ttsaudionormalizer
中文文档
TTSAUDIONORMALIZER เป็นเครื่องมือประมวลผลเสียง TTS มืออาชีพที่ให้การวิเคราะห์เสียงที่ครอบคลุมและความสามารถในการประมวลผลมาตรฐาน เครื่องมือนี้มีวัตถุประสงค์เพื่อปรับปรุงคุณภาพการฝึกอบรมของข้อมูล TTS และให้ความมั่นใจในคุณสมบัติเสียง
ความจำเป็นของมาตรฐานเสียง TTS
I. ปรับปรุงผลการฝึกอบรมแบบจำลอง
1. เพิ่มประสิทธิภาพกระบวนการเรียนรู้
- ระดับระดับเสียงแบบครบวงจรช่วยให้แบบจำลองมุ่งเน้นไปที่การเรียนรู้คุณสมบัติการพูดมากกว่าที่จะถูกรบกวนจากความแตกต่างของปริมาณ
- ข้อมูลที่ได้มาตรฐานช่วยให้โมเดลเข้าหากันเร็วขึ้นลดเวลาการฝึกอบรม
- ลดความเสี่ยงของแบบจำลองการเรียนรู้คุณสมบัติที่ไม่ถูกต้อง
2. ป้องกันความผิดปกติของการฝึกอบรม
- หลีกเลี่ยงการระเบิดการไล่ระดับสีหรือหายไปเนื่องจากความแตกต่างในปริมาณมาก
- ลดความเป็นไปได้ของแบบจำลองที่เกินความเป็นคุณลักษณะระดับเสียง
- ปรับปรุงความมั่นคงของกระบวนการฝึกอบรม
3. เพิ่มความสามารถในการวางนัยทั่วไป
- แบบจำลองช่วยเหลือมุ่งเน้นไปที่การเรียนรู้คุณสมบัติการพูดที่จำเป็น
- ปรับปรุงการปรับตัวแบบจำลองในสถานการณ์ต่าง ๆ
- ลดการพึ่งพาคุณสมบัติที่ไม่สำคัญ
ii. รับรองคุณภาพเสียง
1. ความชัดเจนในการพูด
- เพิ่มประสิทธิภาพการตอบสนองความถี่เน้นแถบความถี่การพูดที่สำคัญ
- เพิ่มความชัดเจนของพยัญชนะปรับปรุงความเข้าใจในการพูด
- รักษาความเป็นธรรมชาติของเสียงสระรักษาลักษณะเสียง
2. การควบคุมเสียงรบกวน
- ลบเสียงรบกวนพื้นหลังปรับปรุงความบริสุทธิ์ของการพูด
- บีบอัดช่วงไดนามิกระดับระดับความสมดุล
- กรองแถบความถี่ที่ไร้ประโยชน์ลดปัจจัยการรบกวน
iii. ตรวจสอบความสอดคล้องของข้อมูล
1. ข้อกำหนดทางเทคนิคสม่ำเสมอสม่ำเสมอ
- รวมอัตราการสุ่มตัวอย่างให้แน่ใจว่าคุณภาพข้อมูล
- ทำให้การตั้งค่าช่องมาตรฐานลดความซับซ้อนของการประมวลผลโฟลว์
- ทำให้รูปแบบเสียงเป็นมาตรฐานปรับปรุงความเข้ากันได้
2. การเพิ่มประสิทธิภาพการสกัดคุณลักษณะ
- ปรับปรุงความแม่นยำและความน่าเชื่อถือในการแยกคุณลักษณะ
- เพิ่มความสามารถในการเปรียบเทียบระหว่างตัวอย่างที่แตกต่างกัน
- ตรวจสอบให้แน่ใจว่าคุณภาพของข้อมูลการฝึกอบรมสอดคล้องกัน
กระบวนการมาตรฐานที่แนะนำ:
1. การประมวลผลล่วงหน้าขั้นพื้นฐาน
- การรวมรูปแบบ
- แปลงรูปแบบเสียงที่แตกต่างกัน (เช่นเป็น WAV)
- ตรวจสอบให้แน่ใจว่ามีรูปแบบเข้ากันได้
- การรวมอัตราตัวอย่าง
- อัตราการสุ่มตัวอย่างมาตรฐาน (เช่น 22050Hz)
- รักษาความสอดคล้องของข้อมูล
- การแปลงช่องโมโน
- แปลงเสียงหลายช่องทางเป็นโมโน
- ลดความซับซ้อนของการประมวลผลที่ตามมา
2. การเพิ่มประสิทธิภาพคุณภาพเสียง?
