Stepwise_Monotonic_Multihead_Attention
1.0.0
การใช้ Pytorch ของความสนใจแบบหลายหัวแบบ monotonic (SMA) คล้ายกับการเพิ่มความรู้สึกโมโนโท
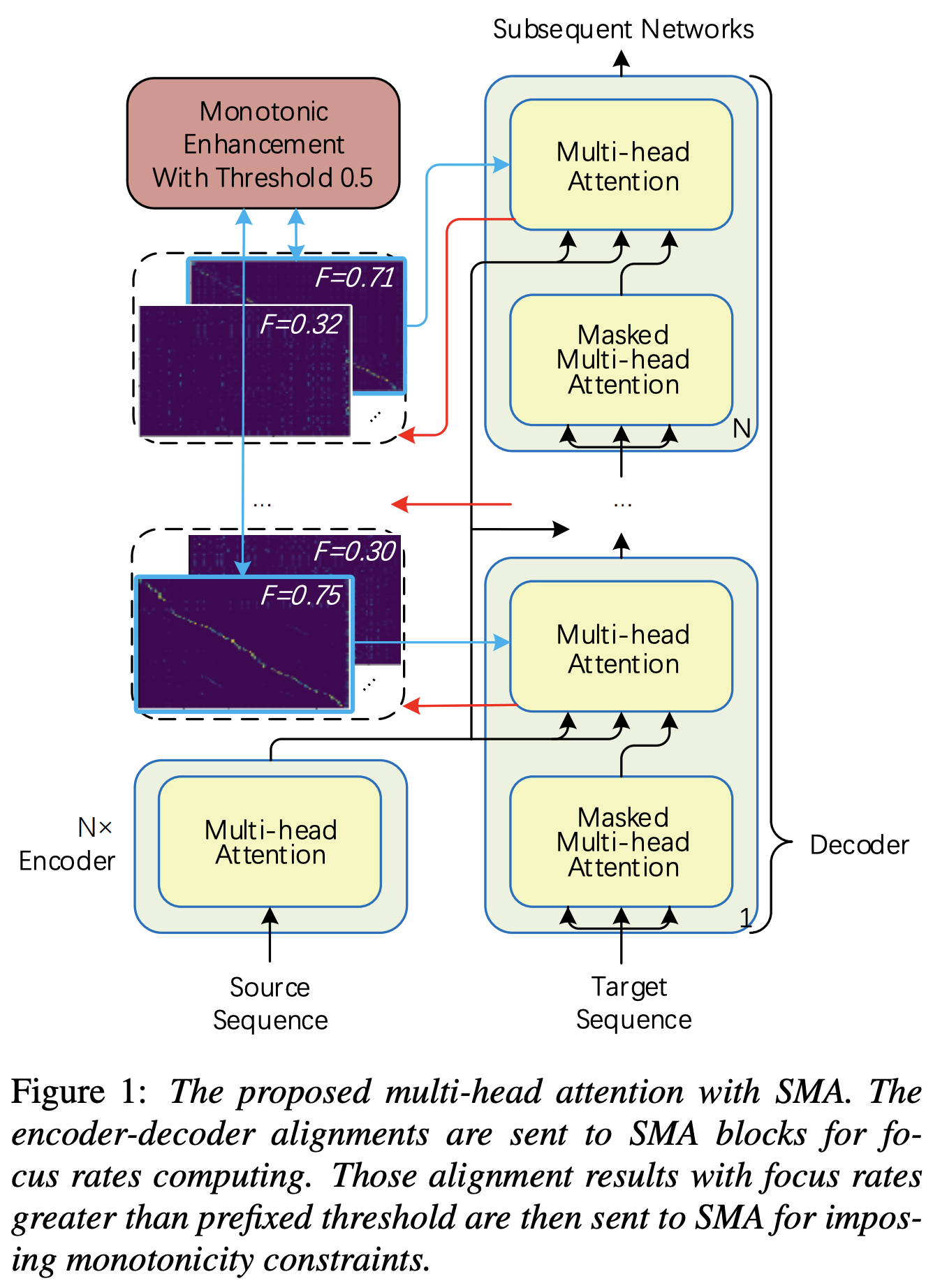
คุณสามารถใช้ SMA เพื่อจับคู่ mel-spectrogram กับข้อความในความยาวของลำดับ ด้านล่างนี้เป็นผลลัพธ์บางอย่างที่แสดงประสิทธิภาพของ SMA รูปแรกคือการจัดตำแหน่งที่ไม่มี SMA ( hp.sma_tunable=False ) ที่ขั้นตอน 115K รูปที่สองคือรูปที่มี SMA tunning ( hp.sma_tunable=True ) ที่ขั้นตอน 125k
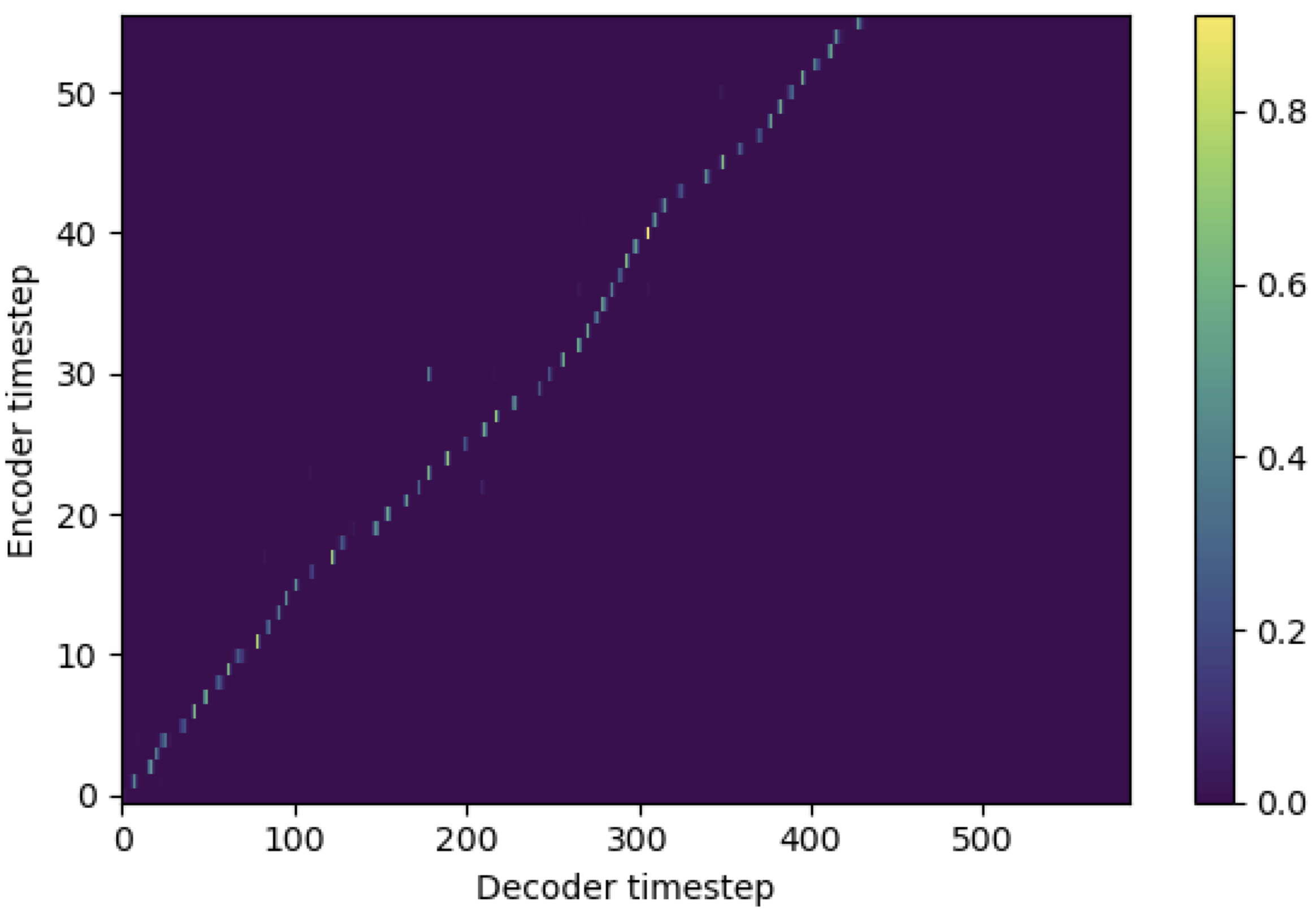
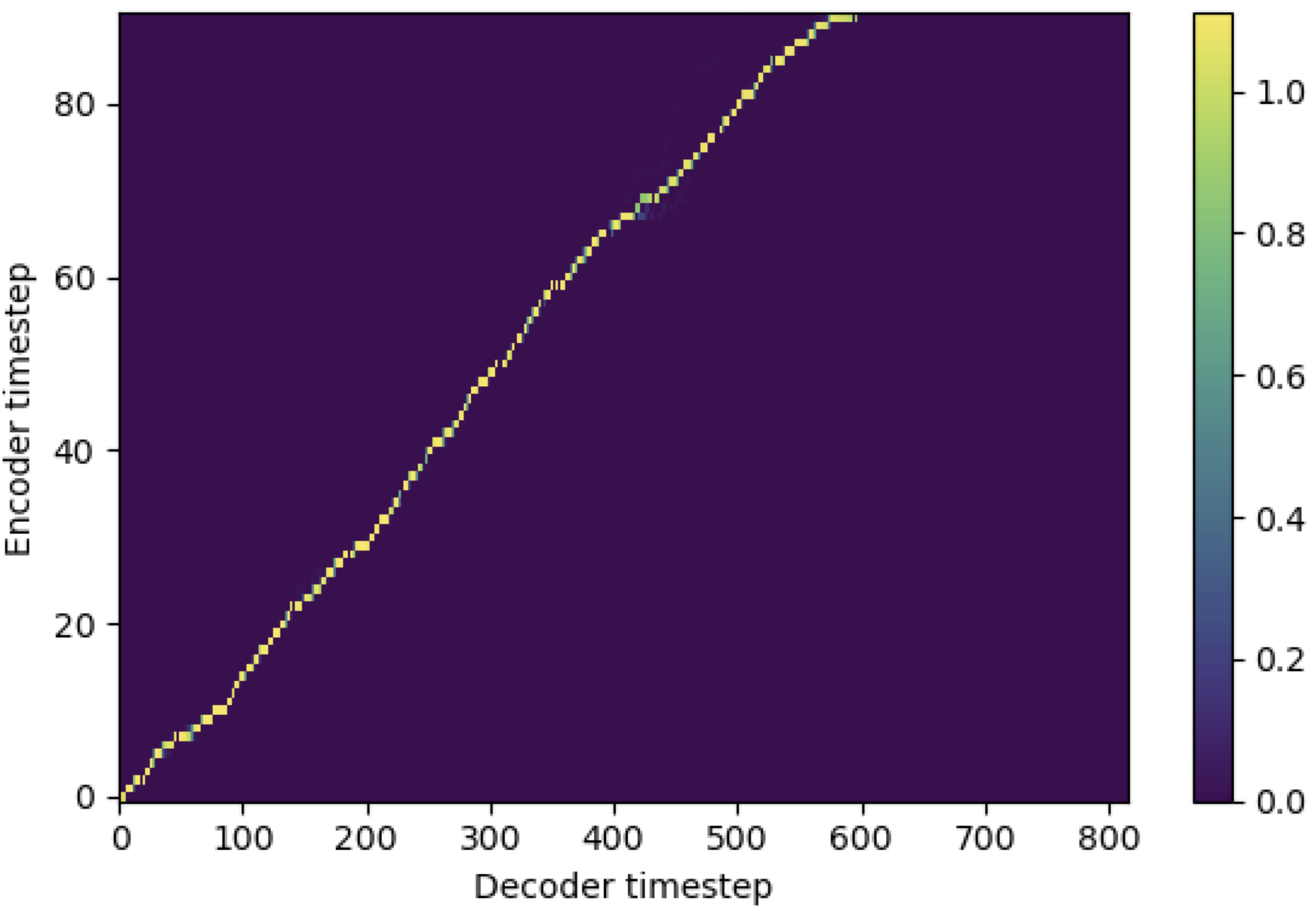
อย่างที่คุณเห็นฉันสามารถยืนยันได้ว่าการจัดตำแหน่งนั้นแข็งแกร่งกว่าความสนใจแบบหลายเฮดปกติหลังจากใช้การปรับแต่ง SMA
ก่อนอื่นกำหนด SMA สมมติว่าเรามีการเข้ารหัส 256 มิติและความสนใจ 4-multihead
from sma import StepwiseMonotonicMultiheadAttention
