Ttsudionormalizer
中文文档
TTSADIONORMALIZER adalah alat preprocessing audio TTS profesional yang menyediakan analisis audio yang komprehensif dan kemampuan pemrosesan standardisasi. Alat ini bertujuan untuk meningkatkan kualitas data pelatihan TTS dan memastikan konsistensi dalam fitur audio.
Kebutuhan standardisasi audio TTS
I. Meningkatkan Efek Pelatihan Model
1. Mengoptimalkan proses pembelajaran
- Level volume terpadu membantu model fokus pada fitur wicara belajar daripada terganggu oleh perbedaan volume
- Data standar membantu model konvergen lebih cepat, mengurangi waktu pelatihan
- Mengurangi risiko model belajar fitur yang salah
2. Cegah anomali pelatihan
- Hindari ledakan gradien atau menghilang karena perbedaan volume yang besar
- Kurangi kemungkinan overfitting model ke fitur volume
- Tingkatkan stabilitas proses pelatihan
3. Tingkatkan kemampuan generalisasi
- Bantuan model fokus pada pembelajaran fitur ucapan penting
- Meningkatkan kemampuan beradaptasi dalam skenario yang berbeda
- Mengurangi ketergantungan pada fitur non-kritis
Ii. Pastikan kualitas audio
1. Kejelasan pidato
- Mengoptimalkan respons frekuensi, tekankan pita frekuensi ucapan utama
- Tingkatkan kejelasan konsonan, tingkatkan kejelasan bicara
- Menjaga kealamian vokal, menjaga karakteristik suara
2. Kontrol kebisingan
- Hapus kebisingan latar belakang, tingkatkan kemurnian bicara
- Kompres rentang dinamis, level volume keseimbangan
- Memfilter pita frekuensi yang tidak berguna, mengurangi faktor interferensi
AKU AKU AKU. Pastikan konsistensi data
1. Keseragaman Spesifikasi Teknis
- Menyatukan laju pengambilan sampel, memastikan kualitas data
- Standarisasi Pengaturan Saluran, sederhanakan aliran pemrosesan
- Standarisasi format audio, tingkatkan kompatibilitas
2. Optimalisasi Ekstraksi Fitur
- Tingkatkan akurasi dan keandalan ekstraksi fitur
- Tingkatkan perbandingan antara sampel yang berbeda
- Pastikan konsistensi kualitas data pelatihan
Proses standardisasi yang disarankan:
1. Preprocessing dasar
- Format unifikasi
- Konversi format audio yang berbeda (misalnya, ke WAV)
- Pastikan kompatibilitas format
- Unifikasi Tingkat Sampel
- Standardize Sampling Rate (misalnya, 22050Hz)
- Pertahankan konsistensi data
- Konversi Saluran Mono
- Konversi audio multi-channel menjadi mono
- Sederhanakan pemrosesan selanjutnya
2. Optimalisasi Kualitas Audio?
- Penghapusan Offset DC
- Menghilangkan offset tetap dalam sinyal audio
- Meningkatkan kualitas audio
- Normalisasi volume
- Menyatukan level volume audio
- Pastikan konsistensi kenyaringan
- Optimasi respons frekuensi
- Sesuaikan karakteristik frekuensi
- Mengoptimalkan kinerja audio
3. Pemrosesan kebisingan?
- Penghapusan Keheningan
- Bersihkan segmen audio yang tidak valid
- Tingkatkan Kualitas Data
- Pengurangan kebisingan
- Menghilangkan kebisingan latar belakang
- Tingkatkan Kejelasan Audio
- Kompresi rentang dinamis
- Saldo rentang dinamis audio
- Tingkatkan kinerja keseluruhan
4. Pemeriksaan Kualitas ✅
- Validasi kualitas
- Periksa kualitas audio yang diproses
- Pastikan persyaratan pelatihan terpenuhi
- Validasi fitur
