TTSAUDIONORMALIZER
中文文档
O TTSAUDIONORMALIZER é uma ferramenta profissional de pré -processamento de áudio TTS que fornece recursos abrangentes de análise de áudio e processamento de padronização. Essa ferramenta tem como objetivo melhorar a qualidade dos dados do TTS Training e garantir a consistência nos recursos de áudio.
Necessidade de padronização de áudio TTS
I. Melhore os efeitos do treinamento do modelo
1. Otimize o processo de aprendizado
- Os níveis de volume unificados ajudam os modelos a se concentrarem nos recursos de fala da aprendizagem, em vez de se distrair com diferenças de volume
- Os dados padronizados ajudam os modelos a convergir mais rápido, reduzindo o tempo de treinamento
- Reduz o risco de modelos de aprender recursos incorretos
2. Evite anomalias de treinamento
- Evite explosão de gradiente ou desaparecimento devido a grandes diferenças de volume
- Reduza a possibilidade de o excesso de ajuste para os recursos de volume
- Melhorar a estabilidade do processo de treinamento
3. Aumente a capacidade de generalização
- Os modelos de ajuda se concentram no aprendizado de recursos essenciais de fala
- Melhorar a adaptabilidade do modelo em diferentes cenários
- Reduzir a dependência de recursos não críticos
Ii. Garanta a qualidade do áudio
1. Clareza de fala
- Otimizar a resposta de frequência, enfatizar as principais bandas de frequência de fala
- Aumente a clareza consoante, melhore a inteligibilidade da fala
- Mantenha a naturalidade da vogal, preserva as características de voz
2. Controle de ruído
- Remova o ruído de fundo, melhore a pureza da fala
- Compressa faixa dinâmica, níveis de volume de equilíbrio
- Filtrar bandas de frequência inútil, reduzir fatores de interferência
Iii. Garantir a consistência dos dados
1. Uniformidade de especificação técnica
- Unificar a taxa de amostragem, verifique se a qualidade dos dados
- Padronizar as configurações de canal, simplificar o fluxo de processamento
- Padronizar o formato de áudio, melhorar a compatibilidade
2. Otimização de extração de recursos
- Melhorar a precisão e confiabilidade da extração de recursos
- Aumente a comparabilidade entre diferentes amostras
- Garantir a consistência da qualidade dos dados do treinamento
Processo de padronização recomendado:
1. Pré -processamento básico
- Formato Unificação
- Converter diferentes formatos de áudio (por exemplo, em wav)
- Garanta a compatibilidade do formato
- Unificação da taxa de amostra
- Padronizar a taxa de amostragem (por exemplo, 22050Hz)
