DragonianVoice
ve api

الصينية | إنجليزي
توقف هذا المستودع بشكل دائم عن الحفاظ على مشروع واجهة المستخدم وسيصبح مشروع LIB نقي. عنوان مستودع الكود هو: Dragonianlib ، ولكن لا يزال إصدار SVC و TTS في هذا المستودع.
هذا المستودع هو: 1. 2. SVC (Sovitssvc ، RVC ، DiffusionsVC ، FishDiffusion ، resterowsvc) ؛ 3. SVS (Diffsinger) ONNX Framework التفكير ، يدعم حاليًا مكالمات C/CPP/C#.
تم ربط أحدث إصدار من هذا المستودع بأسماك الكلام ، ويستخدم إطار عمل GGML لإعادة كتابة خطاب الأسماك لتشكيل مكبوت الأسماك.
ملاحظة: الفرع الذي يدعم SVS: Moevoicestudio Moevoicestudiocore
فيما يتعلق بدعم CUDA ، يرجى زيارة مستودع OnNxRuntime الرسمي.
بعد التجارب ، سوف يتسبب DML في عدم الإبلاغ عن بعض المشغلين غير المدعومين في ONNX عن الأخطاء عند استخدامها ، ولكن سيعيد نتيجة غير متوقعة ، مما سيؤدي إلى أخطاء في نتائج الاستدلال لـ SOVITS3.0 و SOVITS4.0 على DMLEP. ومع ذلك ، فإن تصدير ONNX في أحدث مستودع SOVITS قد حل محل هؤلاء المشغلين ، لذلك SOVITS3.0 و SOVITS4.0 دعم DML DEST ، ولكن يجب إعادة تصدير نموذج ONNX باستخدام أحدث إصدار (2023/7/17) من SOVITSONNX EXPORT
نظرًا لخصائص النماذج الناشئة والتراجع ، إذا كان العدد الإجمالي للخطوات التي تستنتجها أكبر من الحد الأقصى لعدد الخطوات التي دربتها في النموذج (العدد الفعلي للخطوات = إجمالي عدد الخطوات/تكبير التسارع ، فإن هذا العدد الإجمالي للخطوات ليس هو العدد الفعلي للخطوات التي اتخذتها أثناء الاستدلال ، ولكن K_STEP) ، والتي من شأنها أن تتسبب في استكشاف صوت المخرجات أو يسببها في الضوضاء العالية للغاية. لذلك ، يوصى بمراقبة MaxStep (أو k_step_max) بعناية في ملف تكوين النموذج الخاص بك قبل الاستدلال.
هذا المشروع هو مشروع مفتوح المصدر وغير متصل ، وليس لدى جميع المطورين والمحاربين من هذا المشروع (المشار إليه فيما يلي باسم المساهمين) أي سيطرة على هذا المشروع . لم يقدم المساهمون في هذا المشروع أي مؤسسة أو فرد مع جميع أشكال المساعدة بما في ذلك على سبيل المثال لا الحصر استخراج مجموعة البيانات ، ومعالجة مجموعة البيانات ، ودعم الطاقة الحاسوبية ، ودعم التدريب ، والتفكير ، وما إلى ذلك ؛ لا يعرف المساهمون في هذا المشروع أو يعرفون الغرض من المستخدم باستخدام المشروع. لذلك ، لا علاقة لجميع الصوت الذي تم تصنيعه بناءً على هذا المشروع مع المساهمين في هذا المشروع. جميع المشكلات الناجمة عن ذلك على مسؤولية المستخدم .
لا يحتوي هذا المشروع نفسه على أي وظيفة لتوليف الكلام ، ولكن يتم استخدامه فقط لبدء تدريب المستخدم وإنتاج نموذج ONNX. لا يرتبط التدريب النموذجي وإنتاج نموذج ONNX بالمساهمين في هذا المشروع ، وهما جميع السلوكيات الخاصة بالمستخدمين. لم يشارك المساهمون في هذا المشروع في تدريب وإنتاج جميع المستخدمين.
