Ttsaudionormalizer
中文文档
TTSaudionormalizer est un outil professionnel de prétraitement audio TTS qui fournit des capacités complètes d'analyse audio et de normalisation. Cet outil vise à améliorer la qualité des données de formation TTS et à garantir la cohérence des fonctionnalités audio.
Nécessité de standardisation audio TTS
I. Améliorer les effets de la formation des modèles
1. Optimiser le processus d'apprentissage
- Les niveaux de volume unifiés aident les modèles à se concentrer sur l'apprentissage des caractéristiques de la parole plutôt que d'être distraits par des différences de volume
- Les données standardisées aident les modèles à converger plus rapidement, réduisant le temps de formation
- Réduit le risque d'apprentissage des fonctionnalités incorrectes
2. Empêcher les anomalies de formation
- Évitez l'explosion du gradient ou la disparition en raison de différences de volumes importantes
- Réduisez la possibilité de sur-ajustement du modèle aux fonctionnalités de volume
- Améliorer la stabilité du processus de formation
3. Améliorer la capacité de généralisation
- Aide les modèles à se concentrer sur l'apprentissage des caractéristiques de la parole essentielle
- Améliorer l'adaptabilité du modèle dans différents scénarios
- Réduire la dépendance des caractéristiques non critiques
Ii Assurer la qualité audio
1. Clarité de la parole
- Optimiser la réponse en fréquence, mettant l'accent sur les bandes de fréquence de la parole clés
- Améliorer la clarté des consonnes, améliorer l'intelligibilité de la parole
- Maintenir le naturel de voyelle, préserver les caractéristiques de la voix
2. Contrôle du bruit
- Supprimer le bruit de fond, améliorer la pureté de la parole
- Comprimer Dynamic Range, Niveaux de volume d'équilibre
- Filtre les bandes de fréquence inutiles, réduire les facteurs d'interférence
Iii. Assurer la cohérence des données
1. Uniformité des spécifications techniques
- Unifier le taux d'échantillonnage, assurer la qualité des données
- Standardiser les paramètres du canal, simplifier le flux de traitement
- Format audio standardisé, améliorer la compatibilité
2. Optimisation d'extraction des fonctionnalités
- Améliorer la précision et la fiabilité de l'extraction des fonctionnalités
- Améliorer la comparabilité entre différents échantillons
- Assurer la cohérence de la qualité des données de formation
Processus de normalisation recommandé:
1. Prétraitement de base
- Unification de format
- Convertir différents formats audio (par exemple, en wav)
- Assurer la compatibilité du format
- Unification du taux d'échantillon
- Taux d'échantillonnage standardisé (par exemple, 22050Hz)
