Stepwise_Monotonic_Multihead_Attention
1.0.0
Implementación de Pytorch de la atención de múltiples cabezas monotónicas (SMA) de paso, similar a mejorar la monotonicidad para el transformador autorregresivo robusto TTS
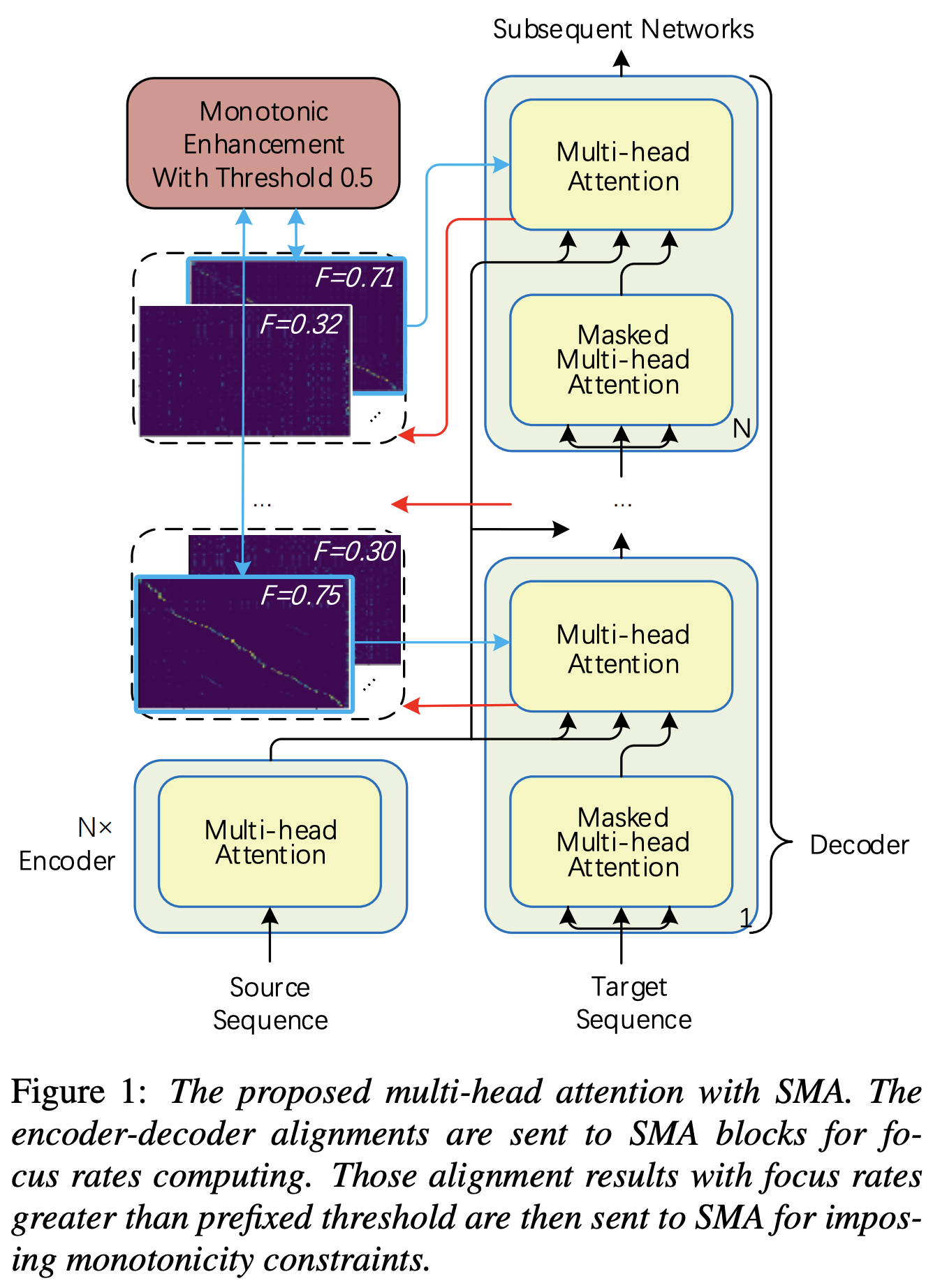
Puede aplicar SMA para que coincida con el espectrograma MEL al texto en la longitud de las secuencias. A continuación se presentan algunos resultados que muestran la efectividad de la SMA. La primera figura es la alineación sin SMA ( hp.sma_tunable=False ) en 115k pasos. La segunda cifra es la que tiene ANTMING SMA ( hp.sma_tunable=True ) en 125k pasos.
