DragonianVoice
ve api

Cina | Bahasa inggris
Repositori ini secara permanen berhenti mempertahankan proyek UI dan akan menjadi proyek Lib murni. Alamat Repositori Kode adalah: Dragonianlib, tetapi rilis tentang SVC dan TTS masih dirilis di repositori ini.
Repositori ini adalah: 1. TTS (TACOTRON2, VITS, EMOMICALVITS, BERTVITS2, GPTSOVITS); 2. SVC (SovitsSVC, RVC, DiffusionsVC, FishDiffusion, ReflowsVC); 3. SVS (Diffsinger) ONNX Framework Reasoning Repository, saat ini mendukung panggilan C/CPP/C#.
Versi terbaru dari repositori ini telah dikaitkan dengan pidato ikan, dan menggunakan kerangka kerja GGML untuk menulis ulang pidato ikan untuk membentuk subproyek fish-speech.cpp
Catatan: Cabang yang diaktifkan SVS: Moevoicestudio Moevoicestudiocore
Mengenai dukungan CUDA, silakan kunjungi repositori resmi Onnxruntime.
Setelah percobaan, DML akan menyebabkan beberapa operator yang tidak didukung di ONNX tidak melaporkan kesalahan saat digunakan, tetapi akan mengembalikan hasil yang tidak terduga, yang akan menyebabkan kesalahan dalam hasil inferensi Sovits3.0 dan Sovits4.0 pada DMLEP. Namun, ekspor ONNX dalam repositori SOVITS terbaru telah menggantikan operator ini, sehingga Sovits3.0 dan Sovits4.0 mendukung penggunaan DML, tetapi model ONNX harus diekspor kembali menggunakan versi SovitsonNX versi terbaru (2023/7/7/7)
Karena karakteristik model difusi dan reflow, jika jumlah total langkah yang Anda simpulkan lebih besar dari jumlah maksimum langkah yang Anda latih dalam model (jumlah aktual langkah = jumlah total langkah/perbesaran akselerasi, jumlah total langkah ini bukan jumlah langkah aktual yang Anda ambil selama inferensi, tetapi k_step), yang akan menyebabkan audio output untuk mengeksplode atau penyebab suara tinggi. Oleh karena itu, Anda disarankan untuk mengamati maxStep (atau k_step_max) dengan cermat dalam file konfigurasi model Anda sebelum inferensi.
Proyek ini adalah proyek open source dan offline, dan semua pengembang dan pengelola proyek ini (selanjutnya disebut sebagai kontributor) tidak memiliki kendali atas proyek ini . Kontributor proyek ini tidak pernah memberikan organisasi atau individu dengan bantuan apa pun dalam semua bentuk termasuk tetapi tidak terbatas pada ekstraksi set data, pemrosesan kumpulan data, dukungan daya komputasi, dukungan pelatihan, penalaran, dll.; Kontributor proyek ini tidak tahu atau mengetahui tujuan pengguna menggunakan proyek. Oleh karena itu, semua audio disintesis berdasarkan proyek ini tidak ada hubungannya dengan kontributor proyek ini. Semua masalah yang disebabkan oleh hal ini adalah tanggung jawab pengguna sendiri .
Proyek ini sendiri tidak memiliki fungsi sintesis wicara, tetapi hanya digunakan untuk memulai pelatihan dan produksi model ONNX pengguna sendiri. Pelatihan model dan produksi model ONNX tidak terkait dengan kontributor proyek ini, dan merupakan semua perilaku pengguna sendiri. Kontributor proyek ini belum berpartisipasi dalam pelatihan model dan produksi semua pengguna.
Proyek ini dijalankan sepenuhnya offline dan tidak dapat mengumpulkan informasi pengguna apa pun dan tidak dapat memperoleh data input pengguna. Oleh karena itu, kontributor proyek ini tidak mengetahui semua input dan model pengguna, sehingga mereka tidak bertanggung jawab atas input pengguna apa pun.
Proyek ini juga tidak datang dengan model apa pun, dan model apa pun yang disertakan dengan rilis sekunder dan model yang digunakan untuk proyek ini tidak ada hubungannya dengan pengembang proyek ini.