- Maintenir la cohérence des données
- Conversion de canal mono
- Convertir l'audio multicanal en mono
- Simplifier le traitement ultérieur
2. Optimisation de la qualité audio?
- Retrait du décalage CC
- Éliminer le décalage fixe dans les signaux audio
- Améliorer la qualité de l'audio
- Normalisation du volume
- Unifier les niveaux de volume audio
- Assurer la cohérence de l'intensité
- Optimisation de la réponse en fréquence
- Ajuster les caractéristiques de fréquence
- Optimiser les performances audio
3. Traitement du bruit?
- Suppression de silence
- Nettoyer des segments audio non valides
- Améliorer la qualité des données
- Réduction du bruit
- Éliminer le bruit de fond
- Améliorer la clarté de l'audio
- Compression de plage dynamique
- Équilibrer la plage dynamique audio
- Améliorer les performances globales
4. Vérification de la qualité ✅
- Validation de qualité
- Vérifier la qualité audio traitée
- Assurer que les exigences de formation sont respectées
- Validation des fonctionnalités
- Vérifiez les paramètres des fonctionnalités audio
- Garantir l'extraction des fonctionnalités efficaces
Diagramme de flux de traitement:
Input Audio ➡️ Basic Preprocessing ➡️ Quality Optimization ➡️ Noise Processing ➡️ Quality Check ➡️ Output Audio
Remarques importantes:
- Maintenir les journaux de traitement pour chaque étape
- Effectuer des vérifications de qualité aux points clés
- Gardez les sauvegardes audio originales
- Ajuster les paramètres en fonction des scénarios d'application spécifiques
Fonctions principales
1. Analyse audio
- Générer un rapport détaillé de statistiques sur le volume
- Fournir une visualisation de distribution de volume
- Suggestions d'optimisation des paramètres de sortie
from audio_analyzer import AudioAnalyzer
analyzer = AudioAnalyzer ()
results = analyzer . analyze_speaker_directory (
base_dir = "raw_voices" , # Nested folders, i.e., a main folder containing several subfolders (with audio files)
output_dir = "analysis_report" ,
max_workers = 16
)Résultats:
发现 49 个说话人目录
处理说话人: 0%| | 0/49 [00:00<?, ?it/s]
分析说话人: 廉颇
分析音频: 0%| | 0/118 [00:00<?, ?it/s]
分析音频: 25%|██▌ | 30/118 [00:00<00:00, 289.97it/s]
分析音频: 53%|█████▎ | 62/118 [00:00<00:00, 299.46it/s]
分析音频: 78%|███████▊ | 92/118 [00:00<00:00, 298.95it/s]
音频分析报告 说话人: 廉颇:
--------------------------------------------------
分析的音频文件总数: 118
音量统计:
Mean Norm:
mean: 0.053
std: 0.010
min: 0.032
max: 0.082
RMS Amplitude:
mean: 0.089
std: 0.015
min: 0.057
max: 0.131
Max Amplitude:
mean: 0.546
std: 0.123
min: 0.293
max: 0.882
处理说话人: 2%|▏ | 1/49 [00:01<01:03, 1.31s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.053
2. 平衡设置 (确保清晰度): target_db = 0.063
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/廉颇
分析说话人: 小乔
分析音频: 0%| | 0/201 [00:00<?, ?it/s]
分析音频: 14%|█▍ | 28/201 [00:00<00:00, 268.48it/s]
分析音频: 29%|██▉ | 58/201 [00:00<00:00, 283.83it/s]
分析音频: 43%|████▎ | 87/201 [00:00<00:00, 281.59it/s]
分析音频: 60%|█████▉ | 120/201 [00:00<00:00, 297.76it/s]
分析音频: 75%|███████▍ | 150/201 [00:00<00:00, 294.95it/s]
分析音频: 90%|████████▉ | 180/201 [00:00<00:00, 289.50it/s]
音频分析报告 说话人: 小乔:
--------------------------------------------------
分析的音频文件总数: 201
音量统计:
Mean Norm:
mean: 0.052
std: 0.019
min: 0.012
max: 0.135
RMS Amplitude:
mean: 0.086
std: 0.030
min: 0.024
max: 0.209
Max Amplitude:
mean: 0.495
std: 0.143
min: 0.163
max: 0.943
处理说话人: 4%|▍ | 2/49 [00:02<01:09, 1.49s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.052
2. 平衡设置 (确保清晰度): target_db = 0.071
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/小乔
分析说话人: 赵云
分析音频: 0%| | 0/142 [00:00<?, ?it/s]
分析音频: 20%|█▉ | 28/142 [00:00<00:00, 270.67it/s]
分析音频: 42%|████▏ | 60/142 [00:00<00:00, 294.19it/s]
分析音频: 63%|██████▎ | 90/142 [00:00<00:00, 291.33it/s]
分析音频: 85%|████████▍ | 120/142 [00:00<00:00, 283.42it/s]
音频分析报告 说话人: 赵云:
--------------------------------------------------
分析的音频文件总数: 142
音量统计:
Mean Norm:
mean: 0.050
std: 0.019
min: 0.018
max: 0.124
RMS Amplitude:
mean: 0.089
std: 0.031
min: 0.039
max: 0.193
Max Amplitude:
mean: 0.603
std: 0.182
min: 0.339
max: 1.000
处理说话人: 6%|▌ | 3/49 [00:04<01:06, 1.45s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.050
2. 平衡设置 (确保清晰度): target_db = 0.070
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/赵云
...
