DragonianVoice
ve api

Chinesisch | Englisch
Dieses Repository hat das UI -Projekt dauerhaft eingestellt und wird zu einem reinen LIB -Projekt. Die Code -Repository -Adresse lautet: Dragonianlib, aber die Veröffentlichung über SVC und TTS wird in diesem Repository weiterhin veröffentlicht.
Dieses Repository ist: 1. TTS (Tacotron2, vits, emotionalvits, Bertvits2, gptsovits); 2. SVC (SovitsSVC, RVC, Diffusionsvc, Fishdiffusion, Reflowsvc); 3..
Die neueste Version dieses Repositorys wurde mit Fish-Speech in Verbindung gebracht und verwendet das GGML-Framework, um die Fischrede umzuschreiben
Hinweis: SVS-fähiger Zweig: Moevoicestudio Moevoicestudiocore
In Bezug auf die Unterstützung von CUDA besuchen Sie bitte das offizielle Repository von OnnxRuntime.
Nach den Experimenten wird DML dazu führen, dass einige nicht unterstützte Operatoren in ONNX bei Verwendung keine Fehler melden, sondern ein unerwartetes Ergebnis zurückgeben, was zu Fehlern in den Folgerlern Ergebnissen von Sovits3.0 und Sovits4.0 auf DMLEP führt. Der ONNX-Export im neuesten Sovits-Repository hat diese Betreiber jedoch ersetzt, so
Aufgrund der Eigenschaften von Diffusions- und Reflow -Modellen ist die Gesamtzahl der in das Modell geschultes maximale Anzahl von Schritten (tatsächliche Anzahl der Schritte = Gesamtzahl der Schritte/Beschleunigungsvergrößerung, diese Gesamtzahl der Schritte ist nicht die tatsächliche Anzahl von Schritten, die Sie während der Inferenz unternommen haben, aber k_step), was den Ausgangs Audio verursacht, um sehr hohe Geräusche zu explodieren. Daher wird empfohlen, den MaxStep (oder k_step_max) in Ihrer Modellkonfigurationsdatei vor Inferenz sorgfältig zu beobachten.
Dieses Projekt ist ein Open -Source- und Offline -Projekt, und alle Entwickler und Betreuer dieses Projekts (im Folgenden als Mitwirkenden bezeichnet) haben keine Kontrolle über dieses Projekt . Die Mitwirkenden dieses Projekts haben noch nie eine Organisation oder Person in allen Formularen zur Verfügung gestellt, einschließlich, aber nicht beschränkt auf Datensatzextraktion, Datensatzverarbeitung, Rechenleistung, Trainingsunterstützung, Argumentation usw.; Die Mitwirkenden dieses Projekts kennen den Zweck des Benutzers, das das Projekt verwendet, nicht zu kennen oder kennen sie nicht. Daher hat alle auf diesem Projekt synthetisierten Audio nichts mit den Mitwirkenden dieses Projekts zu tun. Alle damit verursachten Probleme liegen in der eigenen Verantwortung des Benutzers .
Dieses Projekt selbst hat keine Funktion der Sprachsynthese, wird jedoch nur verwendet, um das eigene Training und die Produktion des Benutzer des Benutzers des ONNX -Modells zu starten. Das Modelltraining und die Produktion des ONNX -Modells hängen nicht mit den Mitwirkenden dieses Projekts zusammen und sind alle eigenen Verhaltensweisen der Benutzer. Die Mitwirkenden dieses Projekts haben nicht an der Modellschulung und der Produktion aller Benutzer teilgenommen.
Dieses Projekt wird vollständig offline ausgeführt und kann keine Benutzerinformationen erfassen und keine Benutzereingabedaten erhalten. Daher sind die Mitwirkenden dieses Projekts nicht alle Benutzereingaben und -modelle bekannt, daher sind sie nicht für Benutzereingaben verantwortlich.
