DragonianVoice
ve api

Chinês | Inglês
Esse repositório parou permanentemente de manter o projeto da interface do usuário e se tornará um projeto Puro Lib. O endereço do repositório de código é: DragonianLib, mas o lançamento sobre SVC e TTS ainda é lançado neste repositório.
Este repositório é: 1. TTS (Tacotron2, Vits, emocionalVits, Bertvits2, GptSovits); 2. SVC (SOVITSVC, RVC, DIFFUSIONSVC, FISHDIFFUSTE, ALFLOWSVC); 3. SVS (DiffSinger) OnNX Framework Raciocination Repository, atualmente suporta chamadas C/CPP/C#.
A versão mais recente deste repositório foi vinculada à fala de peixes e usa a estrutura GGML para reescrever a fala de peixes para formar o subproject de discurso de peixe.cpp
Nota: Ramo habilitado para SVS: Moevoicestudio moevoicestudiocore
Em relação ao suporte da CUDA, visite o repositório oficial do OnnxRuntime.
Após as experiências, o DML fará com que alguns operadores não suportados no ONNX não relatem erros quando usados, mas retornarão um resultado inesperado, o que levará a erros nos resultados da inferência do SoVits3.0 e SoVits4.0 no DMLEP. No entanto, a exportação ONNX no mais recente repositório Sovits substituiu esses operadores, portanto, o uso de DML de suporte a Sovits3.0 e Sovits4.0, mas o modelo ONNX deve ser reexportado usando a versão mais recente (2023/7/17) do Sovitsonx Export
Devido às características dos modelos de difusão e reflexão, se o número total de etapas que você inferir for maior que o número máximo de etapas que você treinou no modelo (número real de etapas = número total de etapas/ampliação da aceleração, esse número total de etapas não é o número real de etapas que você tomou durante a inferência, mas K_STEP), o que causará a saída de saída para explodir ou causar muito ruído. Portanto, recomenda -se que você observe cuidadosamente o MaxStep (ou K_Step_Max) no seu arquivo de configuração do modelo antes da inferência.
Este projeto é um projeto de código aberto e offline, e todos os desenvolvedores e mantenedores deste projeto (a seguir denominados colaboradores) não têm controle sobre este projeto . Os colaboradores deste projeto nunca forneceram nenhuma organização ou indivíduo com qualquer ajuda em todas as formas, incluindo, entre outros, extração de conjuntos de dados, processamento de conjuntos de dados, suporte ao poder de computação, suporte de treinamento, raciocínio, etc.; Os colaboradores deste projeto não conhecem ou conhecem o objetivo do usuário usando o projeto. Portanto, todo o áudio sintetizado com base neste projeto não tem nada a ver com os colaboradores deste projeto. Todos os problemas causados por isso estão por responsabilidade do usuário .
Este projeto em si não tem nenhuma função da síntese de fala, mas é usada apenas para iniciar o treinamento e a produção do ONNX do próprio usuário. O treinamento do modelo e a produção do modelo ONNX não estão relacionados aos colaboradores deste projeto e são todos os comportamentos dos usuários. Os colaboradores deste projeto não participaram do treinamento e produção de todos os usuários.
Este projeto é executado completamente offline e não pode coletar nenhuma informação do usuário e não pode obter dados de entrada do usuário. Portanto, os colaboradores deste projeto não estão cientes de todas as entradas e modelos do usuário, portanto não são responsáveis por nenhuma entrada do usuário.
Este projeto também não vem com nenhum modelo e nenhum modelo incluído na versão secundária e o modelo usado para este projeto não têm nada a ver com o desenvolvedor deste projeto.
Atualmente, este projeto suporta totalmente a chamada de seus próprios métodos para implementar o raciocínio da linha de comando ou outro software. Todos são convidados a recomendar PR para este projeto
Outros projetos do autor: Aitoolkits
Se você deseja participar do desenvolvimento, pode ingressar no grupo QQ: 263805400 ou adicionar diretamente PR
O modelo precisa ser convertido em um modelo ONNX. Para detalhes, consulte o repositório de origem do projeto que você selecionou. O modelo PTH não pode ser usado diretamente! ! ! ! ! ! ! ! ! ! ! ! !
