TtsaudionOmmalizer
中文文档
TTSaudionOmalizer ist ein professionelles TTS -Audio -Vorverarbeitungswerkzeug, das umfassende Funktionen für Audioanalysen und Standardisierungsverarbeitungsfunktionen bietet. Dieses Tool zielt darauf ab, die Qualität der TTS -Trainingsdaten zu verbessern und die Konsistenz in Audiofunktionen zu gewährleisten.
Notwendigkeit der TTS -Audio -Standardisierung
I. Verbesserung der Modelltrainingseffekte
1. Optimieren Sie den Lernprozess
- Unified Volumenstufen helfen Modellen, sich auf Lernsprachmerkmale zu konzentrieren, anstatt durch Volumenunterschiede abgelenkt zu werden
- Standardisierte Daten helfen Modellen, schneller zu konvergieren und die Trainingszeit zu verkürzen
- Reduziert das Risiko, dass Modelle falsche Merkmale lernen
2. Schulungsanomalien verhindern
- Vermeiden Sie die Explosion oder das Verschwinden von Gradienten aufgrund großer Volumenunterschiede
- Reduzieren Sie die Möglichkeit einer Überanpassung von Modells auf Volumenfunktionen
- Verbesserung der Stabilität des Trainingsprozesses
3.. Verbesserung der Verallgemeinerungsfähigkeit
- Helfen Sie den Modellen, sich auf das Erlernen von wesentlichen Sprachmerkmalen zu konzentrieren
- Verbesserung der Modellanpassungsfähigkeit in verschiedenen Szenarien
- Reduzieren Sie die Abhängigkeit von nichtkritischen Merkmalen
Ii. Halten Sie die Audioqualität sicher
1. Sprachklarheit
- Optimieren Sie den Frequenzgang und betonen Sie wichtige Sprachfrequenzbänder
- Verbessern Sie die Klarheit der Konsonanten, verbessern Sie die Sprachverständlichkeit
- Behalten Sie die Natürlichkeit der Vokal auf, bewahren Sie die Sprachmerkmale bewahren
2. Rauschkontrolle
- Entfernen Sie Hintergrundgeräusche, verbessern Sie die Sprachreinheit
- Kompress Dynamikbereich, Gleichgewichtsvolumenpegel
- Filtern Sie nutzlose Frequenzbänder, reduzieren Sie Interferenzfaktoren
III. Stellen Sie die Datenkonsistenz sicher
1. Einheitlichkeit der technischen Spezifikation
- Vereinheitlichen Sie die Stichprobenrate, stellen Sie die Datenqualität sicher
- Standardisieren Sie die Kanaleinstellungen, vereinfachen Sie den Verarbeitungsfluss
- Standardisieren Sie das Audioformat, verbessern Sie die Kompatibilität
2. Optimierung der Merkmalextraktion
- Verbesserung der Genauigkeit und Zuverlässigkeit der Merkmalextraktion
- Verbesserung der Vergleichbarkeit zwischen verschiedenen Proben
- Stellen Sie sicher
Empfohlener Standardisierungsprozess:
1. Grundvorverarbeitung
- Formatvereinigung
- Verlegen Sie verschiedene Audioformate (z. B. in WAV)
- Gewährleistung der Formatkompatibilität
- Probenrate Vereinigung
- Standardisierung der Stichprobenrate (z. B. 22050 Hz)
