DragonianVoice
ve api

Chino | Inglés
Este repositorio ha dejado de mantener permanentemente el proyecto de UI y se convertirá en un proyecto LIB puro. La dirección del repositorio de código es: DragonianLib, pero la versión sobre SVC y TTS todavía se lanza en este repositorio.
Este repositorio es: 1. TTS (Tacotron2, Vits, EmotionVits, BertVits2, GPTSovits); 2. SVC (SOVITSSVC, RVC, DiffusionsVC, FishDiffusion, ReflusVC); 3. SVS (Diffsinger) ONNX Framework Razoning Reppertory, actualmente admite llamadas C/CPP/C#.
La última versión de este repositorio se ha vinculado a la discurso de pescado y utiliza el marco GGML para reescribir la discurso de pescado para formar el subproyecto de discurso de pescado.
Nota: Rama habilitada para SVS: MoeVoicestudio MoeVoicestudiocore
Con respecto al soporte de CUDA, visite el repositorio oficial de Onnxruntime.
Después de los experimentos, DML hará que algunos operadores no compatibles en ONNX no denuncien errores cuando se usen, pero devolverán un resultado inesperado, lo que conducirá a errores en los resultados de inferencia de SOVITS3.0 y SOVITS4.0 en DMLEP. Sin embargo, la exportación ONNX en el último repositorio de SoVITS ha reemplazado a estos operadores, por lo que SoVits3.0 y Sovits4.0 Recuperación de recuperación DML Uso, pero el modelo ONNX debe reexportarse utilizando la última versión (2023/7/17) de SovitSonnx Export
Debido a las características de los modelos de difusión y reflujo, si el número total de pasos que infiere es mayor que el número máximo de pasos que entrenó en el modelo (número real de pasos = número total de pasos/aumento de aceleración, este número total de pasos no es el número real de pasos que tomó durante la inferencia, sino k_step), lo que hará que el audio de salida explote o cause un ruido muy alto. Por lo tanto, se recomienda que observe cuidadosamente el maxstep (o k_step_max) en su archivo de configuración del modelo antes de la inferencia.
Este proyecto es un proyecto de código abierto y fuera de línea, y todos los desarrolladores y mantenedores de este proyecto (en adelante denominado contribuyentes) no tienen control sobre este proyecto . Los contribuyentes de este proyecto nunca han proporcionado a ninguna organización o individuo una ayuda en todas las formas, incluida, entre otros, extracción del conjunto de datos, procesamiento del conjunto de datos, soporte de potencia informática, soporte de capacitación, razonamiento, etc.; Los contribuyentes de este proyecto no conocen ni saben el propósito del usuario que usa el proyecto. Por lo tanto, todo el audio sintetizado basado en este proyecto no tiene nada que ver con los contribuyentes de este proyecto. Todos los problemas causados por esto son por responsabilidad del usuario .
Este proyecto en sí no tiene ninguna función de la síntesis del habla, pero solo se usa para comenzar la capacitación y producción del modelo del usuario del modelo ONNX. La capacitación del modelo y la producción del modelo ONNX no están relacionados con los contribuyentes de este proyecto, y son todos los comportamientos de los usuarios. Los contribuyentes de este proyecto no han participado en la capacitación y producción de modelos de todos los usuarios.
Este proyecto se ejecuta completamente fuera de línea y no puede recopilar ninguna información del usuario y no puede obtener datos de entrada del usuario. Por lo tanto, los contribuyentes de este proyecto no son conscientes de todas las entradas y modelos de los usuarios, por lo que no son responsables de ninguna entrada del usuario.
Este proyecto tampoco viene con ningún modelo, y cualquier modelo incluido con la versión secundaria y el modelo utilizado para este proyecto no tiene nada que ver con el desarrollador de este proyecto.
Este proyecto actualmente admite plenamente llamar a sus propios métodos para implementar un razonamiento de la línea de comandos u otro software. Todos son bienvenidos para recomendar relaciones públicas a este proyecto
Otros proyectos del autor: aitoolkits
Si desea participar en el desarrollo, puede unirse al grupo QQ: 263805400 o agregar directamente las relaciones
El modelo debe convertirse a un modelo ONNX. Para obtener más detalles, consulte el repositorio de origen del proyecto que seleccionó. ¡El modelo PTH no se puede usar directamente! ! ! ! ! ! ! ! ! ! ! ! !