Cada ramo deste projeto:
Os supremacistas XP estão em êxtase, quem não gosta de Dragon Girl?
A intenção original deste projeto era perceber a necessidade de vários projetos de síntese de voz sem a necessidade do Ministério do Meio Ambiente, e agora está planejado para ser feito como editor auxiliar da SVC.
Como este projeto é um projeto "pessoal" e "não profissional", você tem mais software profissional ou é um entusiasta da Python CLI, ou é um figurão no campo relacionado. Sei que este software não é profissional o suficiente e provavelmente não atende às suas necessidades ou mesmo inúteis para você.
Este projeto não é um projeto insubstituível. Pelo contrário, você pode usar várias ferramentas para substituir as funções deste projeto. Não espero que este projeto se torne um projeto líder em áreas relacionadas. Eu apenas continuo desenvolvendo o projeto com entusiasmo. Mas o entusiasmo sempre desaparecerá por um dia, mas o projeto promete manter a manutenção até que meu entusiasmo desapareça completamente (independentemente de alguém usar, mesmo que o número de usuários seja 0)
Pode haver vários problemas no design deste projeto, para que todos também precisem pedir ativamente arroz frito para me ajudar a melhorar as funções. Aceitarei a maior parte da otimização de funções e experiência.
Este projeto é de código aberto e grátis para sempre. Se houver uma versão paga deste projeto em outros lugares, denuncie -o imediatamente e não o compre. Este projeto é gratuito para sempre. Se você quiser encher as folhas brancas com quinta -feira louca, você pode ir para AIFA Dian https://afdian.net/a/narusemioshirakana
Não é fornecido, o treinamento do modelo é relativamente simples e não há necessidade de gastar dinheiro em vão. Basta seguir o tutorial on -line passo a passo.
- Originalidade. A proporção de suas próprias coisas ao longo do projeto (para a IA, a criação do uso de modelos totalmente treinados por você pertencem independentemente a você; a criação do uso de modelos que são outros pertencem a outros). Os aspectos abordados incluem, entre outros, programas, arte, áudio, planejamento etc., por exemplo, aplicar a unidade e outros modelos do motor para substituir as peles é o lixo eletrônico.
- Atitude do desenvolvedor. A atitude do autor é ganhar dinheiro e sair ou ser simplesmente vaidoso. Por exemplo, eu atingi inúmeras tags, como "doméstico", "primeiro", "mais forte" e "caseiro", o que resultou em coisas muito ruins ou medíocres, e o autor obviamente não tem idéia de fazer bem o projeto, que é um lixo eletrônico.
- Opor a todos os comportamentos comerciais dos modelos de IA treinados usando conjuntos de dados não autorizados.
Se você pode ter certeza de que o que está fazendo não é um lixo eletrônico, mas é legal e compatível, e não há erros políticos graves, fornecerei algum suporte técnico dentro da minha capacidade.
O caminho chinês não é suportado? De fato, a ontologia do projeto suporta caminhos chineses, mas a versão do OnnxRuntime antes de março de 2023 não suporta caminhos chineses, porque essas versões do OnNxRuntime usam as funções da série A da Win32API e as funções da série A não suportam caminhos não codificados por iv-codificados. Esse problema não é algo que eu possa resolver ou devo resolver. Somente a Microsoft pode corrigir este bug. Felizmente, o mais recente OnnxRuntime usa as funções da série W para resolver o problema do caminho chinês.
Devido à compatibilidade extremamente ruim do CUDA, um programa baseado em CUDA deve ser instalado e compilado ao instalar e compilar o programa, ou a versão mais recente do CUDA não foi modificada. Esse problema só pode ser esperado que a NVIDIA prestasse atenção à compatibilidade.
