" ,
"Type" : "DiffSinger" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hifigan" : "singer_nsf_hifigan" ,
"Characters" : [ ] ,
"MelBins" : 128
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的singer_nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到) {
"Folder" : "HimenoSena" ,
"Name" : "HimenoSena" ,
"Type" : "BertVits" ,
"Symbol" : [
"_" ,
"AA" ,
"E" ,
"EE" ,
"En" ,
"N" ,
"OO" ,
"V" ,
"a" ,
"a:" ,
"aa" ,
"ae" ,
"ah" ,
"ai" ,
"an" ,
"ang" ,
"ao" ,
"aw" ,
"ay" ,
"b" ,
"by" ,
"c" ,
"ch" ,
"d" ,
"dh" ,
"dy" ,
"e" ,
"e:" ,
"eh" ,
"ei" ,
"en" ,
"eng" ,
"er" ,
"ey" ,
"f" ,
"g" ,
"gy" ,
"h" ,
"hh" ,
"hy" ,
"i" ,
"i0" ,
"i:" ,
"ia" ,
"ian" ,
"iang" ,
"iao" ,
"ie" ,
"ih" ,
"in" ,
"ing" ,
"iong" ,
"ir" ,
"iu" ,
"iy" ,
"j" ,
"jh" ,
"k" ,
"ky" ,
"l" ,
"m" ,
"my" ,
"n" ,
"ng" ,
"ny" ,
"o" ,
"o:" ,
"ong" ,
"ou" ,
"ow" ,
"oy" ,
"p" ,
"py" ,
"q" ,
"r" ,
"ry" ,
"s" ,
"sh" ,
"t" ,
"th" ,
"ts" ,
"ty" ,
"u" ,
"u:" ,
"ua" ,
"uai" ,
"uan" ,
"uang" ,
"uh" ,
"ui" ,
"un" ,
"uo" ,
"uw" ,
"v" ,
"van" ,
"ve" ,
"vn" ,
"w" ,
"x" ,
"y" ,
"z" ,
"zh" ,
"zy" ,
"!" ,
"?" ,
"u2026" ,
"," ,
"." ,
"'" ,
"-" ,
"SP" ,
"UNK"
] ,
"Cleaner" : "" ,
"Rate" : 44100 ,
"CharaMix" : true ,
"Characters" : [
"u56fdu89c1u83dcu5b50" ,
"u59ecu91ceu661fu594f" ,
"u65b0u5802u5f69u97f3" ,
"u56dbu6761u51dbu9999" ,
"u5c0fu97a0u7531u4f9d"
] ,
"LanguageMap" : {
"ZH" : [
0 ,
0
] ,
"JP" : [
1 ,
6
] ,
"EN" : [
2 ,
8
]
} ,
"Dict" : "BasicDict" ,
"BertPath" : [
"chinese-roberta-wwm-ext-large" ,
"deberta-v2-large-japanese" ,
"bert-base-japanese-v3"
]
} // ${xxx}是什么意思大家应该都知道吧,总之以下是多个不同项目需要的模型文件(需要放置在对应的模型文件夹下)。
// Tacotron2:
${Folder} _decoder_iter.onnx
${Folder} _encoder.onnx
${Folder} _postnet.onnx
// Vits: 单角色VITS
${Folder} _dec.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// Vits: 多角色VITS
${Folder} _dec.onnx
${Folder} _emb.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// SoVits:
${Folder} _SoVits.onnx
// RVC:
${Folder} _RVC.onnx
// DiffSvc:
${Folder} _diffSvc.onnx
// DiffSvc: V2
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
${Folder} _after.onnx
// DiffSinger: OpenVpiVersion
${Folder} _diffSinger.onnx
// DiffSinger:
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
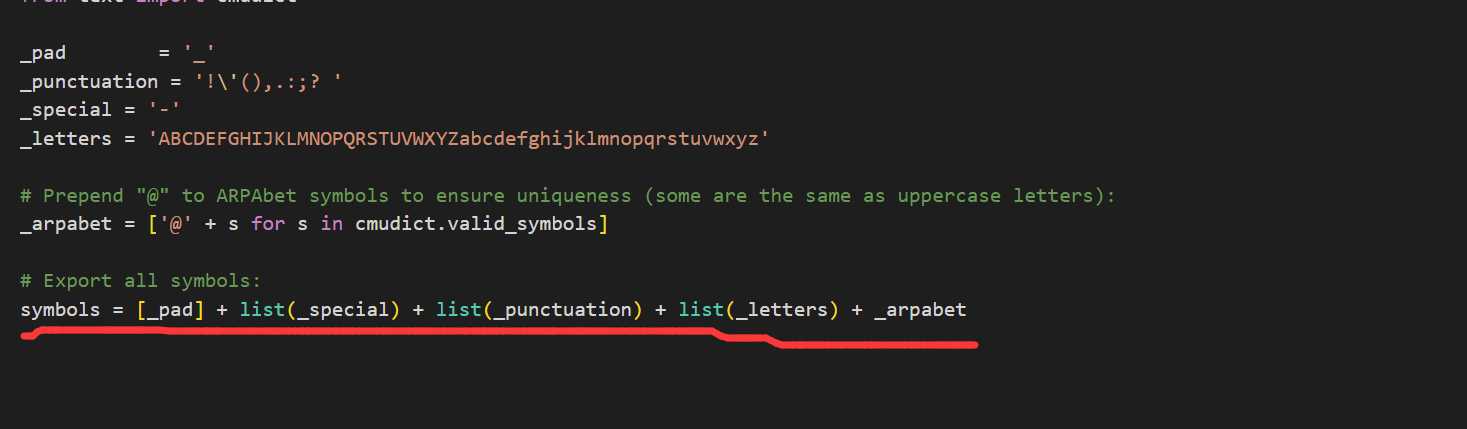
${Folder} _after.onnx例如:_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
打开你训练模型的项目,打开textsymbol.py,如图按照划线的List顺序将上面的4个字符串连接即可
/*
Cleaner请放置于根目录的Cleaners文件夹内,应该是一个按照要求定义的动态库(.dll),dll应当命名为Cleaner名,Cleaner名即为模型定义Json文件中Cleaner一栏填写的内容。
所有的插件dll需要定义以下函数,函数名必须为PluginMain,Dll名必须为插件名(或Cleaner名):
*/
const wchar_t * PluginMain ( const wchar_t *);
