Ttsaudormalizer
中文文档
TTSaudiOrmalizer - это профессиональный инструмент предварительной обработки аудио, который предоставляет комплексный аудиозализаку и возможности обработки стандартизации. Этот инструмент направлен на улучшение качества данных обучения TTS и обеспечения согласованности в аудио -функциях.
Необходимость стандартизации звука TTS
I. Улучшить модельные тренировочные эффекты
1. Оптимизировать процесс обучения
- Унифицированные уровни объема помогают моделям сосредоточиться на обучении речевых особенностях, а не отвлекаться от различий в объеме
- Стандартизированные данные помогают моделям сходиться быстрее, сокращая время обучения
- Снижает риск обучения моделям неверных функций
2. предотвратить обучение аномалии
- Избегайте градиентного взрыва или исчезновения из -за больших различий в объеме
- Уменьшить возможность переосмысления модели до объема
- Улучшить стабильность процесса обучения
3. Повышение способности обобщения
- Помогите моделям сосредоточиться на изучении основных речевых функций
- Улучшить адаптивность модели в разных сценариях
- Уменьшить зависимость от некритических особенностей
II Обеспечить качество звука
1. Речь ясность
- Оптимизировать частотную реакцию, подчеркнуть ключевые полосы речевых частот
- Повысить ясность согласной, улучшить разборчивость речи
- Поддерживать естественность гласного, сохранить характеристики голоса
2. Управление шумом
- Удалить фоновый шум, улучшить чистоту речи
- Сжатие динамического диапазона, уровни объема баланса
- Отфильтруйте бесполезные полосы частот, уменьшить интерференционные коэффициенты
Iii. Обеспечить согласованность данных
1. Техническая спецификация Разнообразие
- Объединить скорость отбора проб, обеспечить качество данных
- Стандартизировать настройки канала, упростить поток обработки
- Стандартизировать аудиоформат, улучшить совместимость
2. Оптимизация извлечения функций
- Повышение точности извлечения функций и надежности
- Повышение сравнения между различными образцами
- Обеспечить согласованность качества обучения данных
Рекомендуемый процесс стандартизации:
1. Основная предварительная обработка
- Объединение формата
- Преобразовать различные аудиоформаты (например, в WAV)
- Обеспечить совместимость с форматом
- Объединение скорости дискретизации
- Стандартизировать скорость выборки (например, 22050 Гц)
- Поддерживать согласованность данных
- Моно -канал преобразование
- Преобразовать многоканальный звук в моно
- Упростить последующую обработку
2. Оптимизация качества звука?
- DC смещение смещения
- Устранение фиксированного смещения в аудиосигналах
- Улучшить качество звука
- Нормализация объема
- Объединить уровни объема звука
- Обеспечить последовательность громкости
- Оптимизация частотной характеристики
- Регулируйте частотные характеристики
- Оптимизировать производительность звука
3. Обработка шума?
- Удаление тишины
- Очистить неверные аудио сегменты
- Повысить качество данных
- Шумоподавление
- Устранить фоновый шум
- Улучшить ясность звука
- Динамическое сжатие диапазона
- Баланс звуковой динамический диапазон
- Повысить общую производительность
4. Проверка качества ✅
- Валидация качества
- Проверьте обработанное качество звука