Dieses Projekt wird auch mit keinem Modell ausgestattet, und jedes Modell, das in der Sekundärveröffentlichung und dem für dieses Projekt verwendeten Modell enthalten ist, hat nichts mit dem Entwickler dieses Projekts zu tun.
Dieses Projekt unterstützt derzeit voll und ganz das Rufen seiner eigenen Methoden zur Implementierung von Befehlszeilen und einer anderen Software. Jeder ist herzlich eingeladen, PR für dieses Projekt zu empfehlen
Andere Projekte des Autors: Aitoolkits
Wenn Sie an der Entwicklung teilnehmen möchten, können Sie sich der QQ -Gruppe anschließen: 263805400 oder direkt PR hinzufügen
Das Modell muss in ein ONNX -Modell umgewandelt werden. Weitere Informationen finden Sie im Quell -Repository des von Ihnen ausgewählten Projekts. Das PTH -Modell kann nicht direkt verwendet werden! ! ! ! ! ! ! ! ! ! ! ! !
Jeder Zweig dieses Projekts:
XP -Supremacisten sind begeistert, wer mag kein Drachenmädchen?
Die ursprüngliche Absicht dieses Projekts bestand darin, die Notwendigkeit verschiedener Sprachsyntheseprojekte ohne die Notwendigkeit des Umweltministeriums zu erkennen, und jetzt ist es geplant, als Hilfseditor für SVC hergestellt zu werden.
Da dieses Projekt schließlich ein "persönliches" und "unprofessionelles" Projekt ist, haben Sie mehr professionelle Software oder Sie sind ein Python -Cli -Enthusiast, oder Sie sind ein großer Schuss im verwandten Bereich. Ich weiß, dass diese Software nicht professionell genug ist und wahrscheinlich nicht Ihren Anforderungen entspricht oder für Sie gar nutzlos ist.
Dieses Projekt ist kein unersetzliches Projekt. Im Gegenteil, Sie können verschiedene Tools verwenden, um die Funktionen dieses Projekts zu ersetzen. Ich erwarte nicht, dass dieses Projekt ein führendes Projekt in verwandten Bereichen wird. Ich entwickle das Projekt einfach mit Begeisterung weiter. Die Begeisterung wird jedoch immer für einen Tag verschwinden, aber das Projekt verspricht, die Wartung zu halten, bis meine Begeisterung sich vollständig auflöst (unabhängig davon, ob jemand es verwendet, auch wenn die Anzahl der Benutzer 0 ist)
Das Design dieses Projekts kann verschiedene Probleme geben, sodass jeder auch gebratenen Reis aktiv anordnen muss, um die Funktionen zu verbessern. Ich werde den größten Teil der Optimierung von Funktionen und Erfahrungen akzeptieren.
Dieses Projekt ist Open Source und für immer kostenlos. Wenn es an anderen Orten eine kostenpflichtige Version dieses Projekts gibt, melden Sie es bitte sofort und kaufen Sie es nicht. Dieses Projekt ist für immer kostenlos. Wenn Sie die weißen Blätter mit dem verrückten Donnerstag füllen möchten, können Sie zu Aifa Dian https://afdian.net/a/narusemioshirakana gehen
Es ist nicht zur Verfügung gestellt, das Modell ist relativ einfach und es ist nicht erforderlich, um vergeblich Geld auszugeben. Folgen Sie einfach den Online -Tutorial Schritt für Schritt.
- Originalität. Der Anteil Ihres eigenen Sachens während des gesamten Projekts (für KI gehört die Erstellung von Modellen, die vollständig von Ihnen geschult werden, die unabhängig voneinander ausgebildet. Die Erstellung von Modellen, die andere sind, gehört anderen). Zu den behandelten Aspekten gehören, ohne darauf beschränkt zu sein, Programme, Kunst, Audio, Planung usw., beispielsweise die Anwendung von Einheits- und anderen Motorvorlagen zum Ersetzen von Skins ist elektronischer Abfall.