Cada rama de este proyecto:
Los supremacistas de XP están extasiados, ¿a quién no le gusta Dragon Girl?
La intención original de este proyecto era realizar la necesidad de varios proyectos de síntesis de voz sin la necesidad del Ministerio de Medio Ambiente, y ahora se planea que se haga como un editor auxiliar para SVC.
Dado que este proyecto es un proyecto "personal" y "no profesional" después de todo, tienes más software profesional, o eres un entusiasta de Python CLI, o eres un gran tiro en el campo relacionado. Sé que este software no es lo suficientemente profesional y es probable que no satisfaga sus necesidades o incluso inútil para usted.
Este proyecto no es un proyecto insustituible. Por el contrario, puede usar varias herramientas para reemplazar las funciones de este proyecto. No espero que este proyecto se convierta en un proyecto líder en campos relacionados. Sigo desarrollando el proyecto con entusiasmo. Pero el entusiasmo siempre desaparecerá por un día, pero el proyecto promete mantener el mantenimiento hasta que mi entusiasmo desaparezca por completo (independientemente de si alguien lo usa, incluso si el número de usuarios es 0)
Puede haber varios problemas en el diseño de este proyecto, por lo que todos también deben ordenar activamente el arroz frito para ayudarme a mejorar las funciones. Aceptaré la mayor parte de la optimización de funciones y experiencia.
Este proyecto es de código abierto y gratis para siempre. Si hay una versión paga de este proyecto en otros lugares, infórmelo de inmediato y no la compre. Este proyecto es gratis para siempre. Si quieres llenar las hojas blancas con Crazy Jueves, puedes ir a Aifa Dian https://afdian.net/a/narusemioshirakana
No se proporciona, la capacitación del modelo es relativamente simple y no hay necesidad de gastar dinero en vano. Simplemente siga el tutorial en línea paso a paso.
- Originalidad. La proporción de sus propias cosas a lo largo del proyecto (para la IA, la creación del uso de modelos que están completamente entrenados por usted le pertenece independientemente; la creación del uso de modelos que son otros pertenecen a los demás). Los aspectos cubiertos incluyen, entre otros, programas, arte, audio, planificación, etc. Por ejemplo, la aplicación de la unidad y otras plantillas del motor para reemplazar las pieles es el desperdicio electrónico.
- Actitud del desarrollador. La actitud del autor es ganar dinero y irse o ser simplemente vano. Por ejemplo, he alcanzado innumerables etiquetas, como "domésticos", "primero", "más fuerte" y "casero", lo que resultó en cosas muy malas o mediocres, y el autor obviamente no tiene idea de hacer el proyecto bien, lo cual es el desperdicio electrónico.
- Oponerse a todos los comportamientos comerciales de los modelos de IA capacitados utilizando conjuntos de datos no autorizados.
Si puede estar seguro de que lo que está haciendo no es un desperdicio electrónico, sino que es legal y conforme, y no hay errores políticos serios, proporcionaré algún apoyo técnico dentro de mi capacidad.
¿El camino chino no es compatible? De hecho, la ontología del proyecto admite las rutas chinas, pero la versión de OnXruntime antes de marzo de 2023 no es compatible con las rutas chinas, porque estas versiones de OnXruntime usan las funciones de la serie A Win32API, y las funciones de la serie A no admiten las rutas no asociadas a los Asesi. Este problema no es algo que pueda resolver o debería resolver. Solo Microsoft puede solucionar este error. Afortunadamente, el último Onnxruntime utiliza funciones de la serie W para resolver el problema de la ruta china.
Debido a la compatibilidad extremadamente pobre de CUDA, se debe instalar y compilarse un programa basado en CUDA al instalar y compilar el programa, o la última versión de CUDA no se ha modificado. Este problema solo se puede esperar a que NVIDIA preste atención a la compatibilidad.