يتم تشغيل هذا المشروع بشكل غير متصل تمامًا ولا يمكنه جمع أي معلومات مستخدم ولا يمكن الحصول على بيانات إدخال المستخدم. لذلك ، فإن المساهمين في هذا المشروع ليسوا على دراية بجميع مدخلات المستخدم والنماذج ، لذلك فهي ليست مسؤولة عن أي مدخلات مستخدم.
لا يأتي هذا المشروع أيضًا مع أي نموذج ، وأي نموذج مدرج في الإصدار الثانوي والنموذج المستخدم لهذا المشروع لا علاقة له بمطور هذا المشروع.
يدعم هذا المشروع حاليًا استدعاء أساليبه الخاصة لتنفيذ تفكير سطر الأوامر أو البرامج الأخرى. الجميع مرحب بهم للتوصية بالعلاقات العامة لهذا المشروع
مشاريع المؤلف الأخرى: Aitoolkits
إذا كنت ترغب في المشاركة في التطوير ، يمكنك الانضمام إلى مجموعة QQ: 263805400 أو إضافة العلاقات العامة مباشرة
يجب تحويل النموذج إلى نموذج ONNX. للحصول على التفاصيل ، راجع مستودع المصدر للمشروع الذي حددته. لا يمكن استخدام نموذج PTH مباشرة! ! ! ! ! ! ! ! ! ! ! ! !
كل فرع من هذا المشروع:
Supremacists XP نشوة ، من لا يحب Dragon Girl؟
كانت النية الأصلية لهذا المشروع هي إدراك الحاجة إلى العديد من مشاريع توليف الصوت دون الحاجة إلى وزارة البيئة ، والآن من المخطط أن يتم تقديمها كمحرر مساعد لـ SVC.
نظرًا لأن هذا المشروع هو مشروع "شخصي" و "غير مهني" بعد كل شيء ، لديك المزيد من البرامج الاحترافية ، أو أنت متحمس لـ Python CLI ، أو أنت لقطة كبيرة في الحقل ذي الصلة. أعلم أن هذا البرنامج ليس احترافيًا بما فيه الكفاية ومن المحتمل ألا يلبي احتياجاتك أو حتى عديمة الفائدة لك.
هذا المشروع ليس مشروعًا لا يمكن الاستغناء عنه. على العكس من ذلك ، يمكنك استخدام أدوات مختلفة لاستبدال وظائف هذا المشروع. لا أتوقع أن يصبح هذا المشروع مشروعًا رائدًا في الحقول ذات الصلة. أنا فقط أواصل تطوير المشروع بحماس. لكن الحماس سيختفي دائمًا ليوم واحد ، لكن المشروع يعد بالاحتفاظ بالصيانة حتى يختفي حماسي تمامًا (بغض النظر عما إذا كان أي شخص يستخدمه ، حتى لو كان عدد المستخدمين 0)
قد تكون هناك مشاكل مختلفة في تصميم هذا المشروع ، لذلك يحتاج الجميع أيضًا إلى طلب الأرز المقلي بنشاط لمساعدتي في تحسين الوظائف. سوف أقبل معظم تحسين الوظائف والخبرة.
هذا المشروع مفتوح المصدر ومجاني إلى الأبد. إذا كان هناك نسخة مدفوعة من هذا المشروع في أماكن أخرى ، فيرجى الإبلاغ عنها على الفور وعدم شرائها. هذا المشروع مجاني إلى الأبد. إذا كنت ترغب في ملء الأوراق البيضاء مع يوم الخميس المجنون ، فيمكنك الذهاب إلى AIFA Dian https://afdian.net/a/narusemioshirakana
لم يتم توفيره ، وتدريب النموذج بسيط نسبيًا ، وليس هناك حاجة لإنفاق المال دون جدوى. فقط اتبع البرنامج التعليمي عبر الإنترنت خطوة بخطوة.
