DragonianVoice
ve api

Chinois | Anglais
Ce référentiel a cessé de maintenir en permanence le projet d'interface utilisateur et deviendra un projet de lib pur. L'adresse du référentiel de code est: DragonianLib, mais la version concernant SVC et TTS est toujours publiée dans ce référentiel.
Ce référentiel est: 1. TTS (Tacotron2, VITS, Emotionalvits, Bertvits2, Gptsovits); 2. SVC (SoVitsSVC, RVC, DiffusionsVC, Fishdiffusion, reflowsvc); 3. SVS (DiffSinger) ONNX Framework Reasoning Repository, prend actuellement en charge les appels C / CPP / C #.
La dernière version de ce référentiel a été liée au discours de poisson et utilise le cadre GGML pour réécrire le discours de poisson pour former le sous-projet de poisson.
Remarque: Branche compatible SVS: MoevoiceStudio MoevoiceStudiocore
En ce qui concerne le support CUDA, veuillez visiter le référentiel officiel d'Onnxruntime.
Après des expériences, DML entraînera que certains opérateurs non pris en charge de l'ONNX ne signalent pas les erreurs lorsqu'ils sont utilisés, mais renverront un résultat inattendu, ce qui entraînera des erreurs dans les résultats d'inférence de SoVits3.0 et SoVits4.0 sur DMLEP. Cependant, l'exportation ONNX dans le dernier référentiel Sovits a remplacé ces opérateurs, donc Sovits3.0 et Sovits4.0 Prise en charge de la prise en charge DML, mais le modèle ONNX doit être réexporté à l'aide de la dernière version (2023/7/17) de Sovitsonnx Exporton
En raison des caractéristiques de la diffusion et des modèles de reflux, si le nombre total d'étapes que vous déduisez est supérieur au nombre maximum d'étapes que vous avez formées au modèle (nombre réel d'étapes = nombre total d'étapes / grossissement d'accélération, ce nombre total d'étapes n'est pas le nombre réel d'étapes que vous avez prises pendant l'inférence, mais K_STEP), ce qui entraînera l'explosion de l'audio ou le cause de la sortie. Par conséquent, il est recommandé d'observer soigneusement le maxstep (ou k_step_max) dans votre fichier de configuration de modèle avant l'inférence.
Ce projet est un projet open source et hors ligne, et tous les développeurs et maintenants de ce projet (ci-après dénommés contributeurs) n'ont aucun contrôle sur ce projet . Les contributeurs de ce projet n'ont jamais fourni aucune organisation ou individu d'aide dans toutes les formes, y compris, mais sans s'y limiter, l'extraction des ensembles de données, le traitement des ensembles de données, la prise en charge de la puissance de calcul, la prise en charge de la formation, le raisonnement, etc.; Les contributeurs de ce projet ne connaissent pas ou ne connaissent pas l'objectif de l'utilisateur à l'aide du projet. Par conséquent, tous les synthétisés audio sur la base de ce projet n'ont rien à voir avec les contributeurs de ce projet. Tous les problèmes causés par cela sont à la propre responsabilité de l'utilisateur .
Ce projet lui-même n'a aucune fonction de synthèse de la parole, mais n'est utilisé que pour démarrer la formation et la production de l'utilisateur du modèle ONNX. La formation du modèle et la production du modèle ONNX ne sont pas liées aux contributeurs de ce projet et sont tous les comportements des utilisateurs. Les contributeurs de ce projet n'ont pas participé à la formation et à la production du modèle de tous les utilisateurs.
Ce projet est exécuté complètement hors ligne et ne peut collecter aucune information utilisateur et ne peut pas obtenir de données d'entrée utilisateur. Par conséquent, les contributeurs de ce projet ne sont pas conscients de toutes les entrées et modèles utilisateur, ils ne sont donc pas responsables de toute entrée utilisateur.
Ce projet ne vient également pas avec aucun modèle, et tout modèle inclus avec la version secondaire et le modèle utilisé pour ce projet n'ont rien à voir avec le développeur de ce projet.
Ce projet prend actuellement en charge l'appel de ses propres méthodes pour implémenter le raisonnement de ligne de commande ou d'autres logiciels. Tout le monde est le bienvenu pour recommander des relations publiques à ce projet
Autres projets de l'auteur: Aitoolkits
Si vous souhaitez participer au développement, vous pouvez rejoindre le groupe QQ: 263805400 ou ajouter directement PR
Le modèle doit être converti en un modèle ONNX. Pour plus de détails, consultez le référentiel source du projet que vous avez sélectionné. Le modèle PTH ne peut pas être utilisé directement! ! ! ! ! ! ! ! ! ! ! ! !