- การกำจัดออฟเซ็ต DC
- กำจัดออฟเซ็ตคงที่ในสัญญาณเสียง
- ปรับปรุงคุณภาพเสียง
- การปรับระดับเสียง
- รวมระดับเสียงเสียง
- ตรวจสอบให้แน่ใจว่ามีความสม่ำเสมอ
- การเพิ่มประสิทธิภาพการตอบสนองความถี่
- ปรับลักษณะความถี่
- เพิ่มประสิทธิภาพประสิทธิภาพเสียง
3. การประมวลผลเสียง?
- การกำจัดความเงียบ
- ทำความสะอาดส่วนเสียงที่ไม่ถูกต้อง
- เพิ่มคุณภาพข้อมูล
- การลดเสียงรบกวน
- กำจัดเสียงรบกวนพื้นหลัง
- ปรับปรุงความชัดเจนของเสียง
- การบีบอัดช่วงไดนามิก
- สมดุลช่วงเสียงแบบไดนามิก
- เพิ่มประสิทธิภาพโดยรวม
4. ตรวจสอบคุณภาพ✅
- การตรวจสอบคุณภาพ
- ตรวจสอบคุณภาพเสียงที่ประมวลผล
- ตรวจสอบให้แน่ใจว่าเป็นไปตามข้อกำหนดการฝึกอบรม
- การตรวจสอบคุณสมบัติ
- ตรวจสอบพารามิเตอร์คุณสมบัติเสียง
- รับประกันการแยกคุณสมบัติที่มีประสิทธิภาพ
แผนภาพการไหลของการประมวลผล:
Input Audio ➡ Basic Preprocessing ➡ Quality Optimization ➡ Noise Processing ➡ Quality Check ➡ Output Audio
หมายเหตุสำคัญ:
- รักษาบันทึกการประมวลผลสำหรับแต่ละขั้นตอน
- ทำการตรวจสอบคุณภาพที่ประเด็นสำคัญ
- เก็บข้อมูลการสำรองเสียงดั้งเดิม
- ปรับพารามิเตอร์ตามสถานการณ์แอปพลิเคชันเฉพาะ
ฟังก์ชั่นหลัก
1. การวิเคราะห์เสียง
- สร้างรายงานสถิติความดังโดยละเอียด
- ให้การสร้างภาพการกระจายระดับเสียง
- คำแนะนำการเพิ่มประสิทธิภาพพารามิเตอร์เอาท์พุท
from audio_analyzer import AudioAnalyzer
analyzer = AudioAnalyzer ()
results = analyzer . analyze_speaker_directory (
base_dir = "raw_voices" , # Nested folders, i.e., a main folder containing several subfolders (with audio files)
output_dir = "analysis_report" ,
max_workers = 16
)ผลลัพธ์:
发现 49 个说话人目录
处理说话人: 0%| | 0/49 [00:00<?, ?it/s]
分析说话人: 廉颇
分析音频: 0%| | 0/118 [00:00<?, ?it/s]
分析音频: 25%|██▌ | 30/118 [00:00<00:00, 289.97it/s]
分析音频: 53%|█████▎ | 62/118 [00:00<00:00, 299.46it/s]
分析音频: 78%|███████▊ | 92/118 [00:00<00:00, 298.95it/s]
音频分析报告 说话人: 廉颇:
--------------------------------------------------
分析的音频文件总数: 118
音量统计:
Mean Norm:
mean: 0.053
std: 0.010
min: 0.032
max: 0.082
RMS Amplitude:
mean: 0.089