Moevoicestudiocore fornece chamadas na linguagem C ++ na forma de lib
Referenciar as seguintes classes correspondentes conforme necessário
# include < Modules/Models/header/Tacotron.hpp >
# include < Modules/Models/header/Vits.hpp >
# include < Modules/Models/header/VitsSvc.hpp >
# include < Modules/Models/header/DiffSvc.hpp >
# include < Modules/Models/header/DiffSinger.hpp >
InferClass::Tacotron2;
InferClass::Vits;
InferClass::VitsSvc;
InferClass::DiffusionSvc;
InferClass::DiffusionSinger;
/*
构造函数第一个是配置文件json
第二个是进度条回调
第三个是参数回调 (若为TTS 此参数为空即可)
第四个参数为设备
使用调用Inference函数即可
*/Para configuração do modelo, consulte a configuração #Model
Demo: Exemplo de linha de comando RVC
Stop Atualizações (devido à velocidade de download e upload): Vocoder & Hiddenitnitbert
Stop Atualize (porque o Huggingface está murado): Huggingface
Último armazém: openi
Exporte a predefinição:
input_names deve ser ["source"] , output_names deve ser ["embed"] , dynamic_axes deve ser {"source":[0,2],}input_names deve ser ["c","f0"] , output_names deve ser ["audio"] , dynamic_axes deve ser {"c":[0,1],"f0":[0,1],}input_names deve ser ["x"] , output_names deve ser ["audio"] , dynamic_axes deve ser {"x":[0,1],}O modelo VEC e o modelo Hubert são colocados na pasta Hubert, e o modelo Hifigan é colocado na pasta Hifigan. Se você precisar usar os dois preditores F0, FCPE ou RMVPE, precisará criar a pasta F0Predittor no diretório raiz e colocar o modelo ONNX nele.
xxx.json é um arquivo de configuração para o modelo. Ele precisa ser escrito de acordo com o modelo e, ao mesmo tempo, precisa converter o modelo para o ONNX. Folder : salve o nome da pasta do modeloName : o nome de exibição do modelo na interface do usuárioType : categoria de modeloRate : a taxa de amostragem (deve ser exatamente a mesma de quando você estava treinando. Se você não entende o motivo, é recomendável aprender conhecimento relacionado ao áudio do computador) {
"Folder" : "Atri" ,
"Name" : "亚托莉-Tacotron2" ,
"Type" : "Tacotron2" ,
"Rate" : 22050 ,
"Symbol" : "_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" ,
"Cleaner" : "" ,
"AddBlank" : false ,
"Hifigan" : "hifigan"
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Tacotron2中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的hifigan放置到hifigan文件夹
//AddBlank:是否在音素之间插0作为分隔 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Vits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Vits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Pits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Pits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "NyaruTaffy" ,
"Name" : "NyaruTaffy" ,
"Type" : "RVC" ,
"Rate" : 40000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"SoVits2" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"HiddenSize" : 256 ,
"Cluster" : "Index"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 32000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 48000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"SoVits4.0V2" : false ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件)