- Entwicklereinstellung. Die Einstellung des Autors besteht darin, Geld zu verdienen und einfach vergeblich zu sein. Zum Beispiel habe ich unzählige Tags wie "inländisch", "zuerst", "stärkste" und "hausgemacht" getroffen, was zu sehr schlechten oder mittelmäßigen Dingen führte, und der Autor hat offensichtlich keine Ahnung, dass das Projekt das Projekt gut macht, nämlich elektronischer Abfall.
- Lehnen Sie alle kommerziellen Verhaltensweisen von KI -Modellen ab, die mit nicht autorisierten Datensätzen trainiert wurden.
Wenn Sie sicher sein können, dass Sie nicht elektronisch, sondern legal und konform sind, und es keine ernsthaften politischen Fehler gibt, werde ich innerhalb meiner Fähigkeiten eine gewisse technische Unterstützung leisten.
Der chinesische Weg wird nicht unterstützt? Tatsächlich unterstützt die Projekt-Ontologie chinesische Wege, aber die Version von Onnxruntime vor März 2023 unterstützt keine chinesischen Pfade, da diese Versionen von Onnxruntime die A-Serie-Funktionen von Win32API verwenden und die A-Serie-Funktionen nicht-Ans-Anbieter-Pfade unterstützen. Dieses Problem kann ich nicht lösen oder sollte ich lösen. Nur Microsoft kann diesen Fehler beheben. Glücklicherweise verwendet die neueste OnNXruntime -Funktionen W -Serien, um das chinesische Pfadproblem zu lösen.
Aufgrund der extrem schlechten Kompatibilität von CUDA muss ein CUDA-basiertes Programm installiert und zusammengestellt werden, wenn das Programm installiert und zusammengestellt wird, oder die neueste Version von CUDA wurde nicht geändert. Dieses Problem kann nur darauf gewartet werden, dass Nvidia auf die Kompatibilität achtet.
Moevoicestudiocore liefert Aufrufe in C ++ - Sprache in Form von LIB
Verweisen Sie nach Bedarf auf die folgenden entsprechenden Klassen
# include < Modules/Models/header/Tacotron.hpp >
# include < Modules/Models/header/Vits.hpp >
# include < Modules/Models/header/VitsSvc.hpp >
# include < Modules/Models/header/DiffSvc.hpp >
# include < Modules/Models/header/DiffSinger.hpp >
InferClass::Tacotron2;
InferClass::Vits;
InferClass::VitsSvc;
InferClass::DiffusionSvc;
InferClass::DiffusionSinger;
/*
构造函数第一个是配置文件json
第二个是进度条回调
第三个是参数回调 (若为TTS 此参数为空即可)
第四个参数为设备
使用调用Inference函数即可
*/Für die Modellkonfiguration finden Sie in der #Model -Konfiguration
Demo: RVC -Befehlszeile Beispiel
Stoppen Sie Updates (aufgrund des Downloads und Hochladens): Vocoder & Hiddenunitberts
STOP -UPDATE (weil das Umarmungen umgewandelt ist): Umarmungface
Letzte Lager: Openi
Exportieren Sie die Voreinstellung selbst:
input_names sollte ["source"] , output_names sein ["embed"] , dynamic_axes sollte {"source":[0,2],}input_names sollte ["c","f0"] , output_names sein ["audio"] , dynamic_axes sollte {"c":[0,1],"f0":[0,1],}input_names sollte ["x"] , output_names sein ["audio"] , dynamic_axes sollte {"x":[0,1],}Das VEC -Modell und das Hubert -Modell werden im Hubert -Ordner platziert, und das HiFigan -Modell wird in den Hifigan -Ordner platziert. Wenn Sie die beiden F0 -Prädiktoren FCPE oder RMVPE verwenden müssen, müssen Sie den F0Predictor -Ordner im Stammverzeichnis erstellen und das ONNX -Modell darin platzieren.