Proyek ini saat ini sepenuhnya mendukung panggilan metodenya sendiri untuk mengimplementasikan penalaran baris perintah atau perangkat lunak lainnya. Setiap orang dipersilakan untuk merekomendasikan PR ke proyek ini
Proyek Penulis Lainnya: Aitoolkits
Jika Anda ingin berpartisipasi dalam pengembangan, Anda dapat bergabung dengan grup QQ: 263805400 atau langsung menambahkan PR
Model perlu dikonversi ke model ONNX. Untuk detailnya, lihat repositori sumber proyek yang Anda pilih. Model PTH tidak dapat digunakan secara langsung! Lai Lai Lai Lai Lai Lai Lai Lai Lai Lai Lai Lai
Setiap cabang proyek ini:
Supremasi XP sangat gembira, siapa yang tidak suka Naga Gadis?
Tujuan asli dari proyek ini adalah untuk menyadari perlunya berbagai proyek sintesis suara tanpa perlu Kementerian Lingkungan Hidup, dan sekarang direncanakan akan dibuat sebagai editor tambahan untuk SVC.
Karena proyek ini adalah proyek "pribadi" dan "tidak profesional", Anda memiliki perangkat lunak yang lebih profesional, atau Anda adalah penggemar Python CLI, atau Anda adalah bidikan besar di bidang terkait. Saya tahu bahwa perangkat lunak ini tidak cukup profesional dan cenderung tidak memenuhi kebutuhan Anda atau bahkan tidak berguna bagi Anda.
Proyek ini bukan proyek yang tak tergantikan. Sebaliknya, Anda dapat menggunakan berbagai alat untuk mengganti fungsi proyek ini. Saya tidak berharap proyek ini menjadi proyek terkemuka di bidang terkait. Saya hanya terus mengembangkan proyek dengan antusias. Tetapi antusiasme akan selalu menghilang selama sehari, tetapi proyek ini berjanji untuk menjaga pemeliharaan sampai antusiasme saya benar -benar menghilang (terlepas dari apakah ada yang menggunakannya, bahkan jika jumlah pengguna adalah 0)
Mungkin ada berbagai masalah dalam desain proyek ini, sehingga setiap orang juga perlu secara aktif memesan nasi goreng untuk membantu saya meningkatkan fungsi. Saya akan menerima sebagian besar optimalisasi fungsi dan pengalaman.
Proyek ini adalah open source dan gratis selamanya. Jika ada versi berbayar dari proyek ini di tempat lain, silakan segera laporkan dan jangan membelinya. Proyek ini gratis selamanya. Jika Anda ingin mengisi daun putih dengan Kamis gila, Anda bisa pergi ke Aifa Dian https://afdian.net/a/narusemioshirakana
Tidak disediakan, pelatihan model ini relatif sederhana, dan tidak perlu menghabiskan uang dengan sia -sia. Cukup ikuti tutorial online langkah demi langkah.
- Keaslian. Proporsi barang -barang Anda sendiri di seluruh proyek (untuk AI, penciptaan menggunakan model yang sepenuhnya dilatih oleh Anda secara mandiri adalah milik Anda; penciptaan menggunakan model yang menjadi orang lain milik orang lain). Aspek yang dicakup termasuk tetapi tidak terbatas pada program, seni, audio, perencanaan, dll. Misalnya, menerapkan Unity dan templat mesin lainnya untuk menggantikan kulit adalah limbah elektronik.
- Sikap pengembang. Sikap penulis adalah menghasilkan uang dan pergi atau menjadi sia -sia. Sebagai contoh, saya telah mencapai tag yang tak terhitung jumlahnya, seperti "domestik", "pertama", "terkuat" dan "buatan sendiri", yang menghasilkan hal -hal yang sangat buruk atau biasa -biasa saja, dan penulis jelas tidak tahu membuat proyek dengan baik, yang merupakan limbah elektronik.
- Menentang semua perilaku komersial model AI yang dilatih menggunakan set data yang tidak sah.
Jika Anda dapat yakin bahwa apa yang Anda lakukan bukanlah limbah elektronik, tetapi legal dan patuh, dan tidak ada kesalahan politik yang serius, saya akan memberikan beberapa dukungan teknis dalam kemampuan saya.
Jalan Cina tidak didukung? Faktanya, ontologi proyek mendukung jalur Tiongkok, tetapi versi onnxruntime sebelum Maret 2023 tidak mendukung jalur Cina, karena versi OnNxrunTime ini menggunakan fungsi seri-A Win32api, dan fungsi seri-A tidak mendukung jalur yang tidak dikodekan. Masalah ini bukanlah sesuatu yang bisa saya selesaikan atau harus saya selesaikan. Hanya Microsoft yang dapat memperbaiki bug ini. Untungnya, onnxruntime terbaru menggunakan fungsi seri W untuk menyelesaikan masalah jalur Cina.