- Manter a consistência dos dados
- Conversão de canal mono
- Converter áudio multicanal em mono
- Simplifique o processamento subsequente
2. Otimização da qualidade do áudio?
- Remoção de deslocamento de DC
- Eliminar o deslocamento fixo em sinais de áudio
- Melhorar a qualidade do áudio
- Normalização do volume
- Unificar níveis de volume de áudio
- Garanta a consistência do volume
- Otimização da resposta de frequência
- Ajuste as características da frequência
- Otimize o desempenho do áudio
3. Processamento de ruído?
- Remoção do silêncio
- Limpe segmentos de áudio inválidos
- Aprimorar a qualidade dos dados
- Redução de ruído
- Elimine o ruído de fundo
- Melhorar a clareza de áudio
- Compressão de faixa dinâmica
- Balance Audio Dynamic Range
- Aumente o desempenho geral
4. Verificação de qualidade ✅
- Validação de qualidade
- Verifique a qualidade do áudio processado
- Garantir que os requisitos de treinamento sejam atendidos
- Validação do recurso
- Verifique os parâmetros do recurso de áudio
- Garantir extração efetiva de recursos
Diagrama de fluxo de processamento:
Input Audio ➡️ Basic Preprocessing ➡️ Quality Optimization ➡️ Noise Processing ➡️ Quality Check ➡️ Output Audio
Notas importantes:
- Mantenha os logs de processamento para cada etapa
- Realizar verificações de qualidade em pontos -chave
- Mantenha backups de áudio originais
- Ajuste os parâmetros com base em cenários de aplicação específicos
Funções principais
1. Análise de áudio
- Gerar relatório de estatísticas de sonoridade detalhada
- Fornecer visualização de distribuição de volume
- Sugestões de otimização de parâmetros de saída
from audio_analyzer import AudioAnalyzer
analyzer = AudioAnalyzer ()
results = analyzer . analyze_speaker_directory (
base_dir = "raw_voices" , # Nested folders, i.e., a main folder containing several subfolders (with audio files)
output_dir = "analysis_report" ,
max_workers = 16
)Resultados:
发现 49 个说话人目录
处理说话人: 0%| | 0/49 [00:00<?, ?it/s]
分析说话人: 廉颇
分析音频: 0%| | 0/118 [00:00<?, ?it/s]
分析音频: 25%|██▌ | 30/118 [00:00<00:00, 289.97it/s]
分析音频: 53%|█████▎ | 62/118 [00:00<00:00, 299.46it/s]
分析音频: 78%|███████▊ | 92/118 [00:00<00:00, 298.95it/s]
音频分析报告 说话人: 廉颇:
--------------------------------------------------
分析的音频文件总数: 118
音量统计:
Mean Norm:
mean: 0.053
std: 0.010
min: 0.032
max: 0.082
RMS Amplitude:
mean: 0.089
std: 0.015
min: 0.057
max: 0.131
Max Amplitude:
mean: 0.546
std: 0.123
min: 0.293
max: 0.882
处理说话人: 2%|▏ | 1/49 [00:01<01:03, 1.31s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.053
2. 平衡设置 (确保清晰度): target_db = 0.063
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/廉颇
分析说话人: 小乔
分析音频: 0%| | 0/201 [00:00<?, ?it/s]
分析音频: 14%|█▍ | 28/201 [00:00<00:00, 268.48it/s]
分析音频: 29%|██▉ | 58/201 [00:00<00:00, 283.83it/s]
分析音频: 43%|████▎ | 87/201 [00:00<00:00, 281.59it/s]
分析音频: 60%|█████▉ | 120/201 [00:00<00:00, 297.76it/s]
分析音频: 75%|███████▍ | 150/201 [00:00<00:00, 294.95it/s]
分析音频: 90%|████████▉ | 180/201 [00:00<00:00, 289.50it/s]
音频分析报告 说话人: 小乔:
--------------------------------------------------
分析的音频文件总数: 201
音量统计:
Mean Norm:
mean: 0.052
std: 0.019
min: 0.012
max: 0.135
RMS Amplitude:
mean: 0.086
std: 0.030
min: 0.024
max: 0.209
Max Amplitude:
mean: 0.495
std: 0.143
min: 0.163
max: 0.943
处理说话人: 4%|▍ | 2/49 [00:02<01:09, 1.49s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.052
2. 平衡设置 (确保清晰度): target_db = 0.071
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/小乔
分析说话人: 赵云
分析音频: 0%| | 0/142 [00:00<?, ?it/s]
分析音频: 20%|█▉ | 28/142 [00:00<00:00, 270.67it/s]
分析音频: 42%|████▏ | 60/142 [00:00<00:00, 294.19it/s]
分析音频: 63%|██████▎ | 90/142 [00:00<00:00, 291.33it/s]
分析音频: 85%|████████▍ | 120/142 [00:00<00:00, 283.42it/s]
音频分析报告 说话人: 赵云:
--------------------------------------------------
分析的音频文件总数: 142
音量统计:
Mean Norm:
mean: 0.050
std: 0.019
min: 0.018
max: 0.124
RMS Amplitude:
mean: 0.089
std: 0.031
min: 0.039
max: 0.193
Max Amplitude:
mean: 0.603
std: 0.182
min: 0.339
max: 1.000
处理说话人: 6%|▌ | 3/49 [00:04<01:06, 1.45s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.050
2. 平衡设置 (确保清晰度): target_db = 0.070
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/赵云
...