Chaque branche de ce projet:
Les suprémacistes XP sont extatiques, qui n'aime pas Dragon Girl?
L'intention initiale de ce projet était de réaliser la nécessité de divers projets de synthèse vocale sans avoir besoin du ministère de l'Environnement, et maintenant il devrait être fait en tant qu'éditeur auxiliaire pour SVC.
Étant donné que ce projet est un projet "personnel" et "non professionnel" après tout, vous avez plus de logiciels professionnels, ou vous êtes un passionné de CLI Python, ou vous êtes un gros coup dans le domaine connexe. Je sais que ce logiciel n'est pas assez professionnel et n'est susceptible de ne pas répondre à vos besoins ou même inutile pour vous.
Ce projet n'est pas un projet irremplaçable. Au contraire, vous pouvez utiliser divers outils pour remplacer les fonctions de ce projet. Je ne m'attends pas à ce que ce projet devienne un projet de premier plan dans les domaines connexes. Je continue de développer le projet avec enthousiasme. Mais l'enthousiasme disparaîtra toujours pendant une journée, mais le projet promet de maintenir la maintenance jusqu'à ce que mon enthousiasme se dissipe complètement (que quelqu'un l'utilise, même si le nombre d'utilisateurs est 0)
Il peut y avoir divers problèmes dans la conception de ce projet, donc tout le monde doit également commander activement du riz frit pour m'aider à améliorer les fonctions. J'accepterai la majeure partie de l'optimisation des fonctions et de l'expérience.
Ce projet est open source et gratuit pour toujours. S'il y a une version payante de ce projet dans d'autres endroits, veuillez le signaler immédiatement et ne pas l'acheter. Ce projet est gratuit pour toujours. Si vous voulez remplir les feuilles blanches du jeudi folle, vous pouvez aller à Aifa Dian https://afdian.net/a/narusemioshirakana
Il n'est pas fourni, la formation du modèle est relativement simple et il n'est pas nécessaire de dépenser de l'argent en vain. Suivez simplement le tutoriel en ligne étape par étape.
- Originalité. La proportion de vos propres trucs tout au long du projet (pour l'IA, la création d'utilisation de modèles qui sont entièrement formés par vous indépendamment vous appartient indépendamment; la création d'utilisation de modèles qui sont d'autres appartiennent à d'autres). Les aspects couverts comprennent, sans s'y limiter, les programmes, l'art, l'audio, la planification, etc. Par exemple, l'application de l'unité et d'autres modèles de moteur pour remplacer les skins est les déchets électroniques.
- Attitude du développeur. L'attitude de l'auteur est de gagner de l'argent et de partir ou d'être simplement vain. Par exemple, j'ai frappé d'innombrables étiquettes, comme "domestique", "d'abord", "plus fortes" et "maison", ce qui a abouti à des choses très mauvaises ou médiocres, et l'auteur n'a évidemment aucune idée de bien réaliser le projet, qui est des déchets électroniques.
- Opposer tous les comportements commerciaux des modèles d'IA formés à l'aide d'ensembles de données non autorisés.
Si vous pouvez être sûr que ce que vous faites n'est pas des déchets électroniques, mais qu'il est légal et conforme, et qu'il n'y a pas d'erreurs politiques graves, je fournirai un certain soutien technique au sein de mes capacités.
Le chemin chinois n'est pas pris en charge? En fait, l'ontologie du projet prend en charge les chemins chinois, mais la version d'Onnxruntime avant mars 2023 ne prend pas en charge les chemins chinois, car ces versions d'Onnxruntime utilisent les fonctions de la série A Win32API, et les fonctions de la série A ne prennent pas en charge les chemins non codés. Ce problème n'est pas quelque chose que je peux résoudre ou devrais-je résoudre. Seul Microsoft peut corriger ce bogue. Heureusement, le dernier onnxruntime utilise les fonctions de la série W pour résoudre le problème du chemin chinois.
En raison de la compatibilité extrêmement mauvaise de CUDA, un programme basé sur CUDA doit être installé et compilé lors de l'installation et de la compilation du programme, ou la dernière version de CUDA n'a pas été modifiée. Ce problème ne peut être attendu que Nvidia pour faire attention à la compatibilité.