Karena kompatibilitas CUDA yang sangat buruk, program berbasis CUDA harus diinstal dan disusun saat menginstal dan menyusun program, atau versi terbaru CUDA belum dimodifikasi. Masalah ini hanya bisa menunggu Nvidia memperhatikan kompatibilitas.
Moevoicestudiocore memberikan panggilan dalam bahasa C ++ dalam bentuk lib
Referensi kelas yang sesuai sesuai kebutuhan
# include < Modules/Models/header/Tacotron.hpp >
# include < Modules/Models/header/Vits.hpp >
# include < Modules/Models/header/VitsSvc.hpp >
# include < Modules/Models/header/DiffSvc.hpp >
# include < Modules/Models/header/DiffSinger.hpp >
InferClass::Tacotron2;
InferClass::Vits;
InferClass::VitsSvc;
InferClass::DiffusionSvc;
InferClass::DiffusionSinger;
/*
构造函数第一个是配置文件json
第二个是进度条回调
第三个是参数回调 (若为TTS 此参数为空即可)
第四个参数为设备
使用调用Inference函数即可
*/Untuk konfigurasi model, silakan merujuk ke konfigurasi #model
Demo: Contoh baris perintah RVC
Stop Update (karena kecepatan unduh dan unggah): Vocoder & HiddenUnitbert
Stop Update (karena Huggingface bertembok): Huggingface
Gudang Terbaru: Openi
Ekspor Preset Sendiri:
input_names harus ["source"] , output_names harus ["embed"] , dynamic_axes harus {"source":[0,2],}input_names harus ["c","f0"] , output_names harus ["audio"] , dynamic_axes harus {"c":[0,1],"f0":[0,1],}input_names harus ["x"] , output_names harus ["audio"] , dynamic_axes harus {"x":[0,1],}Model VEC dan model Hubert ditempatkan di folder Hubert, dan model Hifigan ditempatkan di folder Hifigan. Jika Anda perlu menggunakan dua prediktor F0, FCPE atau RMVPE, Anda perlu membuat folder F0Predictor di direktori root dan menempatkan model ONNX di dalamnya.
xxx.json adalah file konfigurasi untuk model. Itu perlu ditulis sesuai dengan templat sendiri, dan pada saat yang sama, perlu mengubah model menjadi sendiri. Folder : Simpan nama folder modelName : Nama tampilan model di UIType : Kategori ModelRate : Tingkat pengambilan sampel (harus persis sama seperti saat Anda berlatih. Jika Anda tidak memahami alasannya, disarankan untuk mempelajari pengetahuan terkait audio komputer) {
"Folder" : "Atri" ,
"Name" : "亚托莉-Tacotron2" ,
"Type" : "Tacotron2" ,
"Rate" : 22050 ,
"Symbol" : "_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" ,
"Cleaner" : "" ,
"AddBlank" : false ,
"Hifigan" : "hifigan"
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Tacotron2中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的hifigan放置到hifigan文件夹
//AddBlank:是否在音素之间插0作为分隔 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Vits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Vits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Pits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Pits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "NyaruTaffy" ,
"Name" : "NyaruTaffy" ,
"Type" : "RVC" ,
"Rate" : 40000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"SoVits2" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"HiddenSize" : 256 ,
