DragonianVoice
ve api

中国語|英語
このリポジトリは、UIプロジェクトの維持を永久に停止し、純粋なLIBプロジェクトになります。コードリポジトリアドレスは次のとおりですが、SVCとTTSに関するリリースはこのリポジトリでまだリリースされています。
このリポジトリは次のとおりです。1。TTS(tacotron2、vits、emotionalvits、bertvits2、gptsovits); 2。SVC(SovitsSVC、RVC、diffusionsvc、fishdiffusion、ReflowsVc); 3。SVS(diffsinger)ONNXフレームワークの推論リポジトリは、現在C/CPP/C#呼び出しをサポートしています。
このリポジトリの最新バージョンは魚のスピーチにリンクされており、GGMLフレームワークを使用して魚のスピーチを書き直して魚のスピーチを形成します。
注:SVS対応ブランチ:Moevoicestudio moevoicestudiocore
CUDAサポートについては、onnxruntime公式リポジトリにアクセスしてください。
実験の後、DMLはONNXのサポートされていない演算子が使用されたときにエラーを報告しないようにしますが、予期しない結果を返します。ただし、最新のSovitsリポジトリでのONNXエクスポートはこれらの演算子に取って代わりました。そのため、Sovits3.0およびSovits4.0の回復サポートDMLの使用が必要ですが、ONNXモデルはSovitsonnxエクスポートの最新(2023/7/17)バージョンを使用して再輸出する必要があります。
拡散モデルとリフローモデルの特性により、推測するステップの総数がモデルでトレーニングしたステップの最大数(実際のステップ数=ステップ数/加速度倍率の総数よりも大きい場合、この総ステップ数は推論中に取得した実際のステップ数ではなく、K_Step)は、出力オーディオを引き起こします。したがって、推論前にモデル構成ファイルのMAXSTEP(またはk_step_max)を注意深く観察することをお勧めします。
このプロジェクトはオープンソースおよびオフラインプロジェクトであり、このプロジェクトのすべての開発者とメンテナー(以下、貢献者と呼ばれる)はこのプロジェクトを制御できません。このプロジェクトの貢献者は、データセットの抽出、データセット処理、コンピューティングパワーサポート、トレーニングサポート、推論などを含むがこれらに限定されない、あらゆる形態の支援を組織や個人に提供したことはありません。このプロジェクトの貢献者は、プロジェクトを使用しているユーザーの目的を知りません。したがって、このプロジェクトに基づいて合成されたすべてのオーディオは、このプロジェクトの貢献者とは関係ありません。これによって引き起こされるすべての問題は、ユーザー自身の責任です。
このプロジェクト自体には、音声合成の機能はありませんが、ユーザー自身のトレーニングとONNXモデルの生産を開始するためにのみ使用されます。モデルトレーニングとONNXモデルの生産は、このプロジェクトの貢献者とは関係がなく、すべてユーザー自身の行動です。このプロジェクトの貢献者は、すべてのユーザーのモデルトレーニングと生産に参加していません。
このプロジェクトは完全にオフラインで実行され、ユーザー情報を収集できず、ユーザー入力データを取得できません。したがって、このプロジェクトの貢献者はすべてのユーザー入力とモデルを認識していないため、ユーザーの入力について責任を負いません。
また、このプロジェクトにはモデルは付属しておらず、セカンダリリリースに含まれるモデルとこのプロジェクトに使用されるモデルは、このプロジェクトの開発者とは何の関係もありません。
このプロジェクトは現在、コマンドラインの推論またはその他のソフトウェアを実装するための独自の方法を呼び出すことを完全にサポートしています。誰もがこのプロジェクトにPRを推奨することを歓迎します
著者の他のプロジェクト:aitoolkits
開発に参加したい場合は、QQグループに参加するか、PRを直接追加することができます
モデルはONNXモデルに変換する必要があります。詳細については、選択したプロジェクトのソースリポジトリを参照してください。 PTHモデルは直接使用できません! ! ! ! ! ! ! ! ! ! ! ! !
