Ttsaudionormalizador
中文文档
TTSaudionormalizer es una herramienta profesional de preprocesamiento de audio TTS que proporciona un análisis integral de audio y capacidades de procesamiento de estandarización. Esta herramienta tiene como objetivo mejorar la calidad de los datos de capacitación de TTS y garantizar la consistencia en las funciones de audio.
Necesidad de estandarización de audio TTS
I. Mejorar los efectos de entrenamiento de modelos
1. Optimizar el proceso de aprendizaje
- Los niveles de volumen unificados ayudan a los modelos a centrarse en aprender características del habla en lugar de distraerse con las diferencias de volumen
- Los datos estandarizados ayudan a los modelos a converger más rápido, reduciendo el tiempo de entrenamiento
- Reduce el riesgo de que los modelos aprendan características incorrectas
2. Prevenir anomalías de entrenamiento
- Evite la explosión de gradiente o la desaparición debido a las grandes diferencias de volumen
- Reducir la posibilidad de que el sobreajuste del modelo a las características de volumen
- Mejorar la estabilidad del proceso de entrenamiento
3. Mejorar la capacidad de generalización
- Los modelos de ayuda se centran en aprender características esenciales del habla
- Mejorar la adaptabilidad del modelo en diferentes escenarios
- Reducir la dependencia de las características no críticas
II. Garantizar la calidad de audio
1. Claridad del habla
- Optimizar la respuesta de frecuencia, enfatizar las bandas clave de frecuencia del habla
- Mejorar la claridad de la consonante, mejorar la inteligibilidad del habla
- Mantener la naturalidad de las vocales, preservar las características de voz
2. Control de ruido
- Eliminar el ruido de fondo, mejorar la pureza del habla
- Comprimir el rango dinámico, los niveles de volumen de equilibrio
- Filtrar bandas de frecuencia inútiles, reducir los factores de interferencia
Iii. Asegurar la consistencia de los datos
1. Uniformidad de especificaciones técnicas
- Unificar la tasa de muestreo, garantizar la calidad de los datos
- Estandarizar la configuración del canal, simplificar el flujo de procesamiento
- Estandarizar el formato de audio, mejorar la compatibilidad
2. Optimización de extracción de características
- Mejorar la precisión y confiabilidad de la extracción de características
- Mejorar la comparabilidad entre diferentes muestras
- Garantizar la consistencia de la calidad de los datos de capacitación
Proceso de estandarización recomendado:
1. Preprocesamiento básico
- Formato de unificación
- Convierta diferentes formatos de audio (por ejemplo, a WAV)
- Asegurar la compatibilidad del formato
- Unificación de la frecuencia de muestreo
- Estandarizar la velocidad de muestreo (por ejemplo, 22050Hz)