- أصالة. نسبة الأشياء الخاصة بك في جميع أنحاء المشروع (من أجل الذكاء الاصطناعي ، فإن إنشاء نماذج مدربة تمامًا من قبلك تنتمي إليك بشكل مستقل ؛ إن إنشاء نماذج أخرى تنتمي إلى الآخرين). تشمل الجوانب المغطاة على سبيل المثال لا الحصر البرامج والفن والصوت والتخطيط وما إلى ذلك ، على سبيل المثال ، تطبيق الوحدة وقوالب المحرك الأخرى لاستبدال الجلود هو النفايات الإلكترونية.
- موقف المطور. موقف المؤلف هو كسب المال والمغادرة أو أن يكون بلا جدوى. على سبيل المثال ، لقد ضربت علامات لا حصر لها ، مثل "المحلي" ، "الأول" ، "الأقوى" و "محلية الصنع" ، والتي أدت إلى أشياء سيئة أو متواضعة للغاية ، ومن الواضح أن المؤلف ليس لديه فكرة عن جعل المشروع جيدًا ، وهو نفايات إلكترونية.
- معارضة جميع السلوكيات التجارية لنماذج الذكاء الاصطناعى المدربين باستخدام مجموعات بيانات غير مصرح بها.
إذا تمكنت من التأكد من أن ما تفعله ليس مضيعة إلكترونية ، ولكنه قانوني ومتوافق ، ولا توجد أخطاء سياسية خطيرة ، سأقدم بعض الدعم الفني ضمن قدرتي.
المسار الصيني غير مدعوم؟ في الواقع ، يدعم مشروع Ontology المسارات الصينية ، لكن إصدار OnNxruntime قبل مارس 2023 لا يدعم المسارات الصينية ، لأن هذه الإصدارات من OnNxruntime تستخدم وظائف A-Series في WIN32API ، ولا تدعم وظائف السلسلة A المسارات غير المشتركة. هذه المشكلة ليست شيئًا يمكنني حله أو يجب حله. يمكن فقط لـ Microsoft إصلاح هذا الخطأ. لحسن الحظ ، يستخدم أحدث OnNxRuntime وظائف W لحل مشكلة المسار الصيني.
نظرًا للتوافق السيئ للغاية لـ CUDA ، يجب تثبيت برنامج قائم على CUDA وتجميعه عند تثبيت البرنامج وتجميعه ، أو لم يتم تعديل إصدار CUDA الأخير. لا يمكن انتظار هذه المشكلة إلا من أجل NVIDIA للانتباه إلى التوافق.
يوفر Moevoicestudiocore مكالمات بلغة C ++ في شكل lib
الرجوع إلى الفئات المقابلة التالية حسب الحاجة
# include < Modules/Models/header/Tacotron.hpp >
# include < Modules/Models/header/Vits.hpp >
# include < Modules/Models/header/VitsSvc.hpp >
# include < Modules/Models/header/DiffSvc.hpp >
# include < Modules/Models/header/DiffSinger.hpp >
InferClass::Tacotron2;
InferClass::Vits;
InferClass::VitsSvc;
InferClass::DiffusionSvc;
InferClass::DiffusionSinger;
/*
构造函数第一个是配置文件json
第二个是进度条回调
第三个是参数回调 (若为TTS 此参数为空即可)
第四个参数为设备
使用调用Inference函数即可
*/لتكوين النموذج ، يرجى الرجوع إلى تكوين #Model
العرض التوضيحي: مثال سطر أوامر RVC
توقف التحديثات (بسبب التنزيل وتحميل سرعة): Vocoder & Hiddenunitbert
توقف التحديث (لأن Huggingface مسورة): Huggingface
أحدث مستودعات: Openi
قم بتصدير الإعداد المسبق لنفسك:
input_names ["source"] ، output_names يجب أن تكون ["embed"] ، dynamic_axes يجب أن تكون {"source":[0,2],}input_names ["c","f0"] ، output_names يجب أن يكون ["audio"] ، dynamic_axes يجب أن يكون {"c":[0,1],"f0":[0,1],}input_names ["x"] ، output_names ["audio"] ، يجب أن تكون dynamic_axes {"x":[0,1],}يتم وضع نموذج VEC ونموذج Hubert في مجلد Hubert ، ويوضع نموذج Hifigan في مجلد Hifigan. إذا كنت بحاجة إلى استخدام اثنين من المتنبئين F0 ، FCPE أو RMVPE ، فأنت بحاجة إلى إنشاء مجلد F0Predictor في دليل الجذر ووضع نموذج ONNX فيه.