Moevoicestudiocore proporciona llamadas en lenguaje C ++ en forma de lib
Referencia a las siguientes clases correspondientes según sea necesario
# include < Modules/Models/header/Tacotron.hpp >
# include < Modules/Models/header/Vits.hpp >
# include < Modules/Models/header/VitsSvc.hpp >
# include < Modules/Models/header/DiffSvc.hpp >
# include < Modules/Models/header/DiffSinger.hpp >
InferClass::Tacotron2;
InferClass::Vits;
InferClass::VitsSvc;
InferClass::DiffusionSvc;
InferClass::DiffusionSinger;
/*
构造函数第一个是配置文件json
第二个是进度条回调
第三个是参数回调 (若为TTS 此参数为空即可)
第四个参数为设备
使用调用Inference函数即可
*/Para la configuración del modelo, consulte la configuración #Model
Demo: ejemplo de línea de comandos RVC
Detener actualizaciones (debido a la velocidad de descarga y carga): Vocoder & HiddenUnitbert
STOP ACTUALIZACIÓN (porque Huggingface está amurallado): Huggingface
Último almacén: Openi
Exportar el preajuste usted mismo:
input_names debe ser ["source"] , output_names debe ser ["embed"] , dynamic_axes debe ser {"source":[0,2],}input_names debe ser ["c","f0"] , output_names debe ser ["audio"] , dynamic_axes debe ser {"c":[0,1],"f0":[0,1],}input_names debe ser ["x"] , output_names debe ser ["audio"] , dynamic_axes debe ser {"x":[0,1],}El modelo VEC y el modelo Hubert se colocan en la carpeta Hubert, y el modelo Hifigan se coloca en la carpeta Hifigan. Si necesita usar los dos predictores F0, FCPE o RMVPE, debe crear la carpeta F0Predictor en el directorio raíz y colocar el modelo ONNX en ella.
xxx.json es un archivo de configuración para el modelo. Debe escribirse de acuerdo con la plantilla usted mismo, y al mismo tiempo, debe convertir el modelo en ONNX usted mismo. Folder : Guarde el nombre de la carpeta del modeloName : El nombre de la pantalla del modelo en la interfaz de usuarioType : categoría de modeloRate : la tasa de muestreo (debe ser exactamente la misma que cuando estaba entrenando. Si no comprende el motivo, se recomienda aprender conocimiento relacionado con el audio de la computadora) {
"Folder" : "Atri" ,
"Name" : "亚托莉-Tacotron2" ,
"Type" : "Tacotron2" ,
"Rate" : 22050 ,
"Symbol" : "_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" ,
"Cleaner" : "" ,
"AddBlank" : false ,
"Hifigan" : "hifigan"
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Tacotron2中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的hifigan放置到hifigan文件夹
//AddBlank:是否在音素之间插0作为分隔 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Vits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Vits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Pits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Pits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "NyaruTaffy" ,
"Name" : "NyaruTaffy" ,
"Type" : "RVC" ,
"Rate" : 40000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"SoVits2" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"HiddenSize" : 256 ,