MoevoiceStudioCore fournit des appels dans la langue C ++ sous la forme de lib
Référencer les classes correspondantes suivantes au besoin
# include < Modules/Models/header/Tacotron.hpp >
# include < Modules/Models/header/Vits.hpp >
# include < Modules/Models/header/VitsSvc.hpp >
# include < Modules/Models/header/DiffSvc.hpp >
# include < Modules/Models/header/DiffSinger.hpp >
InferClass::Tacotron2;
InferClass::Vits;
InferClass::VitsSvc;
InferClass::DiffusionSvc;
InferClass::DiffusionSinger;
/*
构造函数第一个是配置文件json
第二个是进度条回调
第三个是参数回调 (若为TTS 此参数为空即可)
第四个参数为设备
使用调用Inference函数即可
*/Pour la configuration du modèle, veuillez vous référer à la configuration #Model
Démo: exemple de ligne de commande RVC
Stop Mises à jour (en raison de la vitesse de téléchargement et de téléchargement): Vocoder & HiddenUnitbert
Arrêtez la mise à jour (parce que HuggingFace est mural): HuggingFace
Dernier entrepôt: OpenI
Exportez le préréglage vous-même:
input_names doit être ["source"] , output_names doit être ["embed"] , dynamic_axes devrait être {"source":[0,2],}input_names doit être ["c","f0"] , output_names devrait être ["audio"] , dynamic_axes devrait être {"c":[0,1],"f0":[0,1],}input_names doit être ["x"] , output_names devrait être ["audio"] , dynamic_axes devrait être {"x":[0,1],}Le modèle VEC et le modèle Hubert sont placés dans le dossier Hubert, et le modèle HIFIGAN est placé dans le dossier Hifigan. Si vous devez utiliser les deux prédicteurs F0, FCPE ou RMVPE, vous devez créer le dossier F0Predictor dans le répertoire racine et y placer le modèle ONNX.
xxx.json est un fichier de configuration pour le modèle. Il doit être écrit en fonction du modèle vous-même, et en même temps, il doit convertir le modèle en onnx vous-même. Folder : enregistrez le nom du dossier du modèleName : le nom d'affichage du modèle dans l'interface utilisateurType : catégorie de modèleRate : Le taux d'échantillonnage (il doit être exactement le même que lorsque vous vous entraînez. Si vous ne comprenez pas la raison, il est recommandé d'apprendre des connaissances liées audio en informatique) {
"Folder" : "Atri" ,
"Name" : "亚托莉-Tacotron2" ,
"Type" : "Tacotron2" ,
"Rate" : 22050 ,
"Symbol" : "_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" ,
"Cleaner" : "" ,
"AddBlank" : false ,
"Hifigan" : "hifigan"
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Tacotron2中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的hifigan放置到hifigan文件夹
//AddBlank:是否在音素之间插0作为分隔 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Vits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Vits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Pits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Pits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "NyaruTaffy" ,
"Name" : "NyaruTaffy" ,
"Type" : "RVC" ,
"Rate" : 40000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"SoVits2" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"HiddenSize" : 256 ,