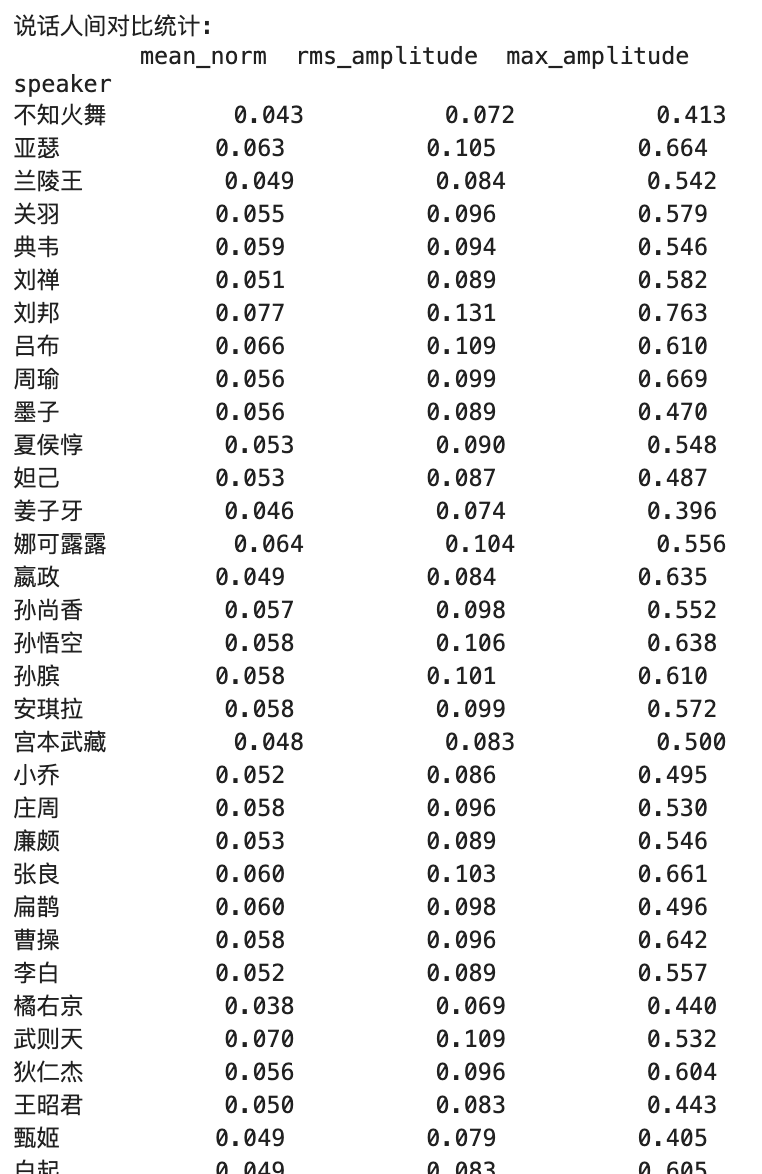
Explication des mesures clés :
1. Norme moyenne
- Signification pratique :
- Reflète le niveau global de sondage de l'audio
- Représente une amplitude absolue moyenne du signal audio
- Plage de valeurs généralement entre 0-1
- Valuer Signification :
- Valeur plus élevée = perception globale plus forte
- Valeur inférieure = perception globale plus douce
- Plage idéale généralement entre 0,1 et 0,3
- Scénarios d'application :
- Utilisé pour évaluer si le volume global est approprié
- Aide à déterminer si un gain de volume est nécessaire
2. Amplitude RMS
- Signification pratique :
- Reflète un niveau d'énergie efficace de l'audio
- Plus près de la perception de l'oreille humaine de l'intensité
- Considère la distribution d'énergie au fil du temps
- Valuer Signification :
- Valeur plus élevée = énergie audio plus forte
- Valeur inférieure = énergie audio plus faible
- L'audio professionnel recommandait généralement de 0,1-0,4
- Scénarios d'application :
- Évaluer la plage de dynamique audio
- Déterminez si l'audio a besoin de compression ou d'expansion
- Couramment utilisé dans la normalisation audio
3. Amplitude maximale
- Signification pratique :
- Reflète les niveaux de pointe en audio
- Représente une valeur instantanée maximale du signal
- Utilisé pour déterminer si l'écrêtage existe
- Valuer Signification :
- 1,0 = valeur maximale possible pour l'audio numérique (coupure potentielle)
- Contrôle de crête recommandé en dessous de 0,9
- Trop bas (par exemple, <0,5) indique que l'audio pourrait être trop doux
- Scénarios d'application :
- Détecter la distorsion audio
- Évaluer la marge de pointe
- Paramètres des limiteurs de guidage
Relation entre les trois
Relation hiérarchique :
- Amplitude maximale> Amplitude RMS> Norme moyenne
- Cela est dû à leurs différentes méthodes de calcul
Application pratique :
- Norme moyenne: utilisée pour l'évaluation globale du volume
- RMS: utilisé pour le contrôle du niveau d'énergie
- Amplitude maximale: utilisée pour le contrôle de pointe
Référence Valeurs idéales
- Valeurs de référence de production audio professionnelle :
- Norme moyenne: 0,1-0.3
- RMS: 0,1-0.4
- Amplitude maximale: 0,8-0,9
Recommandations d'utilisation
- Vérifiez d'abord l'amplitude maximale pour éviter l'écrasement
- Utiliser RMS pour garantir que l'énergie globale est appropriée
- Norme moyenne de référence pour ajuster le volume global
- Considérez les trois indicateurs dans le contexte d'une application spécifique
Ces indicateurs travaillent ensemble pour nous aider:
- Assurer la qualité audio
- Maintenir la cohérence du volume
- Évitez la distorsion et le bruit
- Optimiser l'expérience d'écoute
2. Normalisation audio
Caractéristiques clés de cette solution:
- Utilise l'effet normal de Sox pour la normalisation audio
- Peut traiter des fichiers uniques ou un traitement par lots entiers répertoires
- Par défaut de normalisation du volume à -3 dB, réglable au besoin
- Maintient la qualité audio d'origine, n'ajuste que le volume
L'utilisation est simple:
- Pour un seul fichier: appelez directement Normalize_Audio ()
- Pour le répertoire entier: utilisez Batch_Normalize_Directory () Fonction Les fichiers audio traités doivent avoir des niveaux de volume plus uniformes, résolvant la question de l'intensité incohérente. Si le volume global est toujours trop faible ou élevé, ajustez le paramètre Target_DB.