xxx.json ist eine Konfigurationsdatei für das Modell. Es muss nach der Vorlage selbst geschrieben werden, und gleichzeitig muss das Modell selbst in die Lage versetzt werden. Folder : Speichern Sie den Ordnernamen des ModellsName : Der Anzeigename des Modells in der BenutzeroberflächeType : ModellkategorieRate : Die Stichprobenrate (es muss genau das gleiche sein wie beim Training. Wenn Sie den Grund nicht verstehen, wird empfohlen, Computer-Audio-bezogenes Wissen zu erlernen)) {
"Folder" : "Atri" ,
"Name" : "亚托莉-Tacotron2" ,
"Type" : "Tacotron2" ,
"Rate" : 22050 ,
"Symbol" : "_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" ,
"Cleaner" : "" ,
"AddBlank" : false ,
"Hifigan" : "hifigan"
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Tacotron2中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的hifigan放置到hifigan文件夹
//AddBlank:是否在音素之间插0作为分隔 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Vits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Vits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Pits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Pits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "NyaruTaffy" ,
"Name" : "NyaruTaffy" ,
"Type" : "RVC" ,
"Rate" : 40000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"SoVits2" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"HiddenSize" : 256 ,
"Cluster" : "Index"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 32000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 48000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"SoVits4.0V2" : false ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件)
//SoVits4.0V2: 是否为SoVits4.0V2模型 {
"Folder" : "DiffShiroha" ,
"Name" : "白羽" ,
"Type" : "DiffSvc" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"MelBins" : 128 ,
"Cleaner" : "" ,
"Hifigan" : "nsf_hifigan" ,
"Hubert" : "hubert" ,
"Characters" : [ ] ,
"Pndm" : 100 ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"V2" : true
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Pndm:加速倍数,如果是V1模型则必填且必须为导出时设置的加速倍率
//V2:是否为V2模型,V2模型就是后来我分4个模块导出的那个
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256) {
"Folder" : "utagoe" ,
"Name" : "utagoe" ,
"Type" : "DiffSinger" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hifigan" : "singer_nsf_hifigan" ,
"Characters" : [ ] ,
"MelBins" : 128
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的singer_nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到) {
"Folder" : "HimenoSena" ,
"Name" : "HimenoSena" ,