- Mantener la consistencia de los datos
- Conversión de canales mono
- Convertir audio multicanal a mono
- Simplifique el procesamiento posterior
2. Optimización de la calidad de audio?
- Extracción de compensación de DC
- Eliminar el desplazamiento fijo en las señales de audio
- Mejorar la calidad de audio
- Normalización del volumen
- Unificar los niveles de volumen de audio
- Asegurar la consistencia de volumen
- Optimización de la respuesta de frecuencia
- Ajustar las características de frecuencia
- Optimizar el rendimiento de audio
3. Procesamiento de ruido?
- Eliminación de silencio
- Limpiar segmentos de audio no válidos
- Mejorar la calidad de los datos
- Reducción de ruido
- Eliminar el ruido de fondo
- Mejorar la claridad de audio
- Compresión de rango dinámico
- Balancear el rango dinámico de audio
- Mejorar el rendimiento general
4. Check de calidad ✅
- Validación de calidad
- Verifique la calidad de audio procesada
- Asegúrese de que se cumplan los requisitos de capacitación
- Validación de características
- Verificar los parámetros de la función de audio
- Garantizar una extracción de características efectivas
Diagrama de flujo de procesamiento:
Input Audio ➡️ Basic Preprocessing ➡️ Quality Optimization ➡️ Noise Processing ➡️ Quality Check ➡️ Output Audio
Notas importantes:
- Mantener registros de procesamiento para cada paso
- Realizar controles de calidad en puntos clave
- Mantenga copias de seguridad de audio originales
- Ajustar los parámetros basados en escenarios de aplicación específicos
Funciones principales
1. Análisis de audio
- Generar un informe detallado de estadísticas de volumen
- Proporcionar visualización de distribución de volumen
- Sugerencias de optimización de parámetros de salida
from audio_analyzer import AudioAnalyzer
analyzer = AudioAnalyzer ()
results = analyzer . analyze_speaker_directory (
base_dir = "raw_voices" , # Nested folders, i.e., a main folder containing several subfolders (with audio files)
output_dir = "analysis_report" ,
max_workers = 16
)Resultados:
发现 49 个说话人目录
处理说话人: 0%| | 0/49 [00:00<?, ?it/s]
分析说话人: 廉颇
分析音频: 0%| | 0/118 [00:00<?, ?it/s]
分析音频: 25%|██▌ | 30/118 [00:00<00:00, 289.97it/s]
分析音频: 53%|█████▎ | 62/118 [00:00<00:00, 299.46it/s]
分析音频: 78%|███████▊ | 92/118 [00:00<00:00, 298.95it/s]
音频分析报告 说话人: 廉颇:
--------------------------------------------------
分析的音频文件总数: 118
音量统计:
Mean Norm:
mean: 0.053
std: 0.010
min: 0.032
max: 0.082
RMS Amplitude:
mean: 0.089
std: 0.015
min: 0.057
max: 0.131
Max Amplitude:
mean: 0.546
std: 0.123
min: 0.293
max: 0.882
处理说话人: 2%|▏ | 1/49 [00:01<01:03, 1.31s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.053
2. 平衡设置 (确保清晰度): target_db = 0.063
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/廉颇
分析说话人: 小乔
分析音频: 0%| | 0/201 [00:00<?, ?it/s]
分析音频: 14%|█▍ | 28/201 [00:00<00:00, 268.48it/s]
分析音频: 29%|██▉ | 58/201 [00:00<00:00, 283.83it/s]
分析音频: 43%|████▎ | 87/201 [00:00<00:00, 281.59it/s]
分析音频: 60%|█████▉ | 120/201 [00:00<00:00, 297.76it/s]
分析音频: 75%|███████▍ | 150/201 [00:00<00:00, 294.95it/s]
分析音频: 90%|████████▉ | 180/201 [00:00<00:00, 289.50it/s]
音频分析报告 说话人: 小乔:
--------------------------------------------------
分析的音频文件总数: 201
音量统计:
Mean Norm:
mean: 0.052
std: 0.019
min: 0.012
max: 0.135
RMS Amplitude:
mean: 0.086
std: 0.030
min: 0.024
max: 0.209
Max Amplitude:
mean: 0.495
std: 0.143
min: 0.163
max: 0.943
处理说话人: 4%|▍ | 2/49 [00:02<01:09, 1.49s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.052
2. 平衡设置 (确保清晰度): target_db = 0.071
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/小乔
分析说话人: 赵云
分析音频: 0%| | 0/142 [00:00<?, ?it/s]
分析音频: 20%|█▉ | 28/142 [00:00<00:00, 270.67it/s]
分析音频: 42%|████▏ | 60/142 [00:00<00:00, 294.19it/s]
分析音频: 63%|██████▎ | 90/142 [00:00<00:00, 291.33it/s]
分析音频: 85%|████████▍ | 120/142 [00:00<00:00, 283.42it/s]
音频分析报告 说话人: 赵云:
--------------------------------------------------
分析的音频文件总数: 142
音量统计:
Mean Norm:
mean: 0.050
std: 0.019
min: 0.018
max: 0.124
RMS Amplitude:
mean: 0.089
std: 0.031
min: 0.039
max: 0.193
Max Amplitude:
mean: 0.603
std: 0.182
min: 0.339
max: 1.000
处理说话人: 6%|▌ | 3/49 [00:04<01:06, 1.45s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.050
2. 平衡设置 (确保清晰度): target_db = 0.070
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/赵云
...