xxx.json هو ملف تكوين للنموذج. يجب كتابتها وفقًا للقالب بنفسك ، وفي الوقت نفسه ، يحتاج إلى تحويل النموذج إلى Onnx بنفسك. Folder : احفظ اسم المجلد للنموذجName : اسم عرض النموذج في واجهة المستخدمType : فئة النموذجRate : معدل أخذ العينات (يجب أن يكون هو نفسه تمامًا كما كنت تتدرب. إذا كنت لا تفهم السبب ، فمن المستحسن تعلم المعرفة المتعلقة بصوت الكمبيوتر) {
"Folder" : "Atri" ,
"Name" : "亚托莉-Tacotron2" ,
"Type" : "Tacotron2" ,
"Rate" : 22050 ,
"Symbol" : "_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" ,
"Cleaner" : "" ,
"AddBlank" : false ,
"Hifigan" : "hifigan"
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Tacotron2中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的hifigan放置到hifigan文件夹
//AddBlank:是否在音素之间插0作为分隔 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Vits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Vits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Pits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Pits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "NyaruTaffy" ,
"Name" : "NyaruTaffy" ,
"Type" : "RVC" ,
"Rate" : 40000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"SoVits2" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"HiddenSize" : 256 ,
"Cluster" : "Index"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 32000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 48000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"SoVits4.0V2" : false ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件)
//SoVits4.0V2: 是否为SoVits4.0V2模型 {
"Folder" : "DiffShiroha" ,
"Name" : "白羽" ,
"Type" : "DiffSvc" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"MelBins" : 128 ,
"Cleaner" : "" ,
"Hifigan" : "nsf_hifigan" ,
"Hubert" : "hubert" ,
"Characters" : [ ] ,
"Pndm" : 100 ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"V2" : true
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Pndm:加速倍数,如果是V1模型则必填且必须为导出时设置的加速倍率
//V2:是否为V2模型,V2模型就是后来我分4个模块导出的那个
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256) {
"Folder" : "utagoe" ,
"Name" : "utagoe" ,
"Type" : "DiffSinger" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hifigan" : "singer_nsf_hifigan" ,
"Characters" : [ ] ,
"MelBins" : 128