- Datenkonsistenz beibehalten
- Mono -Kanalumwandlung
- Multi-Channel-Audio in Mono konvertieren
- Vereinfachen Sie die nachfolgende Verarbeitung
2. Optimierung von Audioqualität?
- DC -Offset -Entfernung
- Beseitigen Sie den festen Versatz in Audiosignalen
- Audioqualität verbessern
- Volumennormalisierung
- Audiovolumenstufen vereinen
- Stellen Sie die Konsistenz der Lautstärke sicher
- Frequenzgangoptimierung
- Frequenzeigenschaften anpassen
- Optimieren Sie die Audioleistung
3. Rauschverarbeitung?
- Stille Entfernung
- Räumen Sie ungültige Audiosegmente auf
- Datenqualität verbessern
- Geräuschreduzierung
- Hintergrundgeräuschen beseitigen
- Verbesserung der Audioklarheit
- Dynamikbereichskomprimierung
- Audio -Dynamikbereich ausgleichen
- Verbesserung der Gesamtleistung
4. Qualitätsprüfung ✅
- Qualitätsvalidierung
- Überprüfen Sie die verarbeitete Audioqualität
- Stellen Sie sicher, dass die Schulungsanforderungen erfüllt sind
- Feature -Validierung
- Überprüfen Sie die Parameter von Audiofunktionen
- Garantieren effektive Merkmalextraktion
Verarbeitungsflussdiagramm:
Input Audio ➡️ Basic Preprocessing ➡️ Quality Optimization ➡️ Noise Processing ➡️ Quality Check ➡️ Output Audio
Wichtige Anmerkungen:
- Führen Sie die Verarbeitungsprotokolle für jeden Schritt bei
- Führen Sie an wichtigen Stellen Qualitätsprüfungen durch
- Halten Sie Original -Audio -Backups beibehalten
- Passen Sie die Parameter basierend auf bestimmten Anwendungsszenarien an
Hauptfunktionen
1. Audioanalyse
- Generieren Sie einen detaillierten Lautstatistikbericht
- Bieten Sie die Visualisierungsvisualisierung zur Verfügung
- Vorschläge zur Ausgabeparameteroptimierung
from audio_analyzer import AudioAnalyzer
analyzer = AudioAnalyzer ()
results = analyzer . analyze_speaker_directory (
base_dir = "raw_voices" , # Nested folders, i.e., a main folder containing several subfolders (with audio files)
output_dir = "analysis_report" ,
max_workers = 16
)Ergebnisse:
发现 49 个说话人目录
处理说话人: 0%| | 0/49 [00:00<?, ?it/s]
分析说话人: 廉颇
分析音频: 0%| | 0/118 [00:00<?, ?it/s]
分析音频: 25%|██▌ | 30/118 [00:00<00:00, 289.97it/s]
分析音频: 53%|█████▎ | 62/118 [00:00<00:00, 299.46it/s]
分析音频: 78%|███████▊ | 92/118 [00:00<00:00, 298.95it/s]
音频分析报告 说话人: 廉颇:
--------------------------------------------------
分析的音频文件总数: 118
音量统计:
Mean Norm:
mean: 0.053
std: 0.010
min: 0.032
max: 0.082
RMS Amplitude:
mean: 0.089
std: 0.015
min: 0.057
max: 0.131
Max Amplitude:
mean: 0.546
std: 0.123
min: 0.293
max: 0.882
处理说话人: 2%|▏ | 1/49 [00:01<01:03, 1.31s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.053
2. 平衡设置 (确保清晰度): target_db = 0.063
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/廉颇
分析说话人: 小乔
分析音频: 0%| | 0/201 [00:00<?, ?it/s]
分析音频: 14%|█▍ | 28/201 [00:00<00:00, 268.48it/s]
分析音频: 29%|██▉ | 58/201 [00:00<00:00, 283.83it/s]
分析音频: 43%|████▎ | 87/201 [00:00<00:00, 281.59it/s]
分析音频: 60%|█████▉ | 120/201 [00:00<00:00, 297.76it/s]
分析音频: 75%|███████▍ | 150/201 [00:00<00:00, 294.95it/s]
分析音频: 90%|████████▉ | 180/201 [00:00<00:00, 289.50it/s]
音频分析报告 说话人: 小乔:
--------------------------------------------------
分析的音频文件总数: 201
音量统计:
Mean Norm:
mean: 0.052
std: 0.019
min: 0.012
max: 0.135
RMS Amplitude:
mean: 0.086
std: 0.030
min: 0.024
max: 0.209
Max Amplitude:
mean: 0.495
std: 0.143
min: 0.163
max: 0.943
处理说话人: 4%|▍ | 2/49 [00:02<01:09, 1.49s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.052
2. 平衡设置 (确保清晰度): target_db = 0.071
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/小乔
分析说话人: 赵云
分析音频: 0%| | 0/142 [00:00<?, ?it/s]
分析音频: 20%|█▉ | 28/142 [00:00<00:00, 270.67it/s]
分析音频: 42%|████▏ | 60/142 [00:00<00:00, 294.19it/s]
分析音频: 63%|██████▎ | 90/142 [00:00<00:00, 291.33it/s]
分析音频: 85%|████████▍ | 120/142 [00:00<00:00, 283.42it/s]
音频分析报告 说话人: 赵云:
--------------------------------------------------
分析的音频文件总数: 142
音量统计:
Mean Norm:
mean: 0.050
std: 0.019
min: 0.018
max: 0.124
RMS Amplitude:
mean: 0.089
std: 0.031
min: 0.039
max: 0.193
Max Amplitude:
mean: 0.603
std: 0.182
min: 0.339
max: 1.000
处理说话人: 6%|▌ | 3/49 [00:04<01:06, 1.45s/it]
推荐的target_db值:
1. 保守设置 (保持动态范围): target_db = 0.050
2. 平衡设置 (确保清晰度): target_db = 0.070
3. 安全设置: target_db = -3.000
分析结果已保存到: raw_voices/音频分析报告/赵云
...