- Verifikasi parameter fitur audio
- Menjamin ekstraksi fitur yang efektif
Memproses Diagram Alir:
Input Audio ➡️ Basic Preprocessing ➡️ Quality Optimization ➡️ Noise Processing ➡️ Quality Check ➡️ Output Audio
Catatan Penting:
- Pertahankan log pemrosesan untuk setiap langkah
- Lakukan pemeriksaan kualitas pada poin -poin penting
- Simpan cadangan audio asli
- Sesuaikan parameter berdasarkan skenario aplikasi tertentu
Fungsi utama
1. Analisis Audio
- Hasilkan laporan statistik kenyaringan terperinci
- Berikan visualisasi distribusi volume
- Saran optimasi parameter output
from audio_analyzer import AudioAnalyzer
analyzer = AudioAnalyzer ()
results = analyzer . analyze_speaker_directory (
base_dir = "raw_voices" , # Nested folders, i.e., a main folder containing several subfolders (with audio files)
output_dir = "analysis_report" ,
max_workers = 16
)Hasil:
发现 49 个说话人目录
处理说话人: 0%| | 0/49 [00:00<?, ?it/s]
分析说话人: 廉颇
分析音频: 0%| | 0/118 [00:00<?, ?it/s]
分析音频: 25%|██▌ | 30/118 [00:00<00:00, 289.97it/s]
分析音频: 53%|█████▎ | 62/118 [00:00<00:00, 299.46it/s]
分析音频: 78%|███████▊ | 92/118 [00:00<00:00, 298.95it/s]
音频分析报告 说话人: 廉颇:
--------------------------------------------------
分析的音频文件总数: 118
音量统计:
Mean Norm:
mean: 0.053
std: 0.010
min: 0.032
max: 0.082
RMS Amplitude:
mean: 0.089
std: 0.015
min: 0.057
max: 0.131
Max Amplitude:
mean: 0.546
std: 0.123
min: 0.293
max: 0.882
处理说话人: 2%|▏ | 1/49 [00:01<01:03, 1.31s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.053
2. 平衡设置 (确保清晰度): target_db = 0.063
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/廉颇
分析说话人: 小乔
分析音频: 0%| | 0/201 [00:00<?, ?it/s]
分析音频: 14%|█▍ | 28/201 [00:00<00:00, 268.48it/s]
分析音频: 29%|██▉ | 58/201 [00:00<00:00, 283.83it/s]
分析音频: 43%|████▎ | 87/201 [00:00<00:00, 281.59it/s]
分析音频: 60%|█████▉ | 120/201 [00:00<00:00, 297.76it/s]
分析音频: 75%|███████▍ | 150/201 [00:00<00:00, 294.95it/s]
分析音频: 90%|████████▉ | 180/201 [00:00<00:00, 289.50it/s]
音频分析报告 说话人: 小乔:
--------------------------------------------------
分析的音频文件总数: 201
音量统计:
Mean Norm:
mean: 0.052
std: 0.019
min: 0.012
max: 0.135
RMS Amplitude:
mean: 0.086
std: 0.030
min: 0.024
max: 0.209
Max Amplitude:
mean: 0.495
std: 0.143
min: 0.163
max: 0.943
处理说话人: 4%|▍ | 2/49 [00:02<01:09, 1.49s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.052
2. 平衡设置 (确保清晰度): target_db = 0.071
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/小乔
分析说话人: 赵云
分析音频: 0%| | 0/142 [00:00<?, ?it/s]
分析音频: 20%|█▉ | 28/142 [00:00<00:00, 270.67it/s]
分析音频: 42%|████▏ | 60/142 [00:00<00:00, 294.19it/s]
分析音频: 63%|██████▎ | 90/142 [00:00<00:00, 291.33it/s]
分析音频: 85%|████████▍ | 120/142 [00:00<00:00, 283.42it/s]
音频分析报告 说话人: 赵云:
--------------------------------------------------
分析的音频文件总数: 142
音量统计:
Mean Norm:
mean: 0.050
std: 0.019
min: 0.018
max: 0.124
RMS Amplitude:
mean: 0.089
std: 0.031
min: 0.039
max: 0.193
Max Amplitude:
mean: 0.603
std: 0.182
min: 0.339
max: 1.000
处理说话人: 6%|▌ | 3/49 [00:04<01:06, 1.45s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.050
2. 平衡设置 (确保清晰度): target_db = 0.070
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/赵云
...