- Обеспечить выполнение требований к обучению
- Проверка функции
- Проверьте параметры аудио функции
- Гарантия эффективного извлечения функций
Обработка потоковой диаграммы:
Input Audio ➡ Basic Preprocessing ➡ Quality Optimization ➡ Noise Processing ➡ Quality Check ➡ Output Audio
Важные примечания:
- Поддерживать журналы обработки для каждого шага
- Выполните проверки качества в ключевых точках
- Сохранить оригинальные резервные копии аудио
- Настроить параметры на основе конкретных сценариев применения
Основные функции
1. Анализ аудио
- Генерировать подробный отчет о статистике громкости
- Обеспечить визуализацию распределения объема
- Предложения по оптимизации выходных параметров
from audio_analyzer import AudioAnalyzer
analyzer = AudioAnalyzer ()
results = analyzer . analyze_speaker_directory (
base_dir = "raw_voices" , # Nested folders, i.e., a main folder containing several subfolders (with audio files)
output_dir = "analysis_report" ,
max_workers = 16
)Результаты:
发现 49 个说话人目录
处理说话人: 0%| | 0/49 [00:00<?, ?it/s]
分析说话人: 廉颇
分析音频: 0%| | 0/118 [00:00<?, ?it/s]
分析音频: 25%|██▌ | 30/118 [00:00<00:00, 289.97it/s]
分析音频: 53%|█████▎ | 62/118 [00:00<00:00, 299.46it/s]
分析音频: 78%|███████▊ | 92/118 [00:00<00:00, 298.95it/s]
音频分析报告 说话人: 廉颇:
--------------------------------------------------
分析的音频文件总数: 118
音量统计:
Mean Norm:
mean: 0.053
std: 0.010
min: 0.032
max: 0.082
RMS Amplitude:
mean: 0.089
std: 0.015
min: 0.057
max: 0.131
Max Amplitude:
mean: 0.546
std: 0.123
min: 0.293
max: 0.882
处理说话人: 2%|▏ | 1/49 [00:01<01:03, 1.31s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.053
2. 平衡设置 (确保清晰度): target_db = 0.063
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/廉颇
分析说话人: 小乔
分析音频: 0%| | 0/201 [00:00<?, ?it/s]
分析音频: 14%|█▍ | 28/201 [00:00<00:00, 268.48it/s]
分析音频: 29%|██▉ | 58/201 [00:00<00:00, 283.83it/s]
分析音频: 43%|████▎ | 87/201 [00:00<00:00, 281.59it/s]
分析音频: 60%|█████▉ | 120/201 [00:00<00:00, 297.76it/s]
分析音频: 75%|███████▍ | 150/201 [00:00<00:00, 294.95it/s]
分析音频: 90%|████████▉ | 180/201 [00:00<00:00, 289.50it/s]
音频分析报告 说话人: 小乔:
--------------------------------------------------
分析的音频文件总数: 201
音量统计:
Mean Norm:
mean: 0.052
std: 0.019
min: 0.012
max: 0.135
RMS Amplitude:
mean: 0.086
std: 0.030
min: 0.024
max: 0.209
Max Amplitude:
mean: 0.495
std: 0.143
min: 0.163
max: 0.943
处理说话人: 4%|▍ | 2/49 [00:02<01:09, 1.49s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.052
2. 平衡设置 (确保清晰度): target_db = 0.071
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/小乔
分析说话人: 赵云
分析音频: 0%| | 0/142 [00:00<?, ?it/s]
分析音频: 20%|█▉ | 28/142 [00:00<00:00, 270.67it/s]
分析音频: 42%|████▏ | 60/142 [00:00<00:00, 294.19it/s]
分析音频: 63%|██████▎ | 90/142 [00:00<00:00, 291.33it/s]
分析音频: 85%|████████▍ | 120/142 [00:00<00:00, 283.42it/s]
音频分析报告 说话人: 赵云:
--------------------------------------------------
分析的音频文件总数: 142
音量统计:
Mean Norm:
mean: 0.050
std: 0.019
min: 0.018
max: 0.124
RMS Amplitude:
mean: 0.089
std: 0.031
min: 0.039
max: 0.193
Max Amplitude:
mean: 0.603
std: 0.182
min: 0.339
max: 1.000
处理说话人: 6%|▌ | 3/49 [00:04<01:06, 1.45s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.050
2. 平衡设置 (确保清晰度): target_db = 0.070
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/赵云
...