//SoVits4.0V2: 是否为SoVits4.0V2模型 {
"Folder" : "DiffShiroha" ,
"Name" : "白羽" ,
"Type" : "DiffSvc" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"MelBins" : 128 ,
"Cleaner" : "" ,
"Hifigan" : "nsf_hifigan" ,
"Hubert" : "hubert" ,
"Characters" : [ ] ,
"Pndm" : 100 ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"V2" : true
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Pndm:加速倍数,如果是V1模型则必填且必须为导出时设置的加速倍率
//V2:是否为V2模型,V2模型就是后来我分4个模块导出的那个
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256) {
"Folder" : "utagoe" ,
"Name" : "utagoe" ,
"Type" : "DiffSinger" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hifigan" : "singer_nsf_hifigan" ,
"Characters" : [ ] ,
"MelBins" : 128
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的singer_nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到) {
"Folder" : "HimenoSena" ,
"Name" : "HimenoSena" ,
"Type" : "BertVits" ,
"Symbol" : [
"_" ,
"AA" ,
"E" ,
"EE" ,
"En" ,
"N" ,
"OO" ,
"V" ,
"a" ,
"a:" ,
"aa" ,
"ae" ,
"ah" ,
"ai" ,
"an" ,
"ang" ,
"ao" ,
"aw" ,
"ay" ,
"b" ,
"by" ,
"c" ,
"ch" ,
"d" ,
"dh" ,
"dy" ,
"e" ,
"e:" ,
"eh" ,
"ei" ,
"en" ,
"eng" ,
"er" ,
"ey" ,
"f" ,
"g" ,
"gy" ,
"h" ,
"hh" ,
"hy" ,
"i" ,
"i0" ,
"i:" ,
"ia" ,
"ian" ,
"iang" ,
"iao" ,
"ie" ,
"ih" ,
"in" ,
"ing" ,
"iong" ,
"ir" ,
"iu" ,
"iy" ,
"j" ,
"jh" ,
"k" ,
"ky" ,
"l" ,
"m" ,
"my" ,
"n" ,
"ng" ,
"ny" ,
"o" ,
"o:" ,
"ong" ,
"ou" ,
"ow" ,
"oy" ,
"p" ,
"py" ,
"q" ,
"r" ,
"ry" ,
"s" ,
"sh" ,
"t" ,
"th" ,
"ts" ,
"ty" ,
"u" ,
"u:" ,
"ua" ,
"uai" ,
"uan" ,
"uang" ,
"uh" ,
"ui" ,
"un" ,
"uo" ,
"uw" ,
"v" ,
"van" ,
"ve" ,
"vn" ,
"w" ,
"x" ,
"y" ,
"z" ,
"zh" ,
"zy" ,
"!" ,
"?" ,
"u2026" ,
"," ,
"." ,
"'" ,
"-" ,
"SP" ,
"UNK"
] ,
"Cleaner" : "" ,
"Rate" : 44100 ,
"CharaMix" : true ,
"Characters" : [
"u56fdu89c1u83dcu5b50" ,
"u59ecu91ceu661fu594f" ,
"u65b0u5802u5f69u97f3" ,
"u56dbu6761u51dbu9999" ,
"u5c0fu97a0u7531u4f9d"
] ,
"LanguageMap" : {
"ZH" : [
0 ,
0
] ,
"JP" : [
1 ,
6
] ,
"EN" : [
2 ,
8
]
} ,
"Dict" : "BasicDict" ,
"BertPath" : [
"chinese-roberta-wwm-ext-large" ,
"deberta-v2-large-japanese" ,
"bert-base-japanese-v3"
]
} // ${xxx}是什么意思大家应该都知道吧,总之以下是多个不同项目需要的模型文件(需要放置在对应的模型文件夹下)。
// Tacotron2:
${Folder} _decoder_iter.onnx
${Folder} _encoder.onnx
${Folder} _postnet.onnx
// Vits: 单角色VITS
${Folder} _dec.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// Vits: 多角色VITS
${Folder} _dec.onnx
${Folder} _emb.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// SoVits:
${Folder} _SoVits.onnx
// RVC:
${Folder} _RVC.onnx
// DiffSvc:
${Folder} _diffSvc.onnx
// DiffSvc: V2
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
${Folder} _after.onnx
// DiffSinger: OpenVpiVersion
${Folder} _diffSinger.onnx
// DiffSinger:
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
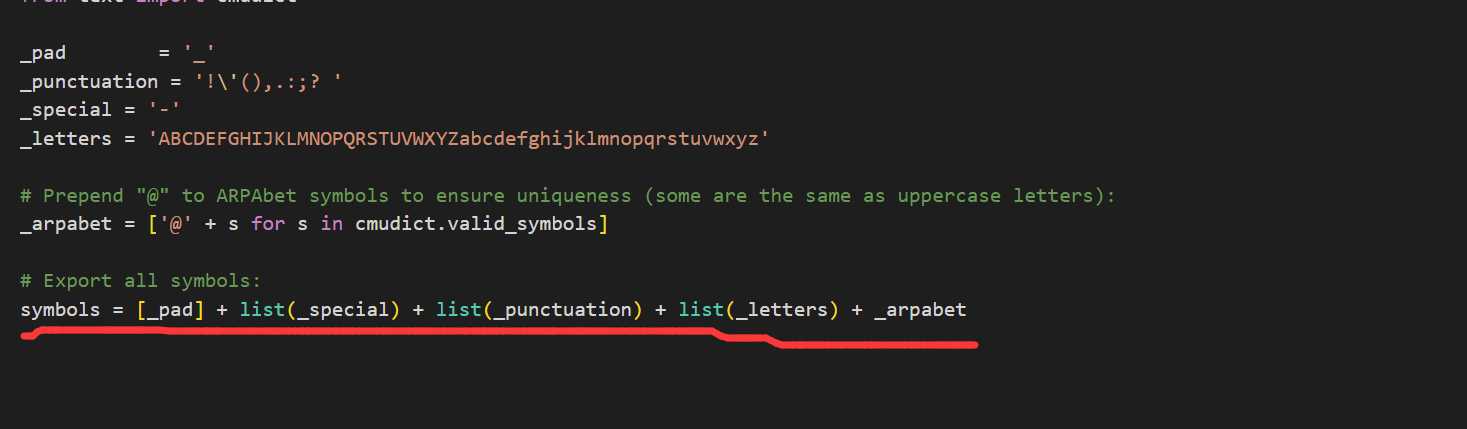