"Cluster" : "Index"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 32000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 48000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"SoVits4.0V2" : false ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件)
//SoVits4.0V2: 是否为SoVits4.0V2模型 {
"Folder" : "DiffShiroha" ,
"Name" : "白羽" ,
"Type" : "DiffSvc" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"MelBins" : 128 ,
"Cleaner" : "" ,
"Hifigan" : "nsf_hifigan" ,
"Hubert" : "hubert" ,
"Characters" : [ ] ,
"Pndm" : 100 ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"V2" : true
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Pndm:加速倍数,如果是V1模型则必填且必须为导出时设置的加速倍率
//V2:是否为V2模型,V2模型就是后来我分4个模块导出的那个
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256) {
"Folder" : "utagoe" ,
"Name" : "utagoe" ,
"Type" : "DiffSinger" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hifigan" : "singer_nsf_hifigan" ,
"Characters" : [ ] ,
"MelBins" : 128
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的singer_nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到) {
"Folder" : "HimenoSena" ,
"Name" : "HimenoSena" ,
"Type" : "BertVits" ,
"Symbol" : [
"_" ,
"AA" ,
"E" ,
"EE" ,
"En" ,
"N" ,
"OO" ,
"V" ,
"a" ,
"a:" ,
"aa" ,
"ae" ,
"ah" ,
"ai" ,
"an" ,
"ang" ,
"ao" ,
"aw" ,
"ay" ,
"b" ,
"by" ,
"c" ,
"ch" ,
"d" ,
"dh" ,
"dy" ,
"e" ,
"e:" ,
"eh" ,
"ei" ,
"en" ,
"eng" ,
"er" ,
"ey" ,
"f" ,
"g" ,
"gy" ,
"h" ,
"hh" ,
"hy" ,
"i" ,
"i0" ,
"i:" ,
"ia" ,
"ian" ,
"iang" ,
"iao" ,
"ie" ,
"ih" ,
"in" ,
"ing" ,
"iong" ,
"ir" ,
"iu" ,
"iy" ,
"j" ,
"jh" ,
"k" ,
"ky" ,
"l" ,
"m" ,
"my" ,
"n" ,
"ng" ,
"ny" ,
"o" ,
"o:" ,
"ong" ,
"ou" ,
"ow" ,
"oy" ,
"p" ,
"py" ,
"q" ,
"r" ,
"ry" ,
"s" ,
"sh" ,
"t" ,
"th" ,
"ts" ,
"ty" ,
"u" ,
"u:" ,
"ua" ,
"uai" ,
"uan" ,
"uang" ,
"uh" ,
"ui" ,
"un" ,
"uo" ,
"uw" ,
"v" ,
"van" ,
"ve" ,
"vn" ,
"w" ,
"x" ,
"y" ,
"z" ,
"zh" ,
"zy" ,
"!" ,
"?" ,
"u2026" ,
"," ,
"." ,
"'" ,
"-" ,
"SP" ,
"UNK"
] ,
"Cleaner" : "" ,
"Rate" : 44100 ,
"CharaMix" : true ,
"Characters" : [
"u56fdu89c1u83dcu5b50" ,
"u59ecu91ceu661fu594f" ,
"u65b0u5802u5f69u97f3" ,
"u56dbu6761u51dbu9999" ,
"u5c0fu97a0u7531u4f9d"
] ,
"LanguageMap" : {
"ZH" : [
0 ,
0
] ,
"JP" : [
1 ,
6
] ,
"EN" : [
2 ,
8
]
} ,
"Dict" : "BasicDict" ,
"BertPath" : [
"chinese-roberta-wwm-ext-large" ,
"deberta-v2-large-japanese" ,
"bert-base-japanese-v3"
]
} // ${xxx}是什么意思大家应该都知道吧,总之以下是多个不同项目需要的模型文件(需要放置在对应的模型文件夹下)。
// Tacotron2:
${Folder} _decoder_iter.onnx
${Folder} _encoder.onnx
${Folder} _postnet.onnx
// Vits: 单角色VITS
${Folder} _dec.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// Vits: 多角色VITS
${Folder} _dec.onnx
${Folder} _emb.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// SoVits:
${Folder} _SoVits.onnx
// RVC:
${Folder} _RVC.onnx
// DiffSvc:
${Folder} _diffSvc.onnx
// DiffSvc: V2
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
${Folder} _after.onnx
// DiffSinger: OpenVpiVersion
${Folder} _diffSinger.onnx
// DiffSinger:
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