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的singer_nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到) {
"Folder" : "HimenoSena" ,
"Name" : "HimenoSena" ,
"Type" : "BertVits" ,
"Symbol" : [
"_" ,
"AA" ,
"E" ,
"EE" ,
"En" ,
"N" ,
"OO" ,
"V" ,
"a" ,
"a:" ,
"aa" ,
"ae" ,
"ah" ,
"ai" ,
"an" ,
"ang" ,
"ao" ,
"aw" ,
"ay" ,
"b" ,
"by" ,
"c" ,
"ch" ,
"d" ,
"dh" ,
"dy" ,
"e" ,
"e:" ,
"eh" ,
"ei" ,
"en" ,
"eng" ,
"er" ,
"ey" ,
"f" ,
"g" ,
"gy" ,
"h" ,
"hh" ,
"hy" ,
"i" ,
"i0" ,
"i:" ,
"ia" ,
"ian" ,
"iang" ,
"iao" ,
"ie" ,
"ih" ,
"in" ,
"ing" ,
"iong" ,
"ir" ,
"iu" ,
"iy" ,
"j" ,
"jh" ,
"k" ,
"ky" ,
"l" ,
"m" ,
"my" ,
"n" ,
"ng" ,
"ny" ,
"o" ,
"o:" ,
"ong" ,
"ou" ,
"ow" ,
"oy" ,
"p" ,
"py" ,
"q" ,
"r" ,
"ry" ,
"s" ,
"sh" ,
"t" ,
"th" ,
"ts" ,
"ty" ,
"u" ,
"u:" ,
"ua" ,
"uai" ,
"uan" ,
"uang" ,
"uh" ,
"ui" ,
"un" ,
"uo" ,
"uw" ,
"v" ,
"van" ,
"ve" ,
"vn" ,
"w" ,
"x" ,
"y" ,
"z" ,
"zh" ,
"zy" ,
"!" ,
"?" ,
"u2026" ,
"," ,
"." ,
"'" ,
"-" ,
"SP" ,
"UNK"
] ,
"Cleaner" : "" ,
"Rate" : 44100 ,
"CharaMix" : true ,
"Characters" : [
"u56fdu89c1u83dcu5b50" ,
"u59ecu91ceu661fu594f" ,
"u65b0u5802u5f69u97f3" ,
"u56dbu6761u51dbu9999" ,
"u5c0fu97a0u7531u4f9d"
] ,
"LanguageMap" : {
"ZH" : [
0 ,
0
] ,
"JP" : [
1 ,
6
] ,
"EN" : [
2 ,
8
]
} ,
"Dict" : "BasicDict" ,
"BertPath" : [
"chinese-roberta-wwm-ext-large" ,
"deberta-v2-large-japanese" ,
"bert-base-japanese-v3"
]
} // ${xxx}是什么意思大家应该都知道吧,总之以下是多个不同项目需要的模型文件(需要放置在对应的模型文件夹下)。
// Tacotron2:
${Folder} _decoder_iter.onnx
${Folder} _encoder.onnx
${Folder} _postnet.onnx
// Vits: 单角色VITS
${Folder} _dec.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// Vits: 多角色VITS
${Folder} _dec.onnx
${Folder} _emb.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// SoVits:
${Folder} _SoVits.onnx
// RVC:
${Folder} _RVC.onnx
// DiffSvc:
${Folder} _diffSvc.onnx
// DiffSvc: V2
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
${Folder} _after.onnx
// DiffSinger: OpenVpiVersion
${Folder} _diffSinger.onnx
// DiffSinger:
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
${Folder} _after.onnx例如:_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
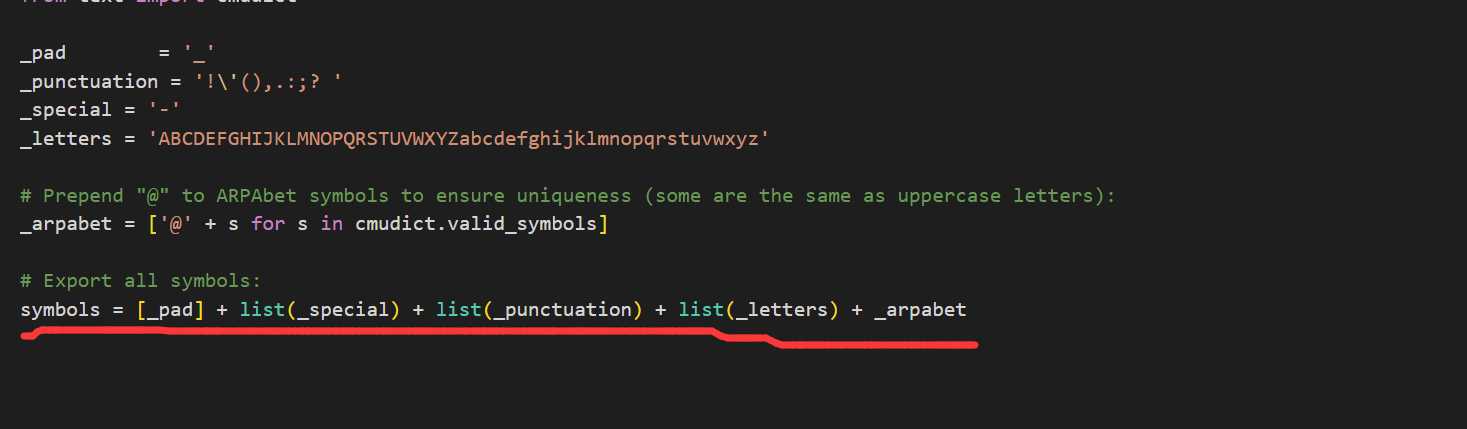
打开你训练模型的项目,打开textsymbol.py,如图按照划线的List顺序将上面的4个字符串连接即可
/*