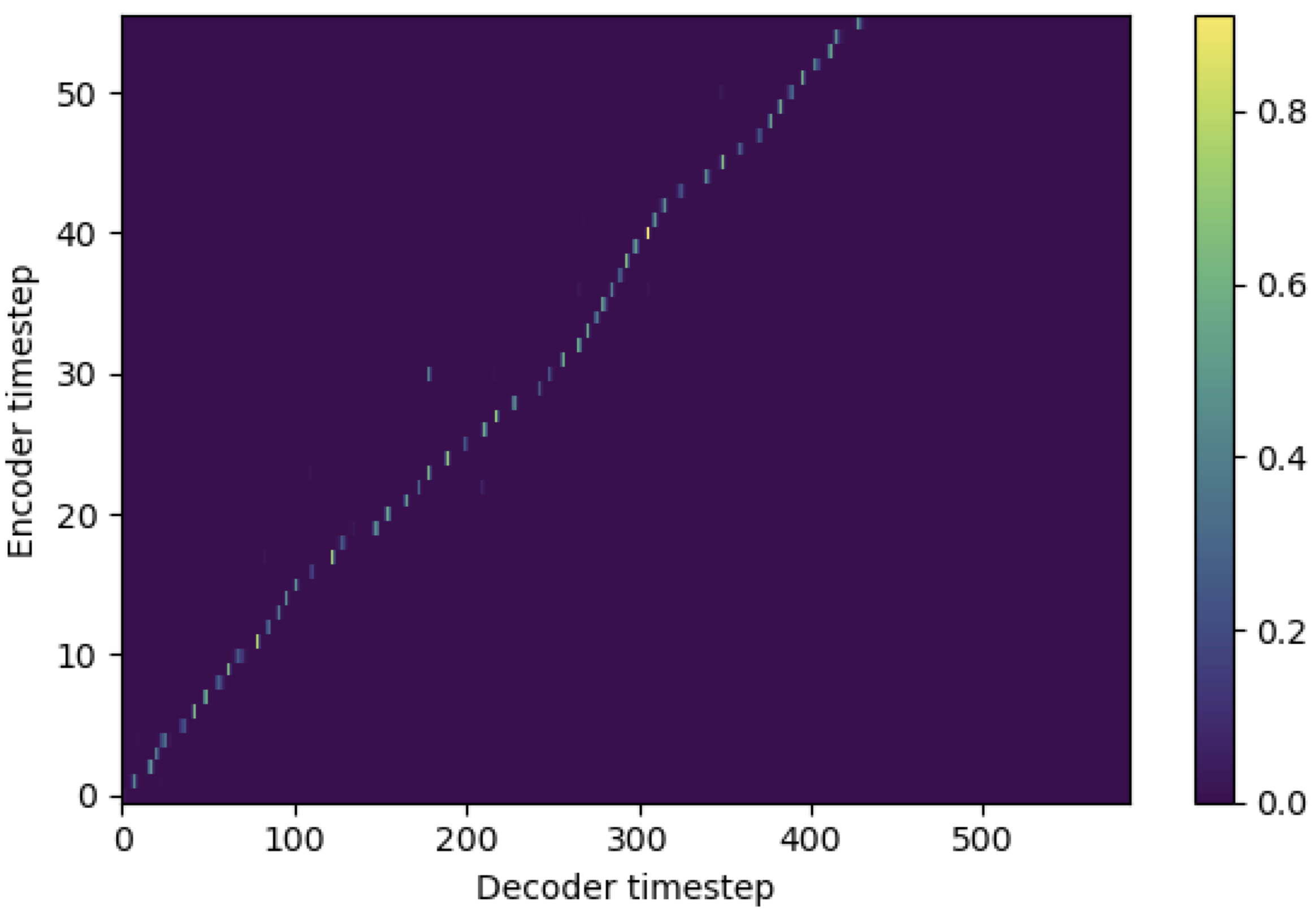