from tts_audio_normalizer import AudioProcessingParams , TTSAudioNormalizer
# Create parameter object and customize parameters
params = AudioProcessingParams ()
params . noise_reduction_strength = 0.8 # Increase noise reduction intensity
params . target_db = - 3 # Set target volume
# Process single file
#normalizer.normalize_audio("input.wav", "output.wav", params)
# Batch process directory
normalizer . batch_normalize_directory (
input_dir = "./audio_segments" ,
output_dir = "./audio_segments_normalized" ,
params = params ,
max_workers = 4
)Guide de configuration des paramètres
1. Paramètres de base
# Basic format settings
rate : int = 44100 # Sample rate
channels : int = 1 # Number of channels
output_format : str = 'wav' # Output format
target_db : float = - 3.0 # Target volume
2. Paramètres d'optimisation de la qualité sonore
# Equalizer settings
equalizer_enabled : bool = True # Enable equalizer
treble_frequency : float = 3000.0 # Treble center (2-8kHz)
mid_frequency : float = 1000.0 # Mid center (250Hz-2kHz)
bass_frequency : float = 100.0 # Bass center (80-250Hz)
3. Paramètres de réduction du bruit
# Noise processing
subsonic_filter_enabled : bool = True # Subsonic filtering
compression_ratio : float = 2.5 # Compression ratio
threshold_db : float = - 15.0 # Noise threshold
Recommandations d'optimisation de la scène
1. Adaptation de type vocal
| Type de voix | Paramètres recommandés |
|---|
| Mâle | bass_gain = 2.0, mid_frequency = 1200Hz |
| Femelle | Treble_gain = 1,5, bass_gain = 1,5 |
| Enfant | mid_gain = 1,5, bass_gain = 1.0 |
2. Configuration du limiteur
| Niveau de compression | Combinaison de paramètres |
|---|
| Compression légère | threshold_db = -20, rapport = 2, attaque = 0,3S |
| Compression moyenne | threshold_db = -25, rapport = 3, attaque = 0,2 s |
| Compression lourde | threshold_db = -30, rapport = 4, attaque = 0,1 |
3. Configuration d'égaliseur
| Objectif de qualité sonore | Combinaison de paramètres |
|---|
| Amélioration de la voix | Treble = 2,0, basse = 1,0 |
| Boost de clarté | Treble = 3,0, basse = -1,0 |
| Ton chaud | Treble = -1,0, basse = 2,0 |
Précautions d'utilisation
- Protection des fonctionnalités audio
- Évitez le trop-traitement conduisant à la distorsion
- Maintenir la clarté des limites phonèques
- Préserver le discours naturel Prosody
- Adaptation de l'ensemble de données
- Ajuster les paramètres en fonction des caractéristiques du haut-parleur
- Envisagez d'enregistrer les facteurs environnementaux
- Maintenir la cohérence du traitement
- Contrôle de qualité
- Vérifiez régulièrement les effets de traitement
- Surveiller les échantillons anormaux
- Ajuster les paramètres en temps opportun
Flux de travail des meilleures pratiques
- Effectuer une analyse audio d'abord
- Sélectionnez des paramètres basés sur le rapport d'analyse
- Effets du processus de test sur un petit lot
- Ajuster et optimiser la configuration des paramètres
- Exécuter le traitement de la normalisation par lots
- Vérifiez la qualité des résultats du traitement
Grâce à une configuration et à une utilisation appropriées de cet outil, vous pouvez améliorer considérablement la qualité des données de la formation TTS, offrant une meilleure prise en charge des données de base pour la formation des modèles.
Coordonnées
Wechat