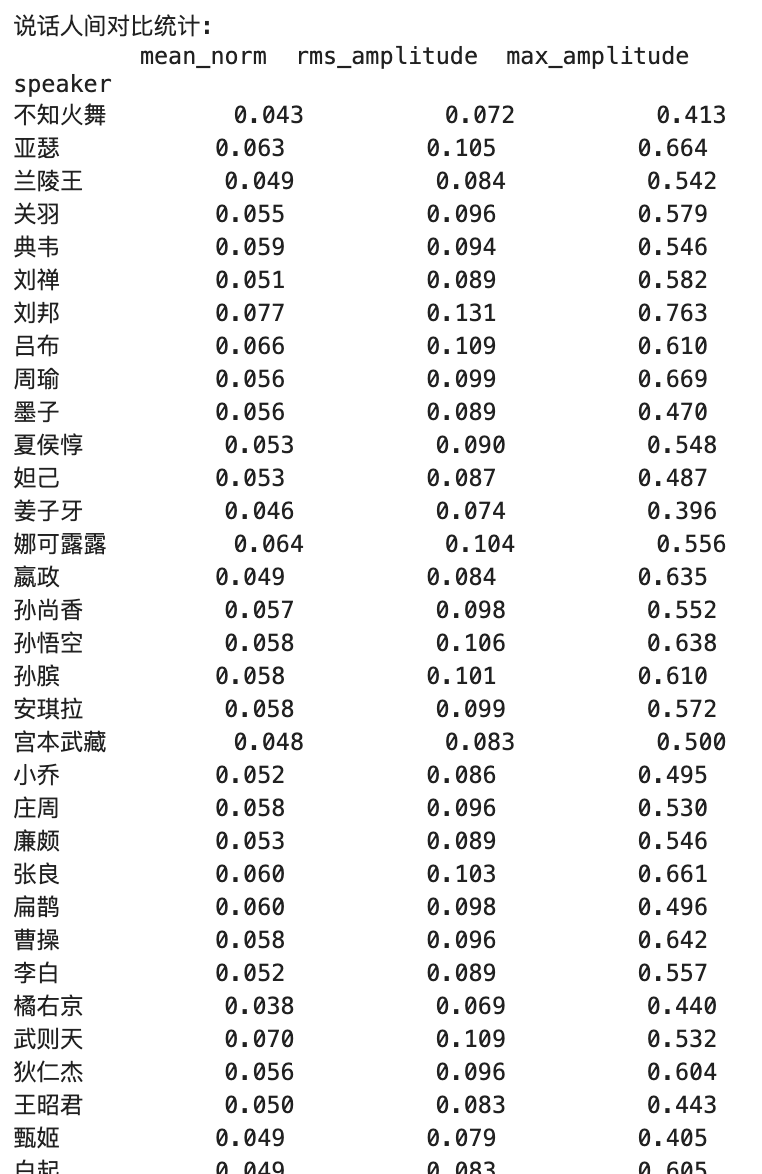
Schlüsselkennzahlen Erläuterung :
1. Norm
- Praktische Bedeutung :
- Spiegelt die allgemeine Lautstärke des Audios wider
- Repräsentiert die durchschnittliche absolute Amplitude des Audiosignals
- Wertebereich typischerweise zwischen 0-1
- Wertbedeutung :
- Höherer Wert = lauter Gesamtwahrnehmung
- Niedrigerer Wert = weichere Gesamtwahrnehmung
- Idealer Bereich typischerweise zwischen 0,1-0,3
- Anwendungsszenarien :
- Wird verwendet, um zu bewerten, ob die allgemeine Lautstärke angemessen ist
- Hilft zu bestimmen, ob Volumenverstärkung erforderlich ist
2. RMS -Amplitude
- Praktische Bedeutung :
- Spiegelt das effektive Energieniveau des Audios wider
- Näher an die Wahrnehmung der Lautstärke durch das menschliche Ohr
- Berücksichtigt die Energieverteilung im Laufe der Zeit
- Wertbedeutung :
- Höherer Wert = stärkere Audioenergie
- Niedrigerer Wert = schwächere Audioenergie
- Professionelles Audio wird normalerweise zwischen 0,1 und 0,4 empfohlen
- Anwendungsszenarien :
- Bewerten Sie den Audio -Dynamikbereich
- Stellen Sie fest, ob Audio Komprimierung oder Expansion benötigt
- Häufig bei der Audio -Normalisierung verwendet
3. Maxamplitude
- Praktische Bedeutung :
- Reflektiert die Spitzenwerte bei Audio
- Repräsentiert den maximalen momentanen Wert des Signals
- Wird verwendet, um festzustellen, ob das Ausschneiden existiert
- Wertbedeutung :
- 1.0 = maximal möglicher Wert für digitales Audio (potenzielles Ausschneiden)
- Empfohlene Spitzenkontrolle unter 0,9
- Zu niedrig (z. B. <0,5) zeigt an, dass Audio möglicherweise zu weich ist
- Anwendungsszenarien :
- Audioverzerrung erkennen
- Bewerten Sie die Audio -Headroom
- Leitfadenlimitereinstellungen
Beziehung zwischen den drei