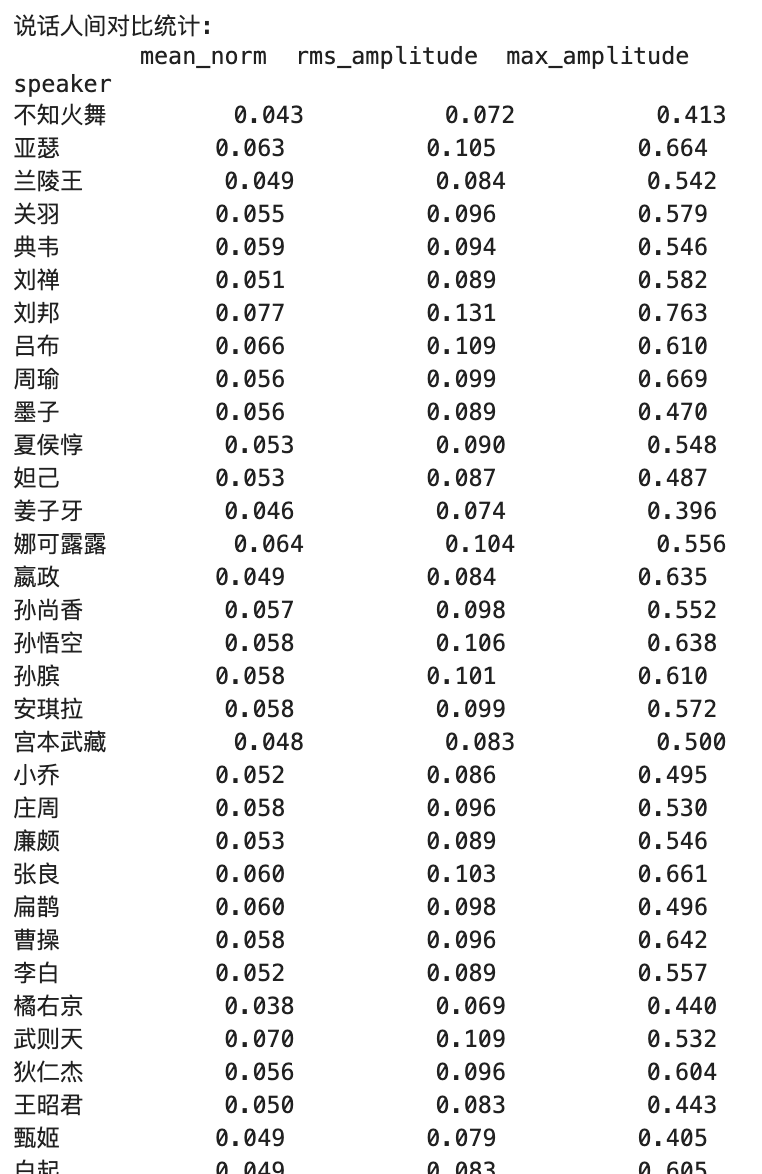
Penjelasan metrik kunci :
1. Norma rata -rata
- Signifikansi Praktis :
- Mencerminkan tingkat kenyaringan keseluruhan audio
- Mewakili amplitudo absolut rata -rata dari sinyal audio
- Kisaran nilai biasanya antara 0-1
- Nilai Arti :
- Nilai lebih tinggi = persepsi keseluruhan yang lebih keras
- Nilai lebih rendah = persepsi keseluruhan yang lebih lembut
- Kisaran ideal biasanya antara 0,1-0,3
- Skenario aplikasi :
- Digunakan untuk mengevaluasi apakah kenyaringan secara keseluruhan sesuai
- Membantu menentukan apakah gain volume diperlukan
2. RMS amplitudo
- Signifikansi Praktis :
- Mencerminkan tingkat energi audio yang efektif
- Lebih dekat dengan persepsi telinga manusia tentang kenyaringan
- Mempertimbangkan distribusi energi dari waktu ke waktu
- Nilai Arti :
- Nilai lebih tinggi = energi audio yang lebih kuat
- Nilai lebih rendah = energi audio yang lebih lemah
- Audio profesional biasanya direkomendasikan antara 0,1-0,4
- Skenario aplikasi :
- Mengevaluasi rentang dinamis audio
- Tentukan apakah audio membutuhkan kompresi atau ekspansi
- Biasa digunakan dalam normalisasi audio
3. amplitudo maks
- Signifikansi Praktis :
- Mencerminkan level puncak dalam audio
- Mewakili nilai instan maksimum dari sinyal
- Digunakan untuk menentukan apakah kliping ada
- Nilai Arti :
- 1.0 = nilai maksimum yang mungkin untuk audio digital (kliping potensial)
- Kontrol puncak yang disarankan di bawah 0,9
- Terlalu rendah (misalnya, <0,5) menunjukkan audio mungkin terlalu lunak
- Skenario aplikasi :
- Mendeteksi distorsi audio
- Evaluasi ruang kepala audio
- Panduan Pengaturan Pembatas
Hubungan antara ketiganya
Hubungan hierarkis :
- Amplitudo maks> amplitudo rms> norma rata -rata
- Ini karena metode perhitungan yang berbeda
Aplikasi Praktis :
- Norma rata -rata: digunakan untuk penilaian volume keseluruhan
- RMS: digunakan untuk kontrol tingkat energi
- Max Amplitude: Digunakan untuk Kontrol Puncak
Referensi Nilai Ideal
- Nilai Referensi Produksi Audio Profesional :
- Norma rata-rata: 0.1-0.3
- RMS: 0.1-0.4
- Max Amplitude: 0.8-0.9
Rekomendasi Penggunaan
- Pertama periksa amplitudo maks untuk menghindari kliping
- Gunakan RMS untuk memastikan energi secara keseluruhan sesuai
- Referensi norma rata -rata untuk menyesuaikan volume keseluruhan
- Pertimbangkan ketiga indikator dalam konteks aplikasi tertentu
Indikator ini bekerja sama untuk membantu kami:
- Pastikan kualitas audio
- Pertahankan konsistensi volume
- Hindari distorsi dan kebisingan
- Mengoptimalkan pengalaman mendengarkan
2. Normalisasi audio
Fitur utama dari solusi ini:
- Menggunakan efek norma Sox untuk normalisasi audio
- Dapat memproses file tunggal atau proses batch seluruh direktori
- Default untuk menormalkan volume ke -3dB, dapat disesuaikan sesuai kebutuhan
- Mempertahankan kualitas audio asli, hanya menyesuaikan volume
Penggunaannya sederhana:
- Untuk file tunggal: langsung hubungi fungsi normalisasi_audio ()
- Untuk seluruh direktori: Gunakan fungsi Batch_normalize_Directory (), file audio yang diproses harus memiliki tingkat volume yang lebih seragam, memecahkan masalah kenyaringan yang tidak konsisten. Jika volume keseluruhan masih terasa terlalu rendah atau tinggi, sesuaikan parameter Target_DB.