"Type" : "BertVits" ,
"Symbol" : [
"_" ,
"AA" ,
"E" ,
"EE" ,
"En" ,
"N" ,
"OO" ,
"V" ,
"a" ,
"a:" ,
"aa" ,
"ae" ,
"ah" ,
"ai" ,
"an" ,
"ang" ,
"ao" ,
"aw" ,
"ay" ,
"b" ,
"by" ,
"c" ,
"ch" ,
"d" ,
"dh" ,
"dy" ,
"e" ,
"e:" ,
"eh" ,
"ei" ,
"en" ,
"eng" ,
"er" ,
"ey" ,
"f" ,
"g" ,
"gy" ,
"h" ,
"hh" ,
"hy" ,
"i" ,
"i0" ,
"i:" ,
"ia" ,
"ian" ,
"iang" ,
"iao" ,
"ie" ,
"ih" ,
"in" ,
"ing" ,
"iong" ,
"ir" ,
"iu" ,
"iy" ,
"j" ,
"jh" ,
"k" ,
"ky" ,
"l" ,
"m" ,
"my" ,
"n" ,
"ng" ,
"ny" ,
"o" ,
"o:" ,
"ong" ,
"ou" ,
"ow" ,
"oy" ,
"p" ,
"py" ,
"q" ,
"r" ,
"ry" ,
"s" ,
"sh" ,
"t" ,
"th" ,
"ts" ,
"ty" ,
"u" ,
"u:" ,
"ua" ,
"uai" ,
"uan" ,
"uang" ,
"uh" ,
"ui" ,
"un" ,
"uo" ,
"uw" ,
"v" ,
"van" ,
"ve" ,
"vn" ,
"w" ,
"x" ,
"y" ,
"z" ,
"zh" ,
"zy" ,
"!" ,
"?" ,
"u2026" ,
"," ,
"." ,
"'" ,
"-" ,
"SP" ,
"UNK"
] ,
"Cleaner" : "" ,
"Rate" : 44100 ,
"CharaMix" : true ,
"Characters" : [
"u56fdu89c1u83dcu5b50" ,
"u59ecu91ceu661fu594f" ,
"u65b0u5802u5f69u97f3" ,
"u56dbu6761u51dbu9999" ,
"u5c0fu97a0u7531u4f9d"
] ,
"LanguageMap" : {
"ZH" : [
0 ,
0
] ,
"JP" : [
1 ,
6
] ,
"EN" : [
2 ,
8
]
} ,
"Dict" : "BasicDict" ,
"BertPath" : [
"chinese-roberta-wwm-ext-large" ,
"deberta-v2-large-japanese" ,
"bert-base-japanese-v3"
]
} // ${xxx}是什么意思大家应该都知道吧,总之以下是多个不同项目需要的模型文件(需要放置在对应的模型文件夹下)。
// Tacotron2:
${Folder} _decoder_iter.onnx
${Folder} _encoder.onnx
${Folder} _postnet.onnx
// Vits: 单角色VITS
${Folder} _dec.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// Vits: 多角色VITS
${Folder} _dec.onnx
${Folder} _emb.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// SoVits:
${Folder} _SoVits.onnx
// RVC:
${Folder} _RVC.onnx
// DiffSvc:
${Folder} _diffSvc.onnx
// DiffSvc: V2
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
${Folder} _after.onnx
// DiffSinger: OpenVpiVersion
${Folder} _diffSinger.onnx
// DiffSinger:
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
${Folder} _after.onnx例如:_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
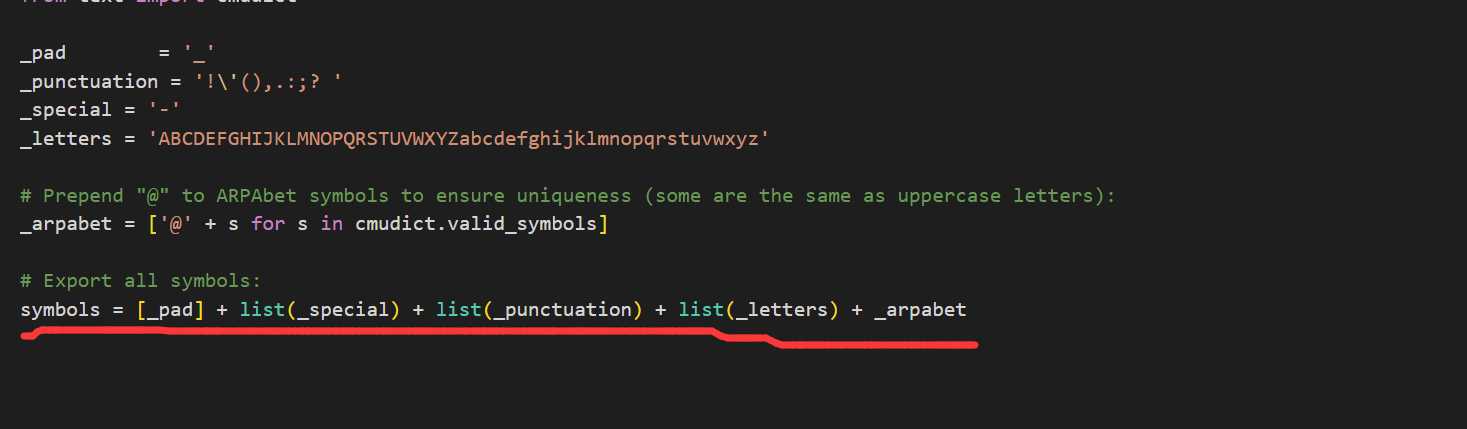
打开你训练模型的项目,打开textsymbol.py,如图按照划线的List顺序将上面的4个字符串连接即可
/*
Cleaner请放置于根目录的Cleaners文件夹内,应该是一个按照要求定义的动态库(.dll),dll应当命名为Cleaner名,Cleaner名即为模型定义Json文件中Cleaner一栏填写的内容。
所有的插件dll需要定义以下函数,函数名必须为PluginMain,Dll名必须为插件名(或Cleaner名):
*/
const wchar_t * PluginMain ( const wchar_t *);
// 该接口只要求输入输出一致,并不要求功能一致,也就是说,你可以在改Dll中实现任何想要的功能,比方说ChatGpt,机器翻译等等。
// 以ChatGpt为例,PluginMain函数传入了一个输入字符串input,将该输入传入ChatGpt,再将ChatGpt的输出传入PluginMain,最后返回输出。
wchar_t * PluginMain ( wchar_t * input){
wchar_t * tmpOutput = ChatGpt (input);
return Clean (tmpOutput);