std: 0.015
min: 0.057
max: 0.131
Max Amplitude:
mean: 0.546
std: 0.123
min: 0.293
max: 0.882
处理说话人: 2%|▏ | 1/49 [00:01<01:03, 1.31s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.053
2. 平衡设置 (确保清晰度): target_db = 0.063
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/廉颇
分析说话人: 小乔
分析音频: 0%| | 0/201 [00:00<?, ?it/s]
分析音频: 14%|█▍ | 28/201 [00:00<00:00, 268.48it/s]
分析音频: 29%|██▉ | 58/201 [00:00<00:00, 283.83it/s]
分析音频: 43%|████▎ | 87/201 [00:00<00:00, 281.59it/s]
分析音频: 60%|█████▉ | 120/201 [00:00<00:00, 297.76it/s]
分析音频: 75%|███████▍ | 150/201 [00:00<00:00, 294.95it/s]
分析音频: 90%|████████▉ | 180/201 [00:00<00:00, 289.50it/s]
音频分析报告 说话人: 小乔:
--------------------------------------------------
分析的音频文件总数: 201
音量统计:
Mean Norm:
mean: 0.052
std: 0.019
min: 0.012
max: 0.135
RMS Amplitude:
mean: 0.086
std: 0.030
min: 0.024
max: 0.209
Max Amplitude:
mean: 0.495
std: 0.143
min: 0.163
max: 0.943
处理说话人: 4%|▍ | 2/49 [00:02<01:09, 1.49s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.052
2. 平衡设置 (确保清晰度): target_db = 0.071
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/小乔
分析说话人: 赵云
分析音频: 0%| | 0/142 [00:00<?, ?it/s]
分析音频: 20%|█▉ | 28/142 [00:00<00:00, 270.67it/s]
分析音频: 42%|████▏ | 60/142 [00:00<00:00, 294.19it/s]
分析音频: 63%|██████▎ | 90/142 [00:00<00:00, 291.33it/s]
分析音频: 85%|████████▍ | 120/142 [00:00<00:00, 283.42it/s]
音频分析报告 说话人: 赵云:
--------------------------------------------------
分析的音频文件总数: 142
音量统计:
Mean Norm:
mean: 0.050
std: 0.019
min: 0.018
max: 0.124
RMS Amplitude:
mean: 0.089
std: 0.031
min: 0.039
max: 0.193
Max Amplitude:
mean: 0.603
std: 0.182
min: 0.339
max: 1.000
处理说话人: 6%|▌ | 3/49 [00:04<01:06, 1.45s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.050
2. 平衡设置 (确保清晰度): target_db = 0.070
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/赵云
...
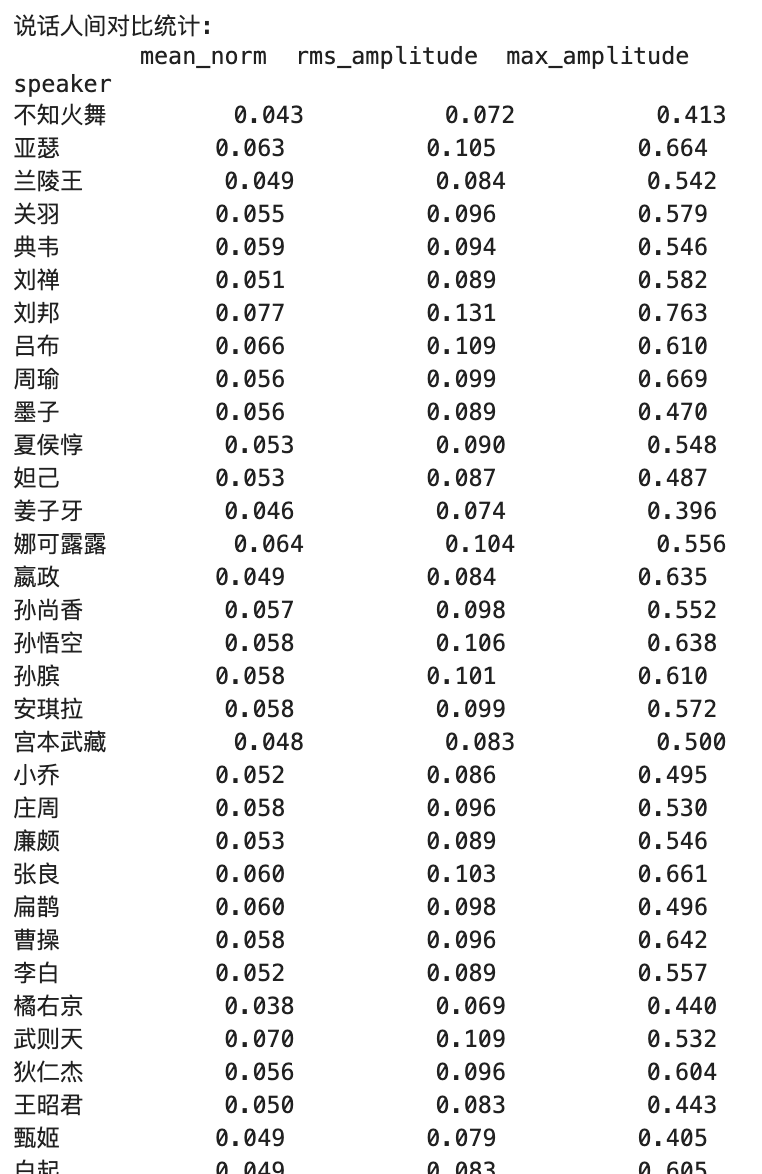
คำอธิบายตัวชี้วัดที่สำคัญ :