このプロジェクトの各ブランチ:
XP至上主義者はecとしています、誰がドラゴンの女の子が好きではありませんか?
このプロジェクトの当初の意図は、環境省を必要とせずにさまざまな音声合成プロジェクトの必要性を実現することであり、現在ではSVCの補助エディターとして作成される予定です。
このプロジェクトは結局「個人的な」および「プロフェッショナル」プロジェクトであるため、よりプロフェッショナルなソフトウェアを持っているか、Python CLI愛好家であるか、関連分野で大きなショットです。このソフトウェアは十分にプロフェッショナルではなく、あなたのニーズを満たしていないか、役に立たない可能性が高いことを知っています。
このプロジェクトは、かけがえのないプロジェクトではありません。それどころか、さまざまなツールを使用して、このプロジェクトの機能を置き換えることができます。このプロジェクトが関連分野の主要なプロジェクトになるとは思っていません。私は熱意を持ってプロジェクトを開発し続けています。しかし、熱意は常に1日消滅しますが、プロジェクトは私の熱意が完全に消えるまでメンテナンスを維持することを約束します(ユーザーの数が0であっても、誰かがそれを使用するかどうかに関係なく)
このプロジェクトの設計にはさまざまな問題がある可能性があるため、誰もが機能を改善するために積極的にチャーハンを注文する必要があります。機能と経験の最適化のほとんどを受け入れます。
このプロジェクトはオープンソースであり、永遠に無料です。このプロジェクトの有料版が他の場所にある場合は、すぐに報告して購入しないでください。このプロジェクトは永遠に無料です。木曜日に白い葉を満たしたい場合は、Aifa Dian https://afdian.net/a/narusemioshirakanaに行くことができます
それは提供されていません、モデルのトレーニングは比較的簡単であり、無駄にお金を使う必要はありません。オンラインチュートリアルを段階的にフォローしてください。
- 独創。プロジェクト全体のあなた自身のものの割合(AIの場合、あなたによって完全に訓練されたモデルを使用することは、あなたのものです。対象となる側面には、プログラム、アート、オーディオ、計画などが含まれますが、これらに限定されません。たとえば、統一やその他のエンジンテンプレートを適用してスキンを置き換えることは電子廃棄物です。
- 開発者の態度。著者の態度は、お金を稼ぎ、去るか、単に無駄になることです。たとえば、「国内」、「最初」、「最も強い」、「自家製」などの無数のタグをヒットしました。その結果、非常に悪いまたは平凡なものが生まれました。
- 許可されていないデータセットを使用してトレーニングされたAIモデルのすべての商業行動に反対します。
あなたがしていることは電子廃棄物ではなく、合法的で準拠しており、深刻な政治的間違いがないことを確認できれば、私の能力の中でいくつかの技術サポートを提供します。
中国の道はサポートされていませんか?実際、プロジェクトオントロジーは中国の道をサポートしていますが、2023年3月までにonnxruntimeのバージョンは中国のパスをサポートしていません。この問題は、私が解決できるものではなく、解決できるものではありません。 Microsoftのみがこのバグを修正できます。幸いなことに、最新のOnNXRuntimeはWシリーズ関数を使用して中国の経路問題を解決します。
CUDAの互換性が非常に低いため、プログラムのインストールとコンパイル時にCUDAベースのプログラムをインストールしてコンパイルする必要があります。または、CUDAの最新バージョンは変更されていません。この問題は、Nvidiaが互換性に注意を払うのを待つことができます。
moevoicestudiocoreは、libの形でc ++言語で呼び出しを提供します
必要に応じて、次の対応するクラスを参照してください
# include < Modules/Models/header/Tacotron.hpp >
# include < Modules/Models/header/Vits.hpp >
# include < Modules/Models/header/VitsSvc.hpp >
# include < Modules/Models/header/DiffSvc.hpp >
# include < Modules/Models/header/DiffSinger.hpp >
InferClass::Tacotron2;
InferClass::Vits;
InferClass::VitsSvc;
InferClass::DiffusionSvc;