}
// 注意:导出dll时请使用 extern "C" 关键字来防止C++语言的破坏性命名。 git clone https: // github.com/NaruseMioShirakana/MoeVoiceStudio.git
//自行配置OnnxRuntime和FFMPEG的Dll
//使用VisualStudio构建Keine Organisation oder Person darf die Porträtrechte anderer verletzen, indem sie sich verleumdet, diffamieren oder Informationstechnologie verwenden, um sie zu fälschen. Das Porträt des Porträtsrechtshalters darf ohne Zustimmung des Porträt -Rechtshalters nicht produziert, verwendet oder offengelegt werden, außer wie gesetzlich vorgesehen. Ohne die Zustimmung des Porträt -Rechtshalters darf der Rechtsinhaber des Porträtwerks das Porträt des Porträts nicht verwenden oder offenlegen, indem sie das Porträt des Rechts in der Porträts veröffentlichen, kopieren, ausstellen, mieten, ausstellen usw. Der Schutz der Stimmen der natürlichen Person unterliegt den entsprechenden Bestimmungen zum Schutz der Porträtrechte.
[Ruf Recht] Zivile Themen genießen das Recht auf Ruf. Keine Organisation oder Person darf die Rufrechte anderer durch Beleidigung, Verleumdung oder andere Mittel verletzen.
[Werke verletzen die Rechte der Reputation] Wenn die vom Täter veröffentlichten literarischen und künstlerischen Werke von echten Personen oder bestimmten Personen beschrieben werden und beleidigende oder verleumdete Inhalte enthalten, die die Rufrechte anderer verletzt, hat das Opfer das Recht, den Täter zu bitten, die zivile Haftung nach dem Gesetz zu ertragen. Die vom Täter veröffentlichten literarischen und künstlerischen Werke beschreiben keine bestimmte Person als Objekt der Beschreibung, und nur, wenn die Diagramme der Situation der spezifischen Person ähnlich sind, dürfen sie keine zivilrechtliche Haftung tragen.
Die von Moess verwendeten Bildmaterialien stammen ab:
Die Kriterien für die Beurteilung mit niedrigem Einkommen sind: Alle Inhalte, die mit viel KI generiert werden, der ursprüngliche Inhalt ist gering, die Bedeutung ist unbekannt, der Inhalt von geringer Qualität usw. ↩ ↩
E-SPAM-Urteilskriterien: 1. Originalität. Der Anteil Ihres eigenen Sachens während des gesamten Projekts (für KI gehört die Erstellung von Modellen, die vollständig von Ihnen geschult werden, die unabhängig voneinander ausgebildet. Die Erstellung von Modellen, die andere sind, gehört anderen). Zu den behandelten Aspekten gehören, ohne darauf beschränkt zu sein, Programme, Kunst, Audio, Planung usw., beispielsweise die Anwendung von Einheits- und anderen Motorvorlagen zum Ersetzen von Skins ist elektronischer Abfall. ↩