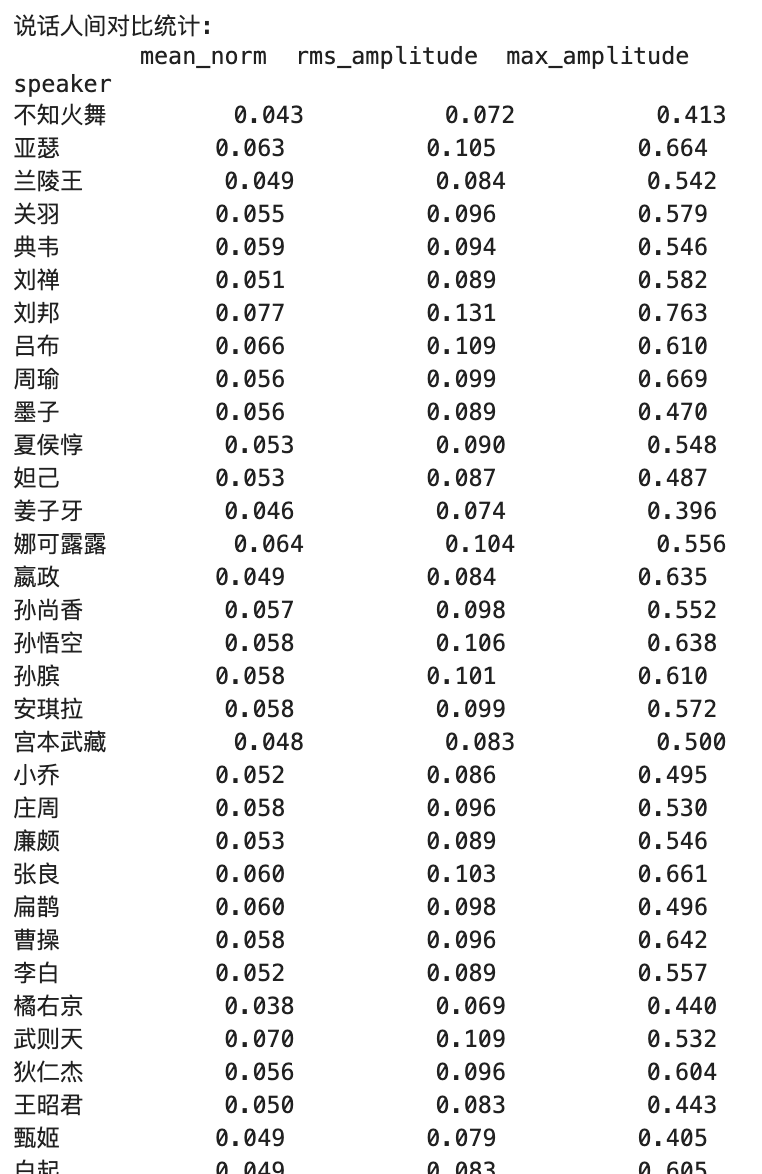
Métricas -chave Explicação :
1. Norma média
- Significado prático :
- Reflete o nível geral de áudio
- Representa uma amplitude absoluta média do sinal de áudio
- Faixa de valor normalmente entre 0-1
- Significado de valor :
- Valor mais alto = percepção geral mais alta
- Valor inferior = percepção geral mais suave
- Faixa ideal tipicamente entre 0,1-0,3
- Cenários de aplicativos :
- Usado para avaliar se o volume geral é apropriado
- Ajuda a determinar se é necessário o ganho de volume
2. Amplitude RMS
- Significado prático :
- Reflete o nível efetivo de energia de áudio
- Mais perto da percepção de volume de volume de ouvido humano
- Considera a distribuição de energia ao longo do tempo
- Significado de valor :
- Valor mais alto = energia de áudio mais forte
- Valor inferior = energia de áudio mais fraca
- O áudio profissional normalmente recomendou entre 0,1-0,4
- Cenários de aplicativos :
- Avalie o alcance dinâmico de áudio
- Determine se o áudio precisa de compactação ou expansão
- Comumente usado na normalização de áudio
3. Amplitude máxima
- Significado prático :
- Reflete os níveis de pico no áudio
- Representa o valor instantâneo máximo do sinal
- Usado para determinar se existe recorte
- Significado de valor :
- 1.0 = Valor máximo possível para áudio digital (recorte em potencial)
- Controle de pico recomendado abaixo de 0,9
- Muito baixo (por exemplo, <0,5) indica que o áudio pode ser muito mole
- Cenários de aplicativos :
- Detecte a distorção de áudio
- Avalie o Headroom de Áudio
- Guia Configurações do limitador
Relação entre os três
Relacionamento hierárquico :
- Amplitude máxima> amplitude rms> norma média
- Isto é devido aos seus diferentes métodos de cálculo
Aplicação prática :
- Norma média: usado para avaliação geral de volume
- RMS: Usado para controle de nível de energia
- Amplitude máxima: usado para controle de pico
Referência valores ideais
- Valores profissionais de referência de produção de áudio :
- Norma média: 0,1-0.3
- RMS: 0.1-0.4
- Amplitude máxima: 0,8-0.9
Recomendações de uso
- Primeiro verifique a amplitude máxima para evitar recorte
- Use RMS para garantir que a energia geral seja apropriada
- Norma média de referência para ajustar o volume geral
- Considere os três indicadores no contexto de aplicação específica
Esses indicadores trabalham juntos para nos ajudar:
- Garanta a qualidade do áudio
- Manter consistência de volume
- Evite distorção e ruído
- Otimize a experiência auditiva
2. Normalização de áudio
Principais recursos desta solução:
- Usa o efeito norma do Sox para normalização de áudio
- Pode processar arquivos únicos ou processar diretórios inteiros em lote
- Padrões para normalizar o volume para -3dB, ajustável conforme necessário
- Mantém a qualidade do áudio original, ajusta apenas o volume
O uso é simples:
- Para um único arquivo: Ligue diretamente a função normalize_audio ()
- Para o diretório inteiro: use Batch_Normalize_Directory () Função Os arquivos de áudio processados devem ter níveis mais uniformes de volume, resolvendo a questão da altura inconsistente. Se o volume geral ainda parecer muito baixo ou alto, ajuste o parâmetro Target_DB.