1. ค่าเฉลี่ยบรรทัดฐาน
- ความสำคัญในทางปฏิบัติ :
- สะท้อนระดับเสียงโดยรวมของเสียง
- แสดงถึงแอมพลิจูดแบบสัมบูรณ์โดยเฉลี่ยของสัญญาณเสียง
- ช่วงค่าโดยทั่วไประหว่าง 0-1
- ความหมายคุณค่า :
- ค่าที่สูงขึ้น = การรับรู้โดยรวมดังขึ้น
- ค่าต่ำกว่า = การรับรู้โดยรวมที่นุ่มนวลกว่า
- ช่วงอุดมคติโดยทั่วไประหว่าง 0.1-0.3
- สถานการณ์แอปพลิเคชัน :
- ใช้ในการประเมินว่าความดังโดยรวมมีความเหมาะสมหรือไม่
- ช่วยตรวจสอบว่าจำเป็นต้องได้รับปริมาณหรือไม่
2. แอมพลิจูด RMS
- ความสำคัญในทางปฏิบัติ :
- สะท้อนระดับพลังงานที่มีประสิทธิภาพของเสียง
- ใกล้เคียงกับการรับรู้ของหูของความดังมากขึ้น
- พิจารณาการกระจายพลังงานเมื่อเวลาผ่านไป
- ความหมายคุณค่า :
- ค่าที่สูงขึ้น = พลังงานเสียงที่แข็งแกร่งขึ้น
- ค่าที่ต่ำกว่า = พลังงานเสียงที่อ่อนลง
- โดยทั่วไปแล้วเสียงระดับมืออาชีพแนะนำระหว่าง 0.1-0.4
- สถานการณ์แอปพลิเคชัน :
- ประเมินช่วงเสียงแบบไดนามิก
- ตรวจสอบว่าการบีบอัดหรือการขยายเสียงต้องการความต้องการเสียง
- ใช้กันทั่วไปในการทำให้เป็นมาตรฐานเสียง
3. แอมพลิจูดสูงสุด
- ความสำคัญในทางปฏิบัติ :
- สะท้อนถึงระดับสูงสุดในเสียง
- แสดงถึงค่าสูงสุดของสัญญาณทันที
- ใช้เพื่อตรวจสอบว่ามีการตัดหรือไม่
- ความหมายคุณค่า :
- 1.0 = ค่าสูงสุดที่เป็นไปได้สำหรับเสียงดิจิตอล (การตัดที่มีศักยภาพ)
- การควบคุมสูงสุดที่แนะนำต่ำกว่า 0.9
- ต่ำเกินไป (เช่น <0.5) ระบุว่าเสียงอาจอ่อนเกินไป
- สถานการณ์แอปพลิเคชัน :
- ตรวจจับการบิดเบือนเสียง
- ประเมินส่วนหัวเสียง
- คำแนะนำการตั้งค่าตัว จำกัด
ความสัมพันธ์ระหว่างสาม
ความสัมพันธ์แบบลำดับชั้น :
- แอมพลิจูดสูงสุด> แอมพลิจูด rms> ค่าเฉลี่ยบรรทัดฐาน
- นี่เป็นเพราะวิธีการคำนวณที่แตกต่างกัน
การใช้งานจริง :
- ค่าเฉลี่ยบรรทัดฐาน: ใช้สำหรับการประเมินปริมาณโดยรวม
- RMS: ใช้สำหรับการควบคุมระดับพลังงาน
- แอมพลิจูดสูงสุด: ใช้สำหรับการควบคุมสูงสุด
ค่าอุดมคติอ้างอิง
- ค่าอ้างอิงการผลิตเสียงระดับมืออาชีพ :
- ค่าเฉลี่ยบรรทัดฐาน: 0.1-0.3
- RMS: 0.1-0.4
- แอมพลิจูดสูงสุด: 0.8-0.9
คำแนะนำการใช้งาน
- ก่อนอื่นตรวจสอบแอมพลิจูดสูงสุดเพื่อหลีกเลี่ยงการตัด
- ใช้ RMS เพื่อให้แน่ใจว่าพลังงานโดยรวมมีความเหมาะสม