"Cluster" : "Index"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 32000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 48000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"SoVits4.0V2" : false ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件)
//SoVits4.0V2: 是否为SoVits4.0V2模型 {
"Folder" : "DiffShiroha" ,
"Name" : "白羽" ,
"Type" : "DiffSvc" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"MelBins" : 128 ,
"Cleaner" : "" ,
"Hifigan" : "nsf_hifigan" ,
"Hubert" : "hubert" ,
"Characters" : [ ] ,
"Pndm" : 100 ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"V2" : true
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Pndm:加速倍数,如果是V1模型则必填且必须为导出时设置的加速倍率
//V2:是否为V2模型,V2模型就是后来我分4个模块导出的那个
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256) {
"Folder" : "utagoe" ,
"Name" : "utagoe" ,
"Type" : "DiffSinger" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hifigan" : "singer_nsf_hifigan" ,
"Characters" : [ ] ,
"MelBins" : 128
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的singer_nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到) {
"Folder" : "HimenoSena" ,
"Name" : "HimenoSena" ,
"Type" : "BertVits" ,
"Symbol" : [
"_" ,
"AA" ,
"E" ,
"EE" ,
"En" ,
"N" ,
"OO" ,
"V" ,
"a" ,
"a:" ,
"aa" ,
"ae" ,
"ah" ,
"ai" ,
"an" ,
"ang" ,
"ao" ,
"aw" ,
"ay" ,
"b" ,
"by" ,
"c" ,
"ch" ,
"d" ,
"dh" ,
"dy" ,
"e" ,
"e:" ,
"eh" ,
"ei" ,
"en" ,
"eng" ,
"er" ,
"ey" ,
"f" ,
"g" ,
"gy" ,
"h" ,
"hh" ,
"hy" ,
"i" ,
"i0" ,
"i:" ,
"ia" ,
"ian" ,
"iang" ,
"iao" ,
"ie" ,
"ih" ,
"in" ,
"ing" ,
"iong" ,
"ir" ,
"iu" ,
"iy" ,
"j" ,
"jh" ,
"k" ,
"ky" ,
"l" ,
"m" ,
"my" ,
"n" ,
"ng" ,
"ny" ,
"o" ,
"o:" ,
"ong" ,
"ou" ,
"ow" ,
"oy" ,
"p" ,
"py" ,
"q" ,
"r" ,
"ry" ,
"s" ,
"sh" ,
"t" ,
"th" ,
"ts" ,
"ty" ,
"u" ,
"u:" ,
"ua" ,
"uai" ,
"uan" ,
"uang" ,
"uh" ,
"ui" ,
"un" ,
"uo" ,
"uw" ,
"v" ,
"van" ,
"ve" ,
"vn" ,
"w" ,
"x" ,
"y" ,
"z" ,
"zh" ,
"zy" ,
"!" ,
"?" ,
"u2026" ,
"," ,
"." ,
"'" ,
"-" ,
"SP" ,
"UNK"
] ,
"Cleaner" : "" ,
"Rate" : 44100 ,
"CharaMix" : true ,
"Characters" : [
"u56fdu89c1u83dcu5b50" ,
"u59ecu91ceu661fu594f" ,
"u65b0u5802u5f69u97f3" ,
"u56dbu6761u51dbu9999" ,
"u5c0fu97a0u7531u4f9d"
] ,
"LanguageMap" : {
"ZH" : [
0 ,
0
] ,
"JP" : [
1 ,
6
] ,
"EN" : [
2 ,
8
]
} ,
"Dict" : "BasicDict" ,
"BertPath" : [
"chinese-roberta-wwm-ext-large" ,
"deberta-v2-large-japanese" ,
"bert-base-japanese-v3"
]
} // ${xxx}是什么意思大家应该都知道吧,总之以下是多个不同项目需要的模型文件(需要放置在对应的模型文件夹下)。
// Tacotron2:
${Folder} _decoder_iter.onnx
${Folder} _encoder.onnx
${Folder} _postnet.onnx
// Vits: 单角色VITS
${Folder} _dec.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// Vits: 多角色VITS
${Folder} _dec.onnx
${Folder} _emb.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// SoVits:
${Folder} _SoVits.onnx
// RVC:
${Folder} _RVC.onnx
// DiffSvc:
${Folder} _diffSvc.onnx
// DiffSvc: V2
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
${Folder} _after.onnx
// DiffSinger: OpenVpiVersion
${Folder} _diffSinger.onnx
// DiffSinger:
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
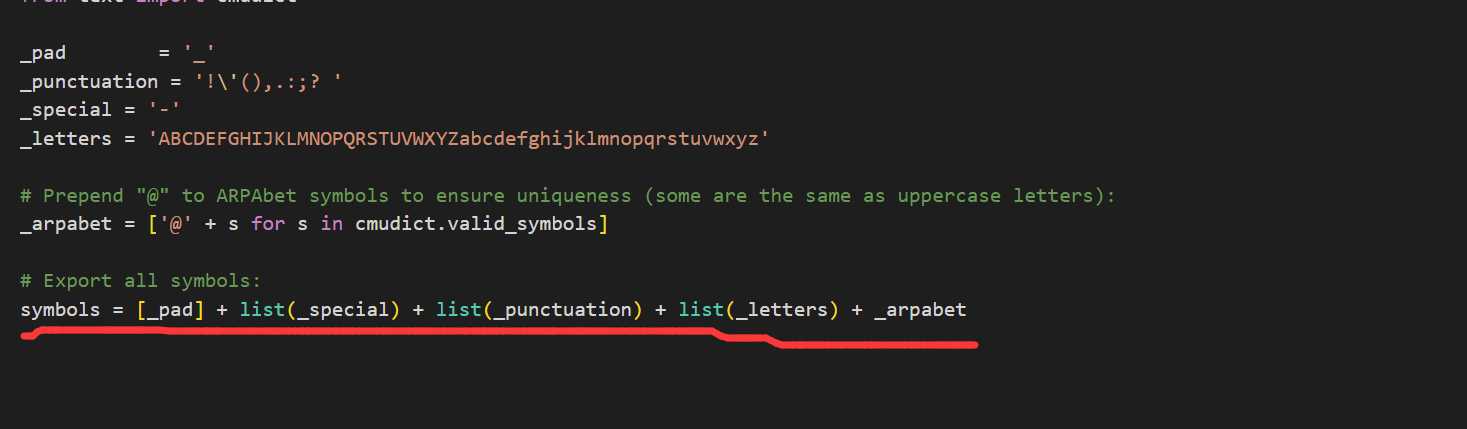
${Folder} _after.onnx例如:_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