from tts_audio_normalizer import AudioProcessingParams , TTSAudioNormalizer
# Create parameter object and customize parameters
params = AudioProcessingParams ()
params . noise_reduction_strength = 0.8 # Increase noise reduction intensity
params . target_db = - 3 # Set target volume
# Process single file
#normalizer.normalize_audio("input.wav", "output.wav", params)
# Batch process directory
normalizer . batch_normalize_directory (
input_dir = "./audio_segments" ,
output_dir = "./audio_segments_normalized" ,
params = params ,
max_workers = 4
)Guia de configuração de parâmetros
1. Parâmetros básicos
# Basic format settings
rate : int = 44100 # Sample rate
channels : int = 1 # Number of channels
output_format : str = 'wav' # Output format
target_db : float = - 3.0 # Target volume
2. Parâmetros de otimização da qualidade do som
# Equalizer settings
equalizer_enabled : bool = True # Enable equalizer
treble_frequency : float = 3000.0 # Treble center (2-8kHz)
mid_frequency : float = 1000.0 # Mid center (250Hz-2kHz)
bass_frequency : float = 100.0 # Bass center (80-250Hz)
3. Parâmetros de redução de ruído
# Noise processing
subsonic_filter_enabled : bool = True # Subsonic filtering
compression_ratio : float = 2.5 # Compression ratio
threshold_db : float = - 15.0 # Noise threshold
Recomendações de otimização de cena
1. Adaptação do tipo de voz
| Tipo de voz | Parâmetros recomendados |
|---|
| Macho | Bass_gain = 2.0, mid_frequency = 1200Hz |
| Fêmea | Treble_gain = 1.5, Bass_gain = 1.5 |
| Criança | mid_gain = 1.5, Bass_gain = 1.0 |
2. Configuração do limitador
| Nível de compressão | Combinação de parâmetros |
|---|
| Compressão leve | limhold_db = -20, razão = 2, ataque = 0,3s |
| Compressão média | limhold_db = -25, razão = 3, ataque = 0,2s |
| Compressão pesada | limhold_db = -30, razão = 4, ataque = 0,1s |
3. Configuração do equalizador
| Objetivo da qualidade do som | Combinação de parâmetros |
|---|
| Aprimoramento da voz | Treble = 2.0, baixo = 1,0 |
| Clareza Boost | Treble = 3,0, baixo = -1,0 |
| Tom quente | Treble = -1,0, baixo = 2.0 |
Precauções de uso
- Proteção de recursos de áudio
- Evite o excesso de processamento, levando à distorção
- Manter a clareza limite do fonema
- Preservar a prosódia de fala natural
- Adaptação do conjunto de dados
- Ajuste os parâmetros com base nas características do alto -falante
- Considere gravar fatores de ambiente
- Manter consistência de processamento
- Controle de qualidade
- Verifique regularmente efeitos de processamento
- Monitore amostras anormais
- Ajuste os parâmetros em tempo hábil
Fluxo de trabalho de prática recomendada
- Execute a análise de áudio primeiro
- Selecione parâmetros com base no relatório de análise
- Efeitos do processo de teste em lotes pequenos
- Ajuste e otimize a configuração de parâmetros
- Executar processamento de normalização em lote
- Verifique a qualidade do resultado do processamento
Através da configuração e do uso adequados dessa ferramenta, você pode melhorar significativamente a qualidade dos dados do TTS Treining, fornecendo melhor suporte de dados da fundação para treinamento de modelos.
Informações de contato
WeChat