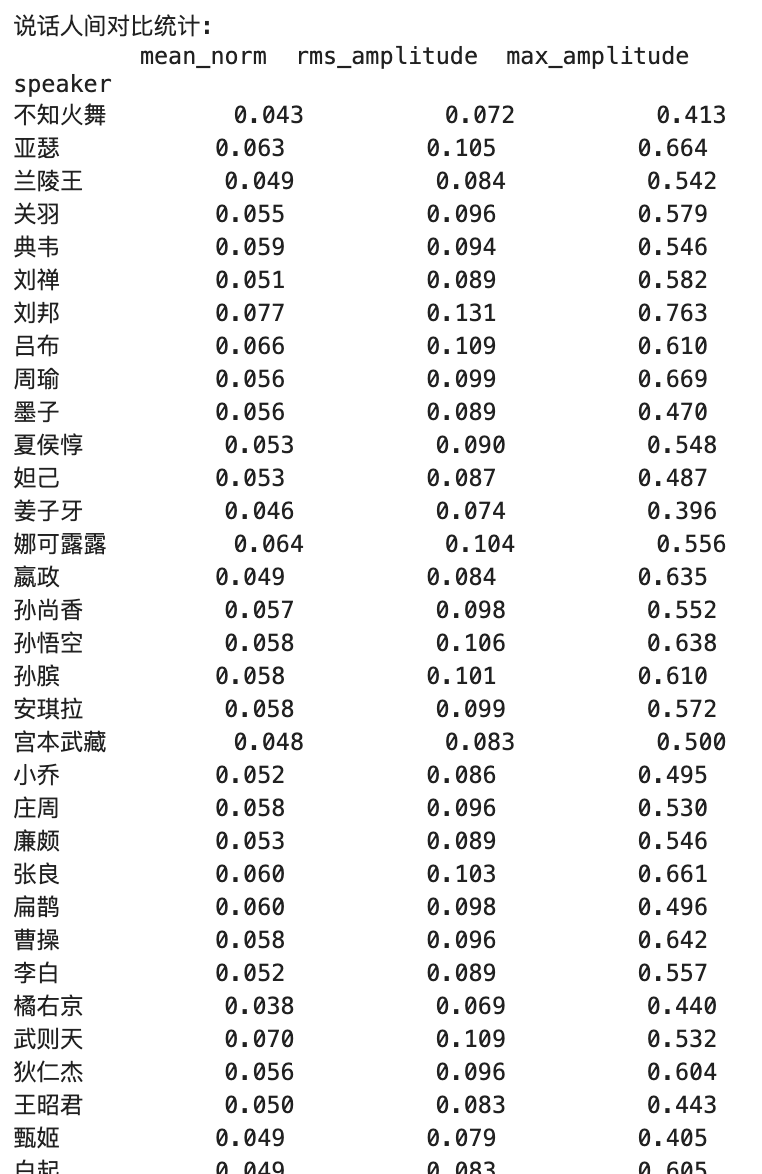
Ключевые метрики Объяснение :
1. Средняя норма
- Практическое значение :
- Отражает общий уровень громкости звука
- Представляет среднюю абсолютную амплитуду аудиосигнала
- Диапазон значений обычно между 0-1
- Значение значения :
- Более высокое значение = громче общее восприятие
- Более низкое значение = более мягкое общее восприятие
- Идеальный диапазон обычно между 0,1-0,3
- Сценарии приложения :
- Используется для оценки того, подходит ли общая громкость
- Помогает определить, необходимо ли увеличение объема
2. RMS -амплитуда
- Практическое значение :
- Отражает эффективный уровень энергии аудио
- Ближе к восприятию громкости человека
- Рассматривает энергосбережение с течением времени
- Значение значения :
- Более высокое значение = более сильная аудиоэнергия
- Более низкое значение = более слабая энергия аудио
- Профессиональный звук обычно рекомендуется между 0,1-0,4
- Сценарии приложения :
- Оценить звуковой динамический диапазон
- Определите, нуждается ли звук сжатие или расширение
- Обычно используется в нормализации звука
3. Макс амплитуда
- Практическое значение :
- Отражает пиковые уровни в аудио
- Представляет максимальное мгновенное значение сигнала
- Используется для определения, существует ли обрезка
- Значение значения :
- 1,0 = максимально возможное значение для цифрового аудио (потенциальная обрезка)
- Рекомендованное пиковое контроль ниже 0,9
- Слишком низкий (например, <0,5) указывает на то, что звук может быть слишком мягким
- Сценарии приложения :
- Обнаружить искажение звука
- Оценить аудиосадочный запас
- Настройки ограничителя гида
Отношения между тремя
Иерархические отношения :
- Максимальная амплитуда> Амплитуда среднеквадратичных средств> Средняя норма
- Это связано с их различными методами расчета
Практическое применение :
- Средняя норма: используется для общей оценки объема
- RMS: используется для управления уровнем энергии
- Максимальная амплитуда: используется для пикового контроля
Справочные идеальные значения
- Профессиональные справочные значения производства аудио :
- Средняя норма: 0,1-0,3
- RMS: 0,1-0,4
- Максимальная амплитуда: 0,8-0,9
Рекомендации по использованию
- Сначала проверьте максимальную амплитуду, чтобы избежать обрезки
- Используйте RMS, чтобы обеспечить подходящую энергию
- Справочная средняя норма для корректировки общего объема
- Рассмотрим все три показателя в контексте конкретного применения
Эти показатели работают вместе, чтобы помочь нам:
- Обеспечить качество звука
- Поддерживать согласованность объема
- Избегайте искажений и шума
- Оптимизировать опыт прослушивания
2. Нормализация звука
Ключевые особенности этого решения:
- Использует эффект нормы SOX для нормализации звука
- Может обработать отдельные файлы или пакетный процесс целых каталогов
- По умолчанию нормализацию объема до -3db, регулируемый по мере необходимости
- Поддерживает оригинальное качество звука, только регулирует громкость
Использование просто:
- Для отдельного файла: непосредственно вызовать функцию normalize_audio ()
- Для всего каталога: используйте функцию batch_normalize_directory (). Обработанные аудиофайлы должны иметь более равномерные уровни громкости, решая проблему противоречивой громкости. Если общий объем все еще кажется слишком низким или высоким, отрегулируйте параметр Target_DB.