ref_attention = StepwiseMonotonicMultiheadAttention ( 256 , 256 // 4 , 256 // 4 ) จากนั้นคุณสามารถใช้ความสนใจและได้รับการจัดตำแหน่งดังนี้ mel_len เป็นขนาดเฟรมของเสียงอ้างอิงและ seq_len คือความยาวของข้อความอินพุต (ซึ่งมักจะเป็นลำดับของหน่วยเสียง) fr_max เป็นค่าสูงสุดของอัตราการโฟกัสจากฟังก์ชั่น focused_head() ทั้ง text_mask และ attn_mask มี 1. สำหรับค่าที่จะถูกปิดบังและ 0. เพื่อให้ผู้อื่นถูกเก็บไว้
"""
enc_out --- [batch, seq_len, 256]
attn --- [batch, seq_len, mel_len]
enc_text --- [batch, seq_len, 256]
enc_audio --- [batch, mel_len, 256]
text_mask --- [batch, seq_len, 1]
attn_mask --- [batch, seq_len, mel_len]
"""
# Attention
enc_out , attn , fr_max = ref_attention ( enc_text , enc_audio , enc_audio ,
mel_len , mask = attn_mask , query_mask = text_mask ) อย่างที่คุณเห็น SMA จะส่งคืน Fusion Text-Audio ในขนาดข้อความ ( seq_len ) โดยไม่คำนึงถึงขนาดเสียง ( mel_len )