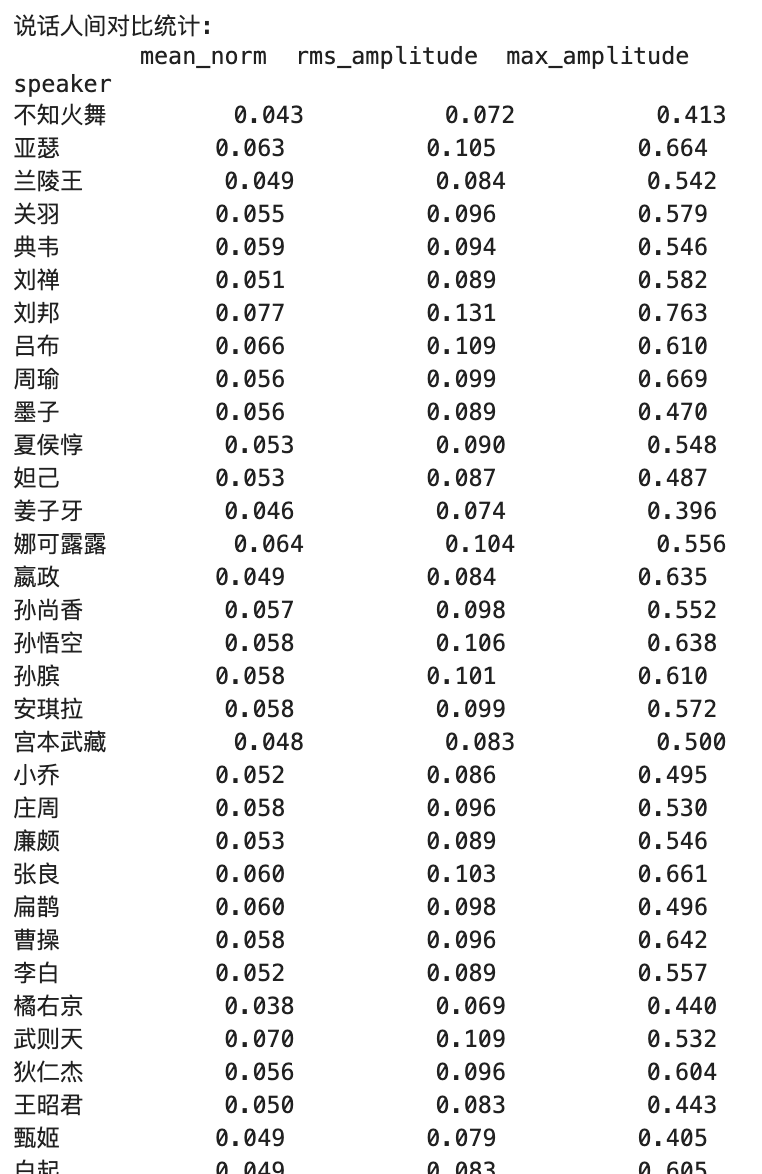
Explicación de métricas clave :
1. Norma media
- Significado práctico :
- Refleja el nivel general de audio de volumen
- Representa la amplitud absoluta promedio de la señal de audio
- Rango de valor típicamente entre 0-1
- Valor significado :
- Valor más alto = percepción general más fuerte
- Valor más bajo = percepción general más suave
- Rango ideal típicamente entre 0.1-0.3
- Escenarios de aplicación :
- Se utiliza para evaluar si el volumen general es apropiado
- Ayuda a determinar si se necesita ganancia de volumen
2. Amplitud rms
- Significado práctico :
- Refleja un nivel energético efectivo de audio
- Más cerca de la percepción del oído humano de volumen
- Considera la distribución de energía con el tiempo
- Valor significado :
- Valor más alto = energía de audio más fuerte
- Valor más bajo = energía de audio más débil
- Audio profesional generalmente recomendado entre 0.1-0.4
- Escenarios de aplicación :
- Evaluar el rango dinámico de audio
- Determinar si el audio necesita compresión o expansión
- Comúnmente utilizado en la normalización de audio
3. Amplitud máxima
- Significado práctico :
- Refleja los niveles máximos en audio
- Representa el valor instantáneo máximo de la señal
- Se utiliza para determinar si existe el recorte
- Valor significado :
- 1.0 = valor máximo posible para audio digital (recorte potencial)
- Control máximo recomendado por debajo de 0.9
- Demasiado bajo (por ejemplo, <0.5) indica que el audio podría ser demasiado suave
- Escenarios de aplicación :
- Detectar distorsión de audio
- Evaluar el espacio para la cabeza de audio
- Configuración del limitador de guía
Relación entre los tres
Relación jerárquica :
- Amplitud máxima> Amplitud de RMS> Norma media
- Esto se debe a sus diferentes métodos de cálculo
Aplicación práctica :
- Norma media: utilizado para la evaluación general del volumen
- RMS: utilizado para el control del nivel de energía
- Amplitud máxima: utilizado para el control máximo
Valores ideales de referencia
- Valores de referencia de producción de audio profesional :
- Norma media: 0.1-0.3
- RMS: 0.1-0.4
- Amplitud máxima: 0.8-0.9
Recomendaciones de uso
- Primero verifique la amplitud máxima para evitar el recorte
- Utilice RMS para garantizar que la energía general sea apropiada
- Norma media de referencia para ajustar el volumen general
- Considere los tres indicadores en el contexto de la aplicación específica
Estos indicadores trabajan juntos para ayudarnos:
- Garantizar la calidad de audio
- Mantener la consistencia del volumen
- Evite la distorsión y el ruido
- Optimizar la experiencia auditiva
2. Normalización de audio
Características clave de esta solución:
- Utiliza el efecto de norma de Sox para la normalización de audio
- Puede procesar archivos únicos o procesar directorios completos
- El valor predeterminado al volumen de normalización a -3dB, ajustable según sea necesario
- Mantiene la calidad de audio original, solo ajusta el volumen
El uso es simple:
- Para un solo archivo: llame directamente a la función normalize_audio ()
- Para el directorio completo: use la función Batch_Normaly_Directory () Los archivos de audio procesados deben tener niveles de volumen más uniformes, resolviendo el problema de la volumen inconsistente. Si el volumen general todavía se siente demasiado bajo o alto, ajuste el parámetro Target_DB.