Hierarchische Beziehung :
- Maxamplitude> RMS -Amplitude> mittlere Norm
- Dies liegt an ihren unterschiedlichen Berechnungsmethoden
Praktische Anwendung :
- Mittlere Norm: Wird für die Gesamtvolumenbewertung verwendet
- RMS: Wird für die Energieniveauskontrolle verwendet
- Maxamplitude: Wird zur Spitzenkontrolle verwendet
Referenz ideale Werte
- Referenzwerte der professionellen Audioproduktion :
- Mittlere Norm: 0,1-0,3
- RMS: 0.1-0.4
- Maxamplitude: 0,8-0,9
Nutzungsempfehlungen
- Überprüfen Sie zunächst die maximale Amplitude, um das Ausschneiden zu vermeiden
- Verwenden Sie RMS, um sicherzustellen, dass die Gesamtenergie angemessen ist
- Referenzmittelnorm, um das Gesamtvolumen anzupassen
- Betrachten Sie alle drei Indikatoren im Kontext einer bestimmten Anwendung
Diese Indikatoren arbeiten zusammen, um uns zu helfen:
- Halten Sie die Audioqualität sicher
- Volumenkonsistenz beibehalten
- Vermeiden Sie Verzerrungen und Lärm
- Optimieren Sie das Hörerlebnis
2. Audionormalisierung
Schlüsselmerkmale dieser Lösung:
- Verwendet den Normwirkung von SOX für die Audionormalisierung
- Kann einzelne Dateien verarbeiten oder Batch verarbeiten ganze Verzeichnisse
- Standardmäßig zum Normalisieren von Volumen auf -3 dB, bei Bedarf einstellbar
- Behält die ursprüngliche Audioqualität bei, passt nur das Volumen an
Die Verwendung ist einfach:
- Für eine einzelne Datei: Rufen Sie direkt Normalize_audio () auf
- Für das gesamte Verzeichnis: Verwenden Sie batch_normalize_directory () Funktion Die verarbeiteten Audio -Dateien sollten einheitlichere Volumenstufen aufweisen und das Problem der inkonsistenten Lautstärke lösen. Wenn sich das Gesamtvolumen immer noch zu niedrig oder hoch anfühlt, passen Sie den Parameter target_db an.