Cleaner请放置于根目录的Cleaners文件夹内,应该是一个按照要求定义的动态库(.dll),dll应当命名为Cleaner名,Cleaner名即为模型定义Json文件中Cleaner一栏填写的内容。
所有的插件dll需要定义以下函数,函数名必须为PluginMain,Dll名必须为插件名(或Cleaner名):
*/
const wchar_t * PluginMain ( const wchar_t *);
// 该接口只要求输入输出一致,并不要求功能一致,也就是说,你可以在改Dll中实现任何想要的功能,比方说ChatGpt,机器翻译等等。
// 以ChatGpt为例,PluginMain函数传入了一个输入字符串input,将该输入传入ChatGpt,再将ChatGpt的输出传入PluginMain,最后返回输出。
wchar_t * PluginMain ( wchar_t * input){
wchar_t * tmpOutput = ChatGpt (input);
return Clean (tmpOutput);
}
// 注意:导出dll时请使用 extern "C" 关键字来防止C++语言的破坏性命名。 git clone https: // github.com/NaruseMioShirakana/MoeVoiceStudio.git
//自行配置OnnxRuntime和FFMPEG的Dll
//使用VisualStudio构建لا يجوز لأي منظمة أو فرد أن تنتهك حقوق صورة للآخرين عن طريق التذمر أو التشويه أو استخدام تكنولوجيا المعلومات لتشكيلها. لا يجوز إنتاج صورة حامل الحق في الصورة أو استخدامها أو الكشف عنها دون موافقة حامل الحق في الصورة ، باستثناء ما هو منصوص عليه في القانون. بدون موافقة الحامل الصحيح على حق ، لا يجوز للحامل الصحيح لعمل الصورة أن يستخدم أو يكشف عن صورة حامل الحق من خلال النشر أو النسخ أو المصدر أو الاستئجار أو المعرض ، إلخ.
[حق السمعة] يتمتع الموضوعات المدنية بحقوق السمعة. لا يجوز لأي منظمة أو فرد أن تنتهك حقوق سمعة الآخرين من خلال الإهانة أو التشهير أو أي وسائل أخرى.
[الأعمال التي تنتهك حقوق السمعة] إذا تم وصف الأعمال الأدبية والفنية التي نشرها مرتكب الجريمة من قبل أشخاص حقيقيين أو أشخاص معينين ، وتحتوي على محتوى مهين أو مباهز ، والذي ينتهك حقوق السمعة للآخرين ، فإن الضحية لها الحق في طلب الجاني لتحمل المسؤولية المدنية وفقًا للقانون. لا تصف الأعمال الأدبية والفنية التي نشرها مرتكب الجريمة أشخاصًا محددين بأنه موضوع الوصف ، وفقط إذا كانت المخططات مماثلة لظروف الشخص المحدد ، فإنهم لا يتحملون المسؤولية المدنية.
مواد الصورة المستخدمة من قبل Moess مشتقة من:
معايير الحكم على الدخل المنخفض هي: أي محتوى تم إنشاؤه باستخدام الكثير من الذكاء الاصطناعي ، والمحتوى الأصلي منخفض ، والمعنى غير معروف ، والمحتوى ذو جودة منخفضة ، إلخ. ↩
معايير الحكم الإلكتروني: 1. الأصالة. نسبة الأشياء الخاصة بك في جميع أنحاء المشروع (من أجل الذكاء الاصطناعي ، فإن إنشاء نماذج مدربة تمامًا من قبلك تنتمي إليك بشكل مستقل ؛ إن إنشاء نماذج أخرى تنتمي إلى الآخرين). تشمل الجوانب المغطاة على سبيل المثال لا الحصر البرامج والفن والصوت والتخطيط وما إلى ذلك ، على سبيل المثال ، تطبيق الوحدة وقوالب المحرك الأخرى لاستبدال الجلود هو النفايات الإلكترونية. ↩