- ค่าเฉลี่ยอ้างอิงบรรทัดฐานเพื่อปรับระดับเสียงโดยรวม
- พิจารณาตัวบ่งชี้ทั้งสามในบริบทของแอปพลิเคชันเฉพาะ
ตัวชี้วัดเหล่านี้ทำงานร่วมกันเพื่อช่วยเรา:
- รับรองคุณภาพเสียง
- รักษาปริมาณความสอดคล้อง
- หลีกเลี่ยงการบิดเบือนและเสียงรบกวน
- เพิ่มประสิทธิภาพประสบการณ์การฟัง
2. การทำให้เป็นมาตรฐานเสียง
คุณสมบัติที่สำคัญของโซลูชันนี้:
- ใช้เอฟเฟกต์บรรทัดฐานของ Sox สำหรับการทำให้เป็นมาตรฐานเสียง
- สามารถประมวลผลไฟล์เดียวหรือกระบวนการแบทช์ทั้งหมดไดเรกทอรี
- ค่าเริ่มต้นเป็นระดับเสียงปกติถึง -3dB ปรับได้ตามต้องการ
- รักษาคุณภาพเสียงดั้งเดิมปรับระดับเสียงเท่านั้น
การใช้งานง่าย:
- สำหรับไฟล์เดียว: เรียกฟังก์ชั่น normalize_audio () โดยตรงโดยตรง
- สำหรับไดเรกทอรีทั้งหมด: ใช้ BATCH_NORMALIZE_DIRECTORY () ฟังก์ชั่นไฟล์เสียงที่ผ่านการประมวลผลควรมีระดับระดับเสียงที่สม่ำเสมอมากขึ้นการแก้ปัญหาความดังที่ไม่สอดคล้องกัน หากปริมาณโดยรวมยังคงต่ำหรือสูงเกินไปให้ปรับพารามิเตอร์ target_db
from tts_audio_normalizer import AudioProcessingParams , TTSAudioNormalizer
# Create parameter object and customize parameters
params = AudioProcessingParams ()
params . noise_reduction_strength = 0.8 # Increase noise reduction intensity
params . target_db = - 3 # Set target volume
# Process single file
#normalizer.normalize_audio("input.wav", "output.wav", params)
# Batch process directory
normalizer . batch_normalize_directory (
input_dir = "./audio_segments" ,
output_dir = "./audio_segments_normalized" ,
params = params ,
max_workers = 4
)คู่มือการกำหนดค่าพารามิเตอร์
1. พารามิเตอร์พื้นฐาน
# Basic format settings
rate : int = 44100 # Sample rate
channels : int = 1 # Number of channels
output_format : str = 'wav' # Output format
target_db : float = - 3.0 # Target volume
2. พารามิเตอร์การเพิ่มประสิทธิภาพคุณภาพเสียง
# Equalizer settings
equalizer_enabled : bool = True # Enable equalizer
treble_frequency : float = 3000.0 # Treble center (2-8kHz)
mid_frequency : float = 1000.0 # Mid center (250Hz-2kHz)