// 该接口只要求输入输出一致,并不要求功能一致,也就是说,你可以在改Dll中实现任何想要的功能,比方说ChatGpt,机器翻译等等。
// 以ChatGpt为例,PluginMain函数传入了一个输入字符串input,将该输入传入ChatGpt,再将ChatGpt的输出传入PluginMain,最后返回输出。
wchar_t * PluginMain ( wchar_t * input){
wchar_t * tmpOutput = ChatGpt (input);
return Clean (tmpOutput);
}
// 注意:导出dll时请使用 extern "C" 关键字来防止C++语言的破坏性命名。 git clone https: // github.com/NaruseMioShirakana/MoeVoiceStudio.git
//自行配置OnnxRuntime和FFMPEG的Dll
//使用VisualStudio构建No organization or individual may infringe on the portrait rights of others by vilifying, defaming, or using information technology to forge them. The portrait of the portrait right holder shall not be produced, used or disclosed without the consent of the portrait right holder, except as otherwise provided by law. Without the consent of the portrait right holder, the right holder of the portrait work shall not use or disclose the portrait right holder's portrait by publishing, copying, issuing, renting, exhibition, etc. The protection of natural person's voices shall be subject to the relevant provisions on the protection of portrait rights.
[Reputation Right] Civil subjects enjoy the right to reputation. No organization or individual may infringe on the reputation rights of others by insulting, slandering, or other means.
[Works infringe on reputation rights] If the literary and artistic works published by the perpetrator are described by real people or specific people, and contain insulting or slandering content, which infringes on the reputation rights of others, the victim has the right to request the perpetrator to bear civil liability in accordance with the law. The literary and artistic works published by the perpetrator do not describe a specific person as the object of description, and only if the plots are similar to the situation of the specific person, they shall not bear civil liability.
The image materials used by MoeSS are derived from:
The criteria for judging low-income are: any content generated by using a lot of AI, the original content is low, the meaning is unknown, the content is of low quality, etc. ↩
E-spam judgment criteria: 1. Originality. The proportion of your own stuff throughout the project (for AI, the creation of using models that are entirely trained by you independently belongs to you; the creation of using models that are others belongs to others). The aspects covered include but are not limited to programs, art, audio, planning, etc. For example, applying Unity and other engine templates to replace skins is electronic waste. ↩