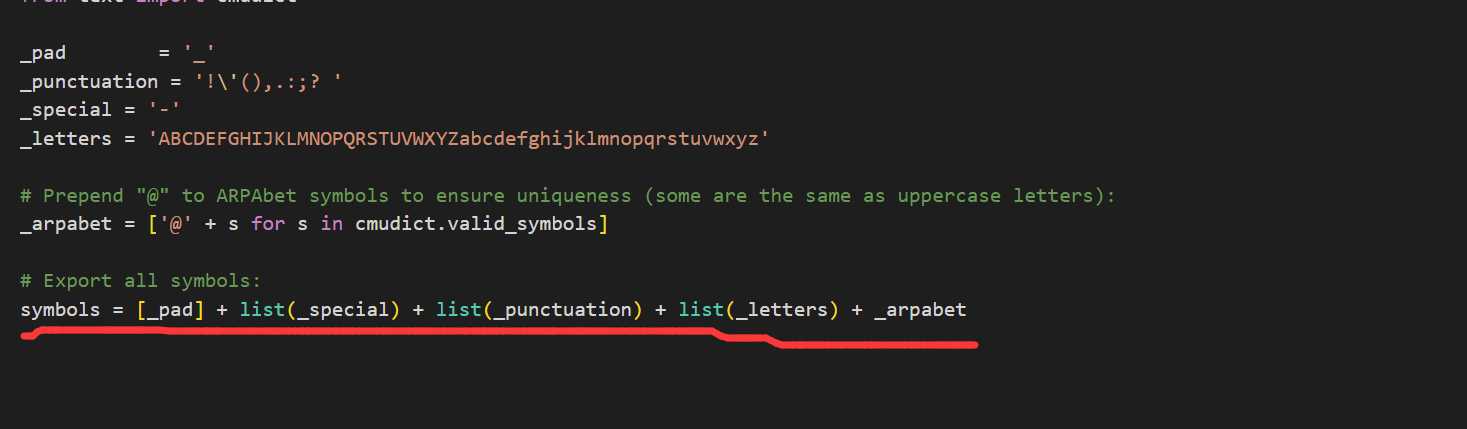
${Folder} _after.onnx例如:_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
打开你训练模型的项目,打开textsymbol.py,如图按照划线的List顺序将上面的4个字符串连接即可
/*
Cleaner请放置于根目录的Cleaners文件夹内,应该是一个按照要求定义的动态库(.dll),dll应当命名为Cleaner名,Cleaner名即为模型定义Json文件中Cleaner一栏填写的内容。
所有的插件dll需要定义以下函数,函数名必须为PluginMain,Dll名必须为插件名(或Cleaner名):
*/
const wchar_t * PluginMain ( const wchar_t *);
// 该接口只要求输入输出一致,并不要求功能一致,也就是说,你可以在改Dll中实现任何想要的功能,比方说ChatGpt,机器翻译等等。
// 以ChatGpt为例,PluginMain函数传入了一个输入字符串input,将该输入传入ChatGpt,再将ChatGpt的输出传入PluginMain,最后返回输出。
wchar_t * PluginMain ( wchar_t * input){
wchar_t * tmpOutput = ChatGpt (input);
return Clean (tmpOutput);
}
// 注意:导出dll时请使用 extern "C" 关键字来防止C++语言的破坏性命名。 git clone https: // github.com/NaruseMioShirakana/MoeVoiceStudio.git
//自行配置OnnxRuntime和FFMPEG的Dll
//使用VisualStudio构建Tidak ada organisasi atau individu yang dapat melanggar hak potret orang lain dengan menjelek -jelekkan, memfitnah, atau menggunakan teknologi informasi untuk memalsukannya. Potret pemegang hak potret tidak boleh diproduksi, digunakan atau diungkapkan tanpa persetujuan pemegang hak potret, kecuali sebagaimana ditentukan oleh hukum. Tanpa persetujuan pemegang hak potret, pemegang hak yang tepat dari pekerjaan potret tidak boleh menggunakan atau mengungkapkan potret pemegang hak potret dengan menerbitkan, menyalin, menerbitkan, menyewa, pameran, dll. Perlindungan suara orang alami akan tunduk pada ketentuan yang relevan tentang perlindungan hak -hak potret.
[Reputasi kanan] Subjek sipil menikmati hak reputasi. Tidak ada organisasi atau individu yang dapat melanggar hak reputasi orang lain dengan menghina, memfitnah, atau cara lain.
[Bekerja melanggar hak reputasi] Jika karya sastra dan artistik yang diterbitkan oleh pelaku dijelaskan oleh orang -orang nyata atau orang tertentu, dan mengandung konten penghinaan atau fitnah, yang melanggar hak reputasi orang lain, korban memiliki hak untuk meminta pelaku untuk menanggung tanggung jawab sipil sesuai dengan hukum. Karya -karya sastra dan artistik yang diterbitkan oleh pelaku tidak menggambarkan orang tertentu sebagai objek deskripsi, dan hanya jika plotnya mirip dengan situasi orang tertentu, mereka tidak akan menanggung tanggung jawab sipil.
Bahan gambar yang digunakan oleh Moess berasal dari:
Kriteria untuk menilai berpenghasilan rendah adalah: konten apa pun yang dihasilkan dengan menggunakan banyak AI, konten aslinya rendah, artinya tidak diketahui, kontennya berkualitas rendah, dll. ↩
Kriteria penilaian e-spam: 1. Orisinalitas. Proporsi barang -barang Anda sendiri di seluruh proyek (untuk AI, penciptaan menggunakan model yang sepenuhnya dilatih oleh Anda secara mandiri adalah milik Anda; penciptaan menggunakan model yang menjadi orang lain milik orang lain). Aspek yang dicakup termasuk tetapi tidak terbatas pada program, seni, audio, perencanaan, dll. Misalnya, menerapkan Unity dan templat mesin lainnya untuk menggantikan kulit adalah limbah elektronik. ↩