bass_frequency : float = 100.0 # Bass center (80-250Hz)
3. พารามิเตอร์การลดเสียงรบกวน
# Noise processing
subsonic_filter_enabled : bool = True # Subsonic filtering
compression_ratio : float = 2.5 # Compression ratio
threshold_db : float = - 15.0 # Noise threshold
คำแนะนำการเพิ่มประสิทธิภาพฉาก
1. การปรับประเภทเสียง
| ประเภทเสียง | พารามิเตอร์ที่แนะนำ |
|---|
| ชาย | bass_gain = 2.0, mid_frequency = 1200Hz |
| หญิง | treble_gain = 1.5, bass_gain = 1.5 |
| เด็ก | mid_gain = 1.5, bass_gain = 1.0 |
2. การกำหนดค่าตัว จำกัด
| ระดับการบีบอัด | การรวมพารามิเตอร์ |
|---|
| การบีบอัดเล็กน้อย | threshold_db = -20, อัตราส่วน = 2, การโจมตี = 0.3s |
| การบีบอัดกลาง | threshold_db = -25, อัตราส่วน = 3, การโจมตี = 0.2S |
| การบีบอัดหนัก | threshold_db = -30, อัตราส่วน = 4, การโจมตี = 0.1s |
3. การกำหนดค่าอีควอไลเซอร์
| เป้าหมายคุณภาพเสียง | การรวมพารามิเตอร์ |
|---|
| การเพิ่มประสิทธิภาพเสียง | เสียงแหลม = 2.0, เบส = 1.0 |
| เพิ่มความชัดเจน | Treble = 3.0, bass = -1.0 |
| น้ำเสียงอบอุ่น | treble = -1.0, เบส = 2.0 |
ข้อควรระวังในการใช้งาน
- การป้องกันคุณสมบัติเสียง
- หลีกเลี่ยงการประมวลผลมากเกินไปที่นำไปสู่การบิดเบือน
- รักษาความชัดเจนของขอบเขตฟอนิม
- รักษาฉันทลักษณ์การพูดตามธรรมชาติ
- การปรับชุดข้อมูล
- ปรับพารามิเตอร์ตามลักษณะของลำโพง
- พิจารณาการบันทึกปัจจัยสภาพแวดล้อม
- รักษาความสอดคล้องของการประมวลผล
- การควบคุมคุณภาพ
- ตรวจสอบเอฟเฟกต์การประมวลผลเป็นประจำ
- ตรวจสอบตัวอย่างที่ผิดปกติ
- ปรับพารามิเตอร์ในเวลาที่เหมาะสม
เวิร์กโฟลว์แนวปฏิบัติที่ดีที่สุด
- ทำการวิเคราะห์เสียงก่อน
- เลือกพารามิเตอร์ตามรายงานการวิเคราะห์
- ผลการทดสอบผลกระทบในชุดขนาดเล็ก
- ปรับและปรับการกำหนดค่าพารามิเตอร์
- ดำเนินการประมวลผลการทำให้เป็นมาตรฐานแบทช์
- ตรวจสอบคุณภาพผลลัพธ์การประมวลผล
ด้วยการกำหนดค่าที่เหมาะสมและการใช้เครื่องมือนี้คุณสามารถปรับปรุงคุณภาพการฝึกอบรมของ TTS ได้อย่างมีนัยสำคัญให้การสนับสนุนข้อมูลพื้นฐานที่ดีขึ้นสำหรับการฝึกอบรมแบบจำลอง
ข้อมูลติดต่อ
Wechat