hp.sma_tunable เป็นไฮเปอร์พารามิเตอร์ที่สามารถสลับรูปแบบการปรับแต่งของความสนใจแบบหลายหัวแบบแบบโมโนโทนิก หากตั้งค่า True ความสนใจแบบหลายเฮดแบบโมโนโทนิกจะถูกเปิดใช้งาน มิฉะนั้นมันเป็นความสนใจแบบหลายหัวแบบปกติเช่นเดียวกับในหม้อแปลง เช่นเดียวกับในการเพิ่มความน่าเบื่อหน่ายสำหรับ TRANSOURTION AUTOREGRESSISTICRESS TURNATER TWS (เราจะเรียกว่าบทความนี้เป็น 'เอกสารอ้างอิง' ในเอกสารต่อไปนี้) ตัวอย่างเช่นคุณอาจฝึกอบรมโมดูลโดยไม่ต้องใช้ sma_tunable=True สำหรับขั้นตอนบางอย่างเพื่อการฝึกอบรมที่เร็วขึ้นexpectation() คือการคำนวณคะแนนความคาดหวังแบบโมโนโทนิกแบบขั้นตอนซึ่งแสดงว่าเป็น alpha ในกระดาษอ้างอิงencoder ในเฟรมเวิร์ก TTS ทั่วไป) และคีย์และค่ามาจากการเข้ารหัส mel-spectrogram (เอาต์พุตของ reference encoder