from tts_audio_normalizer import AudioProcessingParams , TTSAudioNormalizer
# Create parameter object and customize parameters
params = AudioProcessingParams ()
params . noise_reduction_strength = 0.8 # Increase noise reduction intensity
params . target_db = - 3 # Set target volume
# Process single file
#normalizer.normalize_audio("input.wav", "output.wav", params)
# Batch process directory
normalizer . batch_normalize_directory (
input_dir = "./audio_segments" ,
output_dir = "./audio_segments_normalized" ,
params = params ,
max_workers = 4
)Руководство по конфигурации параметров
1. Основные параметры
# Basic format settings
rate : int = 44100 # Sample rate
channels : int = 1 # Number of channels
output_format : str = 'wav' # Output format
target_db : float = - 3.0 # Target volume
2. Параметры оптимизации качества звука
# Equalizer settings
equalizer_enabled : bool = True # Enable equalizer
treble_frequency : float = 3000.0 # Treble center (2-8kHz)
mid_frequency : float = 1000.0 # Mid center (250Hz-2kHz)
bass_frequency : float = 100.0 # Bass center (80-250Hz)
3. Параметры шумоподавления
# Noise processing
subsonic_filter_enabled : bool = True # Subsonic filtering
compression_ratio : float = 2.5 # Compression ratio
threshold_db : float = - 15.0 # Noise threshold
Рекомендации по оптимизации сцены
1. Адаптация типа голоса
| Тип голоса | Рекомендуемые параметры |
|---|
| Мужской | bass_gain = 2,0, mid_frequency = 1200 Гц |
| Женский | treble_gain = 1,5, bass_gain = 1,5 |
| Ребенок | mid_gain = 1,5, bass_gain = 1,0 |
2. Конфигурация ограничителя
| Уровень сжатия | Комбинация параметров |
|---|
| Легкое сжатие | threshold_db = -20, соотношение = 2, атака = 0,3 с |
| Среднее сжатие | threshold_db = -25, соотношение = 3, атака = 0,2 с |
| Тяжелое сжатие | threshold_db = -30, соотношение = 4, атака = 0,1 с |
3. Конфигурация эквалайзера
| Цель качества звука | Комбинация параметров |
|---|
| Улучшение голоса | Требл = 2,0, бас = 1,0 |
| Повышение ясности | Требл = 3,0, бас = -1,0 |
| Теплый тон | Требл = -1,0, бас = 2,0 |
Использование мер предосторожности
- Аудио -функция защита
- Избегайте переработки, приводя к искажению
- Поддерживать ясность границы фонем
- Сохранить естественную речь просодию
- Адаптация набора данных
- Настроить параметры на основе характеристик динамика
- Рассмотрим регистрацию факторов окружающей среды
- Поддерживать последовательность обработки
- Контроль качества
- Регулярно проверяйте эффекты обработки
- Мониторинг ненормальных образцов
- Своевременно отрегулируйте параметры
Лучший рабочий процесс
- Сначала выполнить аудио -анализ
- Выберите параметры на основе отчета об анализе
- Процесс процесса на небольшую партию
- Настроить и оптимизировать конфигурацию параметров
- Выполнить обработку нормализации партии
- Проверьте качество результатов обработки
Благодаря надлежащей конфигурации и использованию этого инструмента вы можете значительно улучшить качество данных обучения TTS, обеспечивая лучшую поддержку данных основания для обучения модели.
Контактная информация
WeChat