from tts_audio_normalizer import AudioProcessingParams , TTSAudioNormalizer
# Create parameter object and customize parameters
params = AudioProcessingParams ()
params . noise_reduction_strength = 0.8 # Increase noise reduction intensity
params . target_db = - 3 # Set target volume
# Process single file
#normalizer.normalize_audio("input.wav", "output.wav", params)
# Batch process directory
normalizer . batch_normalize_directory (
input_dir = "./audio_segments" ,
output_dir = "./audio_segments_normalized" ,
params = params ,
max_workers = 4
)Parameterkonfigurationshandbuch
1. Grundparameter
# Basic format settings
rate : int = 44100 # Sample rate
channels : int = 1 # Number of channels
output_format : str = 'wav' # Output format
target_db : float = - 3.0 # Target volume
2. Optimierungsparameter für Klangqualität
# Equalizer settings
equalizer_enabled : bool = True # Enable equalizer
treble_frequency : float = 3000.0 # Treble center (2-8kHz)
mid_frequency : float = 1000.0 # Mid center (250Hz-2kHz)
bass_frequency : float = 100.0 # Bass center (80-250Hz)
3.. Parameter zur Rauschreduktion
# Noise processing
subsonic_filter_enabled : bool = True # Subsonic filtering
compression_ratio : float = 2.5 # Compression ratio
threshold_db : float = - 15.0 # Noise threshold
Empfehlungen zur Szenenoptimierung
1. Anpassung des Sprachtyps
| Sprachtyp | Empfohlene Parameter |
|---|
| Männlich | Bass_gain = 2.0, Mid_Frequency = 1200Hz |
| Weiblich | teble_gain = 1,5, bass_gain = 1,5 |
| Kind | Mid_gain = 1,5, Bass_gain = 1.0 |
2. Konfiguration der Begrenzer
| Kompressionsniveau | Parameterkombination |
|---|
| Leichte Kompression | Threshold_db = -20, Verhältnis = 2, Angriff = 0,3s |
| Mittlere Komprimierung | Threshold_db = -25, Verhältnis = 3, Angriff = 0,2s |
| Schwere Kompression | Threshold_db = -30, Verhältnis = 4, Angriff = 0,1s |
3. Equalizer -Konfiguration
| Klangqualitätsziel | Parameterkombination |
|---|
| Sprachverbesserung | Treble = 2,0, Bass = 1,0 |
| Klarheitschub | Treble = 3,0, Bass = -1,0 |
| Warmer Ton | TREBLE = -1.0, Bass = 2,0 |
Nutzungsvorkehrungen
- Audio -Funktionsschutz
- Vermeiden Sie eine Überbearbeitung, die zu Verzerrungen führt
- Phonem Grenzklarheit beibehalten
- Natürliche Sprachprosodie bewahren
- Datensatzanpassung
- Passen Sie die Parameter basierend auf den Lautsprechermerkmalen an
- Betrachten Sie die Aufzeichnungsfaktoren auf den Aufzeichnungsfaktoren
- Verarbeitungskonsistenz beibehalten
- Qualitätskontrolle
- Überprüfen Sie regelmäßig Verarbeitungseffekte
- Überwachen Sie abnormale Proben
- Passen Sie die Parameter rechtzeitig an
Best Practice Workflow
- Führen Sie zuerst Audioanalyse durch
- Wählen Sie Parameter basierend auf dem Analysebericht
- Testprozessffekte auf kleine Charge
- Passen Sie die Parameterkonfiguration an und optimieren Sie
- Führen Sie die Verarbeitung der Stapel -Normalisierungsverarbeitung aus
- Überprüfen Sie die Qualität des Verarbeitungsergebnisses
Durch die ordnungsgemäße Konfiguration und Verwendung dieses Tools können Sie die Qualität der TTS -Schulungsdaten erheblich verbessern und eine bessere Fundamentdatenunterstützung für das Modelltraining bieten.
Kontaktinformationen
Wechat