InferClass::DiffusionSinger;
/*
构造函数第一个是配置文件json
第二个是进度条回调
第三个是参数回调 (若为TTS 此参数为空即可)
第四个参数为设备
使用调用Inference函数即可
*/モデル構成については、#model構成を参照してください
デモ:RVCコマンドラインの例
更新を停止します(ダウンロードとアップロード速度による):Vocoder&Hiddenunitbert
更新を停止します(Huggingfaceが壁に囲まれているため):Huggingface
最新の倉庫:Openi
プリセットを自分でエクスポートします。
input_namesは["source"] 、 output_namesは["embed"] 、 dynamic_axesは{"source":[0,2],}である必要があります。input_namesは["c","f0"] 、 output_names dynamic_axes ["audio"]である必要があります{"c":[0,1],"f0":[0,1],}input_namesは["x"] 、 output_namesは["audio"] 、 dynamic_axes {"x":[0,1],}である必要がありますVECモデルとHubertモデルはHubertフォルダーに配置され、HifiganモデルはHifiganフォルダーに配置されます。 2つのF0予測子、FCPEまたはRMVPEを使用する必要がある場合は、ルートディレクトリにF0predictorフォルダーを作成し、ONNXモデルをその中に配置する必要があります。
xxx.jsonは、モデルの構成ファイルです。テンプレートに従って自分で記述する必要があり、同時にモデルをONNX自分に変換する必要があります。 Folder :モデルのフォルダー名を保存しますName :UIのモデルの表示名Type :モデルカテゴリRate :サンプリングレート(トレーニングをしていたときとまったく同じでなければなりません。理由を理解していない場合は、コンピューターオーディオ関連の知識を学ぶことをお勧めします) {
"Folder" : "Atri" ,
"Name" : "亚托莉-Tacotron2" ,
"Type" : "Tacotron2" ,
"Rate" : 22050 ,
"Symbol" : "_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" ,
"Cleaner" : "" ,
"AddBlank" : false ,
"Hifigan" : "hifigan"
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Tacotron2中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的hifigan放置到hifigan文件夹
//AddBlank:是否在音素之间插0作为分隔 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Vits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Vits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "SummerPockets" ,
"Name" : "SummerPocketsReflectionBlue" ,
"Type" : "Pits" ,
"Rate" : 22050 ,
"Symbol" : "_,.!?-~…AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ " ,
"Cleaner" : "" ,
"AddBlank" : true ,
"Emotional" : true ,
"EmotionalPath" : "all_emotions" ,
"Characters" : [ "鳴瀬しろは" , "空門蒼" , "鷹原うみ" , "紬ヴェンダース" , "神山識" , "水織静久" , "野村美希" , "久島鴎" , "岬鏡子" ]
}
//Symbol:模型的Symbol,不知道Symbol是啥的建议多看几个视频了解了解TTS的基础知识,这一项在Vits中必须填。
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//AddBlank:是否在音素之间插0作为分隔(大多数Pits模型必须为true)
//Emotional:是否加入情感向量
//EmotionalPath:情感向量npy文件名 {