打开你训练模型的项目,打开textsymbol.py,如图按照划线的List顺序将上面的4个字符串连接即可
/*
Cleaner请放置于根目录的Cleaners文件夹内,应该是一个按照要求定义的动态库(.dll),dll应当命名为Cleaner名,Cleaner名即为模型定义Json文件中Cleaner一栏填写的内容。
所有的插件dll需要定义以下函数,函数名必须为PluginMain,Dll名必须为插件名(或Cleaner名):
*/
const wchar_t * PluginMain ( const wchar_t *);
// 该接口只要求输入输出一致,并不要求功能一致,也就是说,你可以在改Dll中实现任何想要的功能,比方说ChatGpt,机器翻译等等。
// 以ChatGpt为例,PluginMain函数传入了一个输入字符串input,将该输入传入ChatGpt,再将ChatGpt的输出传入PluginMain,最后返回输出。
wchar_t * PluginMain ( wchar_t * input){
wchar_t * tmpOutput = ChatGpt (input);
return Clean (tmpOutput);
}
// 注意:导出dll时请使用 extern "C" 关键字来防止C++语言的破坏性命名。 git clone https: // github.com/NaruseMioShirakana/MoeVoiceStudio.git
//自行配置OnnxRuntime和FFMPEG的Dll
//使用VisualStudio构建Ninguna organización o individuo puede infringir los derechos de retrato de otros vilipendiando, difamando o utilizando tecnología de la información para forjarlos. El retrato del titular de la derecha del retrato no se producirá, utilizará o revelará sin el consentimiento del titular de la derecha del retrato, excepto como lo proporciona la ley. Sin el consentimiento del titular de la derecha del retrato, el titular adecuado del trabajo del retrato no utilizará ni revelará el retrato del titular del derecho del retrato publicando, copiando, emitiendo, alquiler, exhibición, etc. La protección de las voces de la persona natural estará sujeta a las disposiciones relevantes sobre la protección de los derechos de los retratos.
[Derecho de reputación] Los sujetos civiles disfrutan del derecho a la reputación. Ninguna organización o individuo puede infringir los derechos de reputación de otros insultando, calumniando u otros medios.
[Las obras infringen los derechos de reputación] Si las obras literarias y artísticas publicadas por el autor son descritas por personas reales o personas específicas, y contienen contenido insultante o exigente, lo que infringe los derechos de reputación de los demás, la víctima tiene derecho a solicitar al autor que tenga responsabilidad civil de acuerdo con la ley. Las obras literarias y artísticas publicadas por el autor no describen a una persona específica como objeto de descripción, y solo si las parcelas son similares a la situación de la persona específica, no tendrán responsabilidad civil.
Los materiales de imagen utilizados por Moess se derivan de:
Los criterios para juzgar bajos ingresos son: cualquier contenido generado mediante el uso de mucha IA, el contenido original es bajo, el significado es desconocido, el contenido es de baja calidad, etc. ↩
Criterios de juicio E-SPAM: 1. Originalidad. La proporción de sus propias cosas a lo largo del proyecto (para la IA, la creación del uso de modelos que están completamente entrenados por usted le pertenece independientemente; la creación del uso de modelos que son otros pertenecen a los demás). Los aspectos cubiertos incluyen, entre otros, programas, arte, audio, planificación, etc. Por ejemplo, la aplicación de la unidad y otras plantillas del motor para reemplazar las pieles es el desperdicio electrónico. ↩