from tts_audio_normalizer import AudioProcessingParams , TTSAudioNormalizer
# Create parameter object and customize parameters
params = AudioProcessingParams ()
params . noise_reduction_strength = 0.8 # Increase noise reduction intensity
params . target_db = - 3 # Set target volume
# Process single file
#normalizer.normalize_audio("input.wav", "output.wav", params)
# Batch process directory
normalizer . batch_normalize_directory (
input_dir = "./audio_segments" ,
output_dir = "./audio_segments_normalized" ,
params = params ,
max_workers = 4
)Guía de configuración de parámetros
1. Parámetros básicos
# Basic format settings
rate : int = 44100 # Sample rate
channels : int = 1 # Number of channels
output_format : str = 'wav' # Output format
target_db : float = - 3.0 # Target volume
2. Parámetros de optimización de calidad de sonido
# Equalizer settings
equalizer_enabled : bool = True # Enable equalizer
treble_frequency : float = 3000.0 # Treble center (2-8kHz)
mid_frequency : float = 1000.0 # Mid center (250Hz-2kHz)
bass_frequency : float = 100.0 # Bass center (80-250Hz)
3. Parámetros de reducción de ruido
# Noise processing
subsonic_filter_enabled : bool = True # Subsonic filtering
compression_ratio : float = 2.5 # Compression ratio
threshold_db : float = - 15.0 # Noise threshold
Recomendaciones de optimización de escena
1. Adaptación de tipo de voz
| Tipo de voz | Parámetros recomendados |
|---|
| Masculino | Bass_gain = 2.0, Mid_Frequency = 1200Hz |
| Femenino | treble_gain = 1.5, Bass_gain = 1.5 |
| Niño | Mid_Gain = 1.5, Bass_gain = 1.0 |
2. Configuración del limitador
| Nivel de compresión | Combinación de parámetros |
|---|
| Compresión suave | umbral_db = -20, relación = 2, ataque = 0.3s |
| Compresión media | umbral_db = -25, relación = 3, ataque = 0.2s |
| Compresión pesada | umbral_db = -30, relación = 4, ataque = 0.1s |
3. Configuración del ecualizador
| Objetivo de calidad de sonido | Combinación de parámetros |
|---|
| Mejora de la voz | agudos = 2.0, bajo = 1.0 |
| Impulso de claridad | agudos = 3.0, bajo = -1.0 |
| Tono cálido | agudos = -1.0, bajo = 2.0 |
Precauciones de uso
- Protección de funciones de audio
- Evite el sobreprocesamiento que conduce a la distorsión
- Mantener la claridad del límite del fonema
- Preservar la prosodia del habla natural
- Adaptación del conjunto de datos
- Ajustar los parámetros basados en las características del altavoz
- Considere registrar factores ambientales
- Mantener la consistencia del procesamiento
- Control de calidad
- Verifique regularmente los efectos de procesamiento
- Monitorear muestras anormales
- Ajustar los parámetros a tiempo
Flujo de trabajo de las mejores prácticas
- Realice el análisis de audio primero
- Seleccionar parámetros basados en el informe de análisis
- Efectos del proceso de prueba en lotes pequeños
- Ajustar y optimizar la configuración de los parámetros
- Ejecutar procesamiento de normalización por lotes
- Verificar la calidad del resultado del procesamiento
A través de la configuración y el uso adecuados de esta herramienta, puede mejorar significativamente la calidad de los datos de capacitación de TTS, proporcionando un mejor soporte de datos de base para la capacitación del modelo.
Información del contacto
Veloz