"Folder" : "NyaruTaffy" ,
"Name" : "NyaruTaffy" ,
"Type" : "RVC" ,
"Rate" : 40000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"SoVits2" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"HiddenSize" : 256 ,
"Cluster" : "Index"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 32000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 48000 ,
"Hop" : 320 ,
"Cleaner" : "" ,
"Hubert" : "hubert" ,
"SoVits3" : true ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件) {
"Folder" : "NyaruTaffySo" ,
"Name" : "NyaruTaffy-SoVits" ,
"Type" : "SoVits" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hubert" : "hubert4.0" ,
"SoVits4.0V2" : false ,
"ShallowDiffusion" : "NyaruTaffy"
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"Cluster" : "KMeans"
"Characters" : [ "Taffy" , "Nyaru" ]
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Diffusion:是否为DDSP仓库下的扩散模型
//ShallowDiffusion:SoVits浅扩散模型,须填写ShallowDiffusion模型配置文件名(不带后缀和完整路径),小显存或内存下速度巨慢,效果未知,请根据实际情况决定是否使用)
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256)
//Cluster:聚类类型,包括"KMeans"和"Index",KMeans需要前往SoVits仓库将KMeans文件导出为可用格式,放置到模型文件夹;Index同理,需要前往SoVits仓库导出为可用格式(如果是RVC的单角色Index只需要改名为Index-0.index)然后放置到模型文件夹下(有几个角色就有几个Index文件)
//SoVits4.0V2: 是否为SoVits4.0V2模型 {
"Folder" : "DiffShiroha" ,
"Name" : "白羽" ,
"Type" : "DiffSvc" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"MelBins" : 128 ,
"Cleaner" : "" ,
"Hifigan" : "nsf_hifigan" ,
"Hubert" : "hubert" ,
"Characters" : [ ] ,
"Pndm" : 100 ,
"Diffusion" : false ,
"CharaMix" : true ,
"Volume" : false ,
"HiddenSize" : 256 ,
"V2" : true
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hubert:Hubert模型名,必须填且必须将在前置模型中下载到的Hubert放置到Hubert文件夹
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//Pndm:加速倍数,如果是V1模型则必填且必须为导出时设置的加速倍率
//V2:是否为V2模型,V2模型就是后来我分4个模块导出的那个
//Diffusion:是否为DDSP仓库下的扩散模型
//CharaMix:是否使用角色混合轨道
//Volume:该模型是否有音量Emb
//HiddenSize:Vec模型的尺寸(768/256) {
"Folder" : "utagoe" ,
"Name" : "utagoe" ,
"Type" : "DiffSinger" ,
"Rate" : 44100 ,
"Hop" : 512 ,
"Cleaner" : "" ,