"Cluster" : "Index"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 32000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 48000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"SoVits4.0V2" : false ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件)
//SoVits4.0V2: 是否为SoVits4.0V2模型 {
"Folder" : "DiffShiroha" ,
"Name" : "白羽" ,
"Type" : "DiffSvc" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"MelBins" : 128 ,
"Cleaner" : "" ,
"Hifigan" : "nsf_hifigan" ,
"Hubert" : "hubert" ,
"Characters" : [ ] ,
"Pndm" : 100 ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"V2" : true
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Pndm:加速倍数,如果是V1模型则必填且必须为导出时设置的加速倍率
//V2:是否为V2模型,V2模型就是后来我分4个模块导出的那个
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256) {
"Folder" : "utagoe" ,
"Name" : "utagoe" ,
"Type" : "DiffSinger" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hifigan" : "singer_nsf_hifigan" ,
"Characters" : [ ] ,
"MelBins" : 128
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的singer_nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到) {
"Folder" : "HimenoSena" ,
"Name" : "HimenoSena" ,
"Type" : "BertVits" ,
"Symbol" : [
"_" ,
"AA" ,
"E" ,
"EE" ,
"En" ,
"N" ,
"OO" ,
"V" ,
"a" ,
"a:" ,
"aa" ,
"ae" ,
"ah" ,
"ai" ,
"an" ,
"ang" ,
"ao" ,
"aw" ,
"ay" ,
"b" ,
"by" ,
"c" ,
"ch" ,
"d" ,
"dh" ,
"dy" ,
"e" ,
"e:" ,
"eh" ,
"ei" ,
"en" ,
"eng" ,
"er" ,
"ey" ,
"f" ,
"g" ,
"gy" ,
"h" ,
"hh" ,
"hy" ,
"i" ,
"i0" ,
"i:" ,
"ia" ,
"ian" ,
"iang" ,
"iao" ,
"ie" ,
"ih" ,
"in" ,
"ing" ,
"iong" ,
"ir" ,
"iu" ,
"iy" ,
"j" ,
"jh" ,
"k" ,
"ky" ,
"l" ,
"m" ,
"my" ,
"n" ,
"ng" ,
"ny" ,
"o" ,
"o:" ,
"ong" ,
"ou" ,
"ow" ,
"oy" ,
"p" ,
"py" ,
"q" ,
"r" ,
"ry" ,
"s" ,
"sh" ,
"t" ,
"th" ,
"ts" ,
"ty" ,
"u" ,
"u:" ,
"ua" ,
"uai" ,
"uan" ,
"uang" ,
"uh" ,
"ui" ,
"un" ,
"uo" ,
"uw" ,
"v" ,
"van" ,
"ve" ,
"vn" ,
"w" ,
"x" ,
"y" ,
"z" ,
"zh" ,
"zy" ,
"!" ,
"?" ,
"u2026" ,
"," ,
"." ,
"'" ,
"-" ,
"SP" ,
"UNK"
] ,
"Cleaner" : "" ,
"Rate" : 44100 ,
"CharaMix" : true ,
"Characters" : [
"u56fdu89c1u83dcu5b50" ,
"u59ecu91ceu661fu594f" ,
"u65b0u5802u5f69u97f3" ,
"u56dbu6761u51dbu9999" ,
"u5c0fu97a0u7531u4f9d"
] ,
"LanguageMap" : {
"ZH" : [
0 ,
0
] ,
"JP" : [
1 ,
6
] ,
"EN" : [
2 ,
8
]
} ,
"Dict" : "BasicDict" ,
"BertPath" : [
"chinese-roberta-wwm-ext-large" ,
"deberta-v2-large-japanese" ,
"bert-base-japanese-v3"
]
} // ${xxx}是什么意思大家应该都知道吧,总之以下是多个不同项目需要的模型文件(需要放置在对应的模型文件夹下)。
// Tacotron2:
${Folder} _decoder_iter.onnx
${Folder} _encoder.onnx
${Folder} _postnet.onnx
// Vits: 单角色VITS
${Folder} _dec.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// Vits: 多角色VITS
${Folder} _dec.onnx
${Folder} _emb.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// SoVits:
${Folder} _SoVits.onnx
// RVC:
${Folder} _RVC.onnx
// DiffSvc:
${Folder} _diffSvc.onnx
// DiffSvc: V2
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
${Folder} _after.onnx
// DiffSinger: OpenVpiVersion
${Folder} _diffSinger.onnx
// DiffSinger:
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
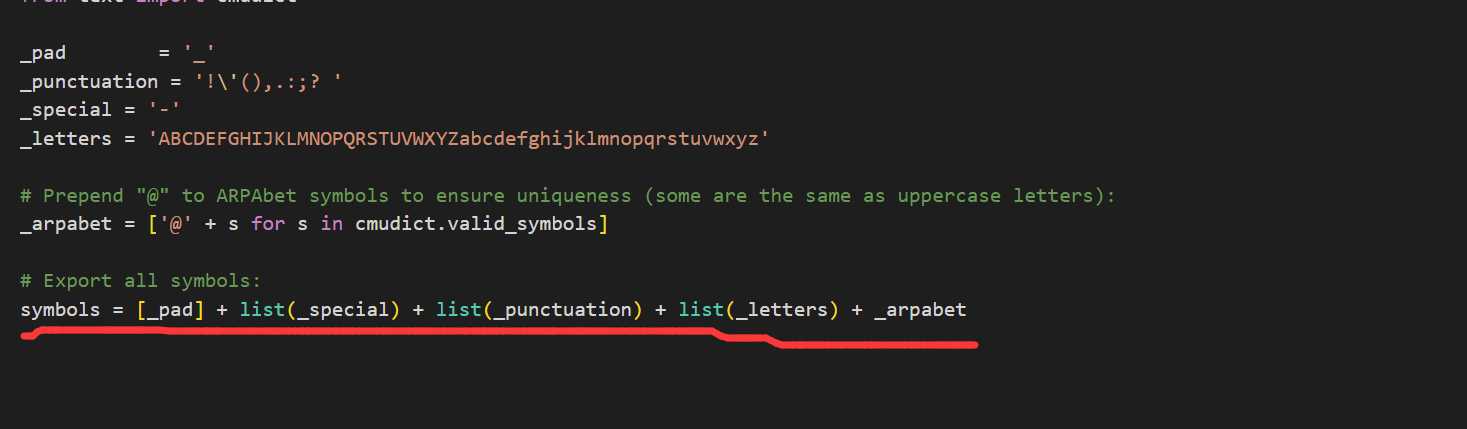
${Folder} _after.onnx例如:_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
打开你训练模型的项目,打开textsymbol.py,如图按照划线的List顺序将上面的4个字符串连接即可