from tts_audio_normalizer import AudioProcessingParams , TTSAudioNormalizer
# Create parameter object and customize parameters
params = AudioProcessingParams ()
params . noise_reduction_strength = 0.8 # Increase noise reduction intensity
params . target_db = - 3 # Set target volume
# Process single file
#normalizer.normalize_audio("input.wav", "output.wav", params)
# Batch process directory
normalizer . batch_normalize_directory (
input_dir = "./audio_segments" ,
output_dir = "./audio_segments_normalized" ,
params = params ,
max_workers = 4
)Panduan Konfigurasi Parameter
1. Parameter Dasar
# Basic format settings
rate : int = 44100 # Sample rate
channels : int = 1 # Number of channels
output_format : str = 'wav' # Output format
target_db : float = - 3.0 # Target volume
2. Parameter Optimasi Kualitas Suara
# Equalizer settings
equalizer_enabled : bool = True # Enable equalizer
treble_frequency : float = 3000.0 # Treble center (2-8kHz)
mid_frequency : float = 1000.0 # Mid center (250Hz-2kHz)
bass_frequency : float = 100.0 # Bass center (80-250Hz)
3. Parameter reduksi kebisingan
# Noise processing
subsonic_filter_enabled : bool = True # Subsonic filtering
compression_ratio : float = 2.5 # Compression ratio
threshold_db : float = - 15.0 # Noise threshold
Rekomendasi Optimalisasi Adegan
1. Adaptasi Jenis Suara
| Jenis suara | Parameter yang disarankan |
|---|
| Pria | Bass_gain = 2.0, mid_frequency = 1200Hz |
| Perempuan | treble_gain = 1.5, Bass_gain = 1.5 |
| Anak | MID_GAIN = 1.5, BASS_GAIN = 1.0 |
2. Konfigurasi pembatas
| Tingkat kompresi | Kombinasi parameter |
|---|
| Kompresi ringan | threshold_db = -20, rasio = 2, serangan = 0,3s |
| Kompresi sedang | threshold_db = -25, rasio = 3, serangan = 0,2S |
| Kompresi berat | threshold_db = -30, rasio = 4, serangan = 0,1s |
3. Konfigurasi Equalizer
| Tujuan kualitas suara | Kombinasi parameter |
|---|
| Peningkatan suara | Treble = 2.0, bass = 1.0 |
| Dorongan Kejelasan | treble = 3.0, bass = -1.0 |
| Nada hangat | treble = -1.0, bass = 2.0 |
Tindakan pencegahan penggunaan
- Perlindungan fitur audio
- Hindari pemrosesan berlebih yang mengarah ke distorsi
- Pertahankan Kejelasan Batas Fonem
- Melestarikan prosodi ucapan alami
- Adaptasi dataset
- Sesuaikan parameter berdasarkan karakteristik speaker
- Pertimbangkan untuk merekam faktor lingkungan
- Pertahankan konsistensi pemrosesan
- Kontrol kualitas
- Periksa efek pemrosesan secara teratur
- Pantau sampel abnormal
- Sesuaikan parameter tepat waktu
Alur kerja praktik terbaik
- Melakukan analisis audio terlebih dahulu
- Pilih parameter berdasarkan laporan analisis
- Efek Proses Uji pada Batch Kecil
- Menyesuaikan dan mengoptimalkan konfigurasi parameter
- Mengeksekusi pemrosesan normalisasi batch
- Verifikasi Kualitas Hasil Pemrosesan
Melalui konfigurasi yang tepat dan penggunaan alat ini, Anda dapat secara signifikan meningkatkan kualitas data pelatihan TTS, memberikan dukungan data dasar yang lebih baik untuk pelatihan model.
Informasi kontak
Wechat wechat