"Hifigan" : "singer_nsf_hifigan" ,
"Characters" : [ ] ,
"MelBins" : 128
}
//Hop:模型的HopLength,不知道HopLength是啥的建议多看几个视频了解了解音频的基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到)
//Cleaner:插件名,可以不填,填了就必须要在Cleaner文件夹防止相应的CleanerDll,如果Dll不存在或者是Dll内部有问题,则会在加载模型时报插件错误
//Hifigan:Hifigan模型名,必须填且必须将在前置模型中下载到的singer_nsf_hifigan放置到hifigan文件夹
//Characters:如果是多角色模型必须填写为你的角色名称组成的列表,如果是单角色模型可以不填
//MelBins:模型的MelBins,不知道MelBins是啥的建议多看几个视频了解了解梅尔基础知识,这一项在SoVits中必须填。(数值必须为你训练时的数值,可以在你训练模型时候的配置文件里看到) {
"Folder" : "HimenoSena" ,
"Name" : "HimenoSena" ,
"Type" : "BertVits" ,
"Symbol" : [
"_" ,
"AA" ,
"E" ,
"EE" ,
"En" ,
"N" ,
"OO" ,
"V" ,
"a" ,
"a:" ,
"aa" ,
"ae" ,
"ah" ,
"ai" ,
"an" ,
"ang" ,
"ao" ,
"aw" ,
"ay" ,
"b" ,
"by" ,
"c" ,
"ch" ,
"d" ,
"dh" ,
"dy" ,
"e" ,
"e:" ,
"eh" ,
"ei" ,
"en" ,
"eng" ,
"er" ,
"ey" ,
"f" ,
"g" ,
"gy" ,
"h" ,
"hh" ,
"hy" ,
"i" ,
"i0" ,
"i:" ,
"ia" ,
"ian" ,
"iang" ,
"iao" ,
"ie" ,
"ih" ,
"in" ,
"ing" ,
"iong" ,
"ir" ,
"iu" ,
"iy" ,
"j" ,
"jh" ,
"k" ,
"ky" ,
"l" ,
"m" ,
"my" ,
"n" ,
"ng" ,
"ny" ,
"o" ,
"o:" ,
"ong" ,
"ou" ,
"ow" ,
"oy" ,
"p" ,
"py" ,
"q" ,
"r" ,
"ry" ,
"s" ,
"sh" ,
"t" ,
"th" ,
"ts" ,
"ty" ,
"u" ,
"u:" ,
"ua" ,
"uai" ,
"uan" ,
"uang" ,
"uh" ,
"ui" ,
"un" ,
"uo" ,
"uw" ,
"v" ,
"van" ,
"ve" ,
"vn" ,
"w" ,
"x" ,
"y" ,
"z" ,
"zh" ,
"zy" ,
"!" ,
"?" ,
"u2026" ,
"," ,
"." ,
"'" ,
"-" ,
"SP" ,
"UNK"
] ,
"Cleaner" : "" ,
"Rate" : 44100 ,
"CharaMix" : true ,
"Characters" : [
"u56fdu89c1u83dcu5b50" ,
"u59ecu91ceu661fu594f" ,
"u65b0u5802u5f69u97f3" ,
"u56dbu6761u51dbu9999" ,
"u5c0fu97a0u7531u4f9d"
] ,
"LanguageMap" : {
"ZH" : [
0 ,
0
] ,
"JP" : [
1 ,
6
] ,
"EN" : [
2 ,
8
]
} ,
"Dict" : "BasicDict" ,
"BertPath" : [
"chinese-roberta-wwm-ext-large" ,
"deberta-v2-large-japanese" ,
"bert-base-japanese-v3"
]
} // ${xxx}是什么意思大家应该都知道吧,总之以下是多个不同项目需要的模型文件(需要放置在对应的模型文件夹下)。
// Tacotron2:
${Folder} _decoder_iter.onnx
${Folder} _encoder.onnx
${Folder} _postnet.onnx
// Vits: 单角色VITS
${Folder} _dec.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// Vits: 多角色VITS
${Folder} _dec.onnx