${Folder} _after.onnx例如:_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
打开你训练模型的项目,打开textsymbol.py,如图按照划线的List顺序将上面的4个字符串连接即可
/*
Cleaner请放置于根目录的Cleaners文件夹内,应该是一个按照要求定义的动态库(.dll),dll应当命名为Cleaner名,Cleaner名即为模型定义Json文件中Cleaner一栏填写的内容。
所有的插件dll需要定义以下函数,函数名必须为PluginMain,Dll名必须为插件名(或Cleaner名):
*/
const wchar_t * PluginMain ( const wchar_t *);
// 该接口只要求输入输出一致,并不要求功能一致,也就是说,你可以在改Dll中实现任何想要的功能,比方说ChatGpt,机器翻译等等。
// 以ChatGpt为例,PluginMain函数传入了一个输入字符串input,将该输入传入ChatGpt,再将ChatGpt的输出传入PluginMain,最后返回输出。
wchar_t * PluginMain ( wchar_t * input){
wchar_t * tmpOutput = ChatGpt (input);
return Clean (tmpOutput);
}
// 注意:导出dll时请使用 extern "C" 关键字来防止C++语言的破坏性命名。 git clone https: // github.com/NaruseMioShirakana/MoeVoiceStudio.git
//自行配置OnnxRuntime和FFMPEG的Dll
//使用VisualStudio构建Nenhuma organização ou indivíduo pode infringir os direitos de retrato de outras pessoas, difamando, difamando ou usando a tecnologia da informação para forjá -los. O retrato do titular direito do retrato não deve ser produzido, usado ou divulgado sem o consentimento do titular direito do retrato, exceto quando disposto em contrário por lei. Sem o consentimento do titular direito do retrato, o detentor direito do trabalho de retrato não deve usar ou divulgar o retrato do retrato do titular da publicação, copiando, emitindo, alugando, exposição etc. A proteção das vozes da pessoa natural deve estar sujeita às disposições relevantes sobre a proteção dos direitos de retrato.
[Reputação direita] Os assuntos civis desfrutam do direito à reputação. Nenhuma organização ou indivíduo pode infringir os direitos de reputação de outras pessoas, insultos, difamando ou outros meios.
[Trabalhos infringem os direitos de reputação] Se as obras literárias e artísticas publicadas pelo agressor forem descritas por pessoas reais ou pessoas específicas e conter conteúdo ofensivo ou caluniado, que viola os direitos de reputação de outros, a vítima tem o direito de solicitar que o agressor tenha responsabilidade civil de acordo com a lei. Os trabalhos literários e artísticos publicados pelo agressor não descrevem uma pessoa específica como o objeto de descrição e somente se as parcelas forem semelhantes à situação da pessoa específica, elas não terão responsabilidade civil.
Os materiais de imagem usados por moess são derivados de:
Os critérios para julgar a baixa renda são: qualquer conteúdo gerado usando muita IA, o conteúdo original é baixo, o significado é desconhecido, o conteúdo é de baixa qualidade, etc. ↩
Critérios de julgamento de spam e-spam: 1. Originalidade. A proporção de suas próprias coisas ao longo do projeto (para a IA, a criação do uso de modelos totalmente treinados por você pertencem independentemente a você; a criação do uso de modelos que são outros pertencem a outros). Os aspectos abordados incluem, entre outros, programas, arte, áudio, planejamento etc., por exemplo, aplicar a unidade e outros modelos do motor para substituir as peles é o lixo eletrônico. ↩