/*
Cleaner请放置于根目录的Cleaners文件夹内,应该是一个按照要求定义的动态库(.dll),dll应当命名为Cleaner名,Cleaner名即为模型定义Json文件中Cleaner一栏填写的内容。
所有的插件dll需要定义以下函数,函数名必须为PluginMain,Dll名必须为插件名(或Cleaner名):
*/
const wchar_t * PluginMain ( const wchar_t *);
// 该接口只要求输入输出一致,并不要求功能一致,也就是说,你可以在改Dll中实现任何想要的功能,比方说ChatGpt,机器翻译等等。
// 以ChatGpt为例,PluginMain函数传入了一个输入字符串input,将该输入传入ChatGpt,再将ChatGpt的输出传入PluginMain,最后返回输出。
wchar_t * PluginMain ( wchar_t * input){
wchar_t * tmpOutput = ChatGpt (input);
return Clean (tmpOutput);
}
// 注意:导出dll时请使用 extern "C" 关键字来防止C++语言的破坏性命名。 git clone https: // github.com/NaruseMioShirakana/MoeVoiceStudio.git
//自行配置OnnxRuntime和FFMPEG的Dll
//使用VisualStudio构建Aucune organisation ou individu ne peut porter atteinte aux droits des portraits des autres en diffamant, en diffamant ou en utilisant des technologies de l'information pour les forger. Le portrait du portrait droit ne doit pas être produit, utilisé ou divulgué sans le consentement du porte-portrait droit, sauf disposition contraire de la loi. Sans le consentement du porte-portrait droit, le titulaire du droit de l'œuvre de portrait ne doit pas utiliser ou divulguer le portrait du portrait du portrait en publiant, en copie, en émettant, en louant, en exposition, etc. La protection des voix de la personne naturelle sera soumise aux dispositions pertinentes sur la protection des droits du portrait.
[Réputation du droit] Les sujets civils jouissent du droit à la réputation. Aucune organisation ou individu ne peut porter atteinte aux droits de réputation des autres en insultant, en calcul ou en d'autres moyens.
[Les œuvres portent atteinte aux droits de réputation] Si les œuvres littéraires et artistiques publiées par l'agresseur sont décrites par de vraies personnes ou des personnes spécifiques, et contiennent du contenu insultant ou calomnieux, ce qui porte atteinte aux droits de réputation des autres, la victime a le droit de demander à l'agresseur de supporter la responsabilité civile conformément à la loi. Les œuvres littéraires et artistiques publiées par l'agresseur ne décrivent pas une personne spécifique comme l'objet de description, et ce n'est que si les parcelles sont similaires à la situation de la personne spécifique, elles ne doivent pas avoir de responsabilité civile.
Les matériaux d'image utilisés par Moess sont dérivés de:
Les critères de jugement à faible revenu sont: tout contenu généré en utilisant beaucoup d'IA, le contenu original est faible, la signification est inconnue, le contenu est de faible qualité, etc. ↩
Critères de jugement E-SPAM: 1. Originalité. La proportion de vos propres trucs tout au long du projet (pour l'IA, la création d'utilisation de modèles qui sont entièrement formés par vous indépendamment vous appartient indépendamment; la création d'utilisation de modèles qui sont d'autres appartiennent à d'autres). Les aspects couverts comprennent, sans s'y limiter, les programmes, l'art, l'audio, la planification, etc. Par exemple, l'application de l'unité et d'autres modèles de moteur pour remplacer les skins est les déchets électroniques. ↩