${Folder} _emb.onnx
${Folder} _flow.onnx
${Folder} _enc_p.onnx
${Folder} _dp.onnx
// SoVits:
${Folder} _SoVits.onnx
// RVC:
${Folder} _RVC.onnx
// DiffSvc:
${Folder} _diffSvc.onnx
// DiffSvc: V2
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
${Folder} _after.onnx
// DiffSinger: OpenVpiVersion
${Folder} _diffSinger.onnx
// DiffSinger:
${Folder} _encoder.onnx
${Folder} _denoise.onnx
${Folder} _pred.onnx
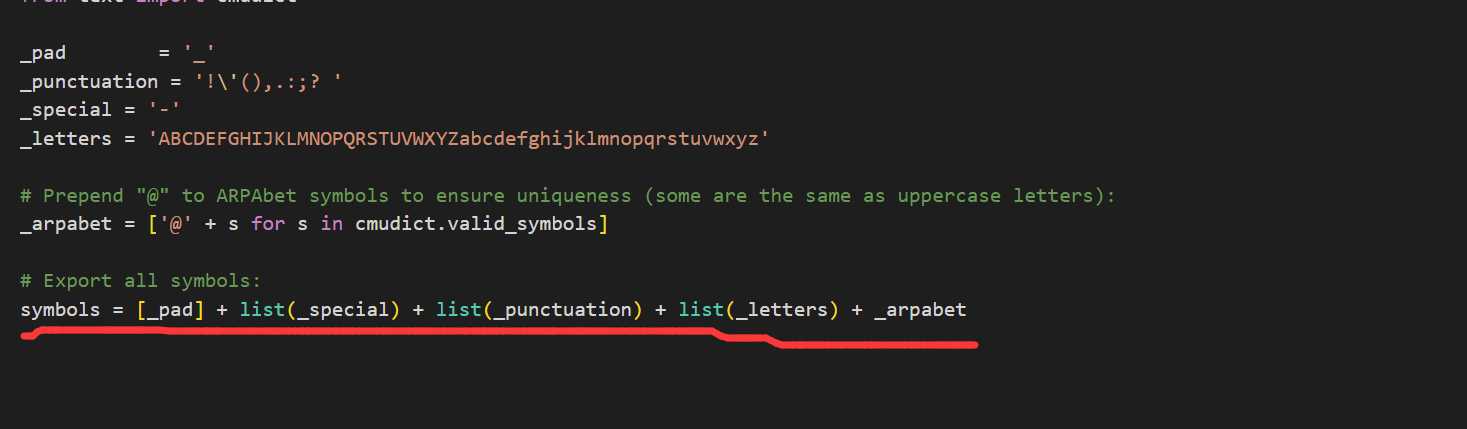
${Folder} _after.onnx例如:_-!'(),.:;? ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
打开你训练模型的项目,打开textsymbol.py,如图按照划线的List顺序将上面的4个字符串连接即可
/*
Cleaner请放置于根目录的Cleaners文件夹内,应该是一个按照要求定义的动态库(.dll),dll应当命名为Cleaner名,Cleaner名即为模型定义Json文件中Cleaner一栏填写的内容。
所有的插件dll需要定义以下函数,函数名必须为PluginMain,Dll名必须为插件名(或Cleaner名):
*/
const wchar_t * PluginMain ( const wchar_t *);
// 该接口只要求输入输出一致,并不要求功能一致,也就是说,你可以在改Dll中实现任何想要的功能,比方说ChatGpt,机器翻译等等。
// 以ChatGpt为例,PluginMain函数传入了一个输入字符串input,将该输入传入ChatGpt,再将ChatGpt的输出传入PluginMain,最后返回输出。
wchar_t * PluginMain ( wchar_t * input){
wchar_t * tmpOutput = ChatGpt (input);
return Clean (tmpOutput);
}
// 注意:导出dll时请使用 extern "C" 关键字来防止C++语言的破坏性命名。 git clone https: // github.com/NaruseMioShirakana/MoeVoiceStudio.git
//自行配置OnnxRuntime和FFMPEG的Dll
//使用VisualStudio构建組織や個人は、情報技術を中傷、名誉am損、または使用してそれらを偽造することにより、他者の肖像画を侵害することはできません。ポートレートの右所有者の肖像画は、法律で別途提供されている場合を除き、ポートレートの右所有者の同意なしに作成、使用、または開示されてはなりません。ポートレートの右所有者の同意がなければ、ポートレートワークの右の所有者は、公開、コピー、発行、レンタル、展示会など、ポートレートの右保有者のポートレートを使用または開示してはなりません。
[評判権]民事科目は評判の権利を享受します。組織や個人は、s辱、中傷、またはその他の手段によって他者の評判の権利を侵害することはできません。
[評判の権利を侵害します]加害者によって発表された文学的および芸術作品が、実際の人々または特定の人々によって説明され、他者の評判の権利を侵害するin辱またはland辱的な内容を含む場合、被害者は法律に従って民事責任を負うように加害者に要求する権利を持っています。加害者によって発表された文学的および芸術作品は、特定の人を説明の対象として説明しておらず、プロットが特定の人の状況に似ている場合にのみ、民事責任を負わないものとします。
MOESSが使用する画像資料は、次のものから派生しています。
低所得の審査の基準は次のとおりです。多くのAIを使用して生成されるコンテンツは、元のコンテンツが低く、意味は不明であり、コンテンツは低品質です。
E-SPAM判断基準:1。独創性。プロジェクト全体のあなた自身のものの割合(AIの場合、あなたによって完全に訓練されたモデルを使用することは、あなたのものです。対象となる側面には、プログラム、アート、オーディオ、計画などが含まれますが、これらに限定されません。たとえば、統一やその他のエンジンテンプレートを適用してスキンを置き換えることは電子廃棄物です。 ↩