ในเฟรมการเข้ารหัส mel-spectrogram ทั่วไปเช่น เป็นผลให้โมดูล SMA ปัจจุบันแปลงการเข้ารหัส mel-spectrogram จากความยาวของ mel-spectrogram เป็นความยาวของข้อความ คุณต้องปรับเปลี่ยนมิติ (โดยเฉพาะอย่างยิ่งในฟังก์ชั่น expectation ) ของการสืบค้นคีย์และค่าขึ้นอยู่กับงานfocused_head จะเลือกการจัดตำแหน่งแนวทแยงมุมที่ดีที่สุด (เพิ่มขึ้น monotonically) ระหว่างหัว มันเป็นไปตาม 'อัตราการโฟกัส' ในกรอบ FastSpeech เช่นเดียวกับในกระดาษอ้างอิง แตกต่างจากกระดาษอ้างอิงหัวที่ได้รับการจัดอันดับสูงสุดจะถูกเลือกแทนที่จะเป็นเกณฑ์ อย่างไรก็ตามคุณสามารถนำมาใช้โดยเพียงเพิ่ม prefixed_threshold (เช่น 0.5 ) ลงในฟังก์ชัน focused_head @misc{lee2021sma,
author = {Lee, Keon},
title = {Stepwise_Monotonic_Multihead_Attention},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Stepwise_Monotonic_Multihead_Attention}}
}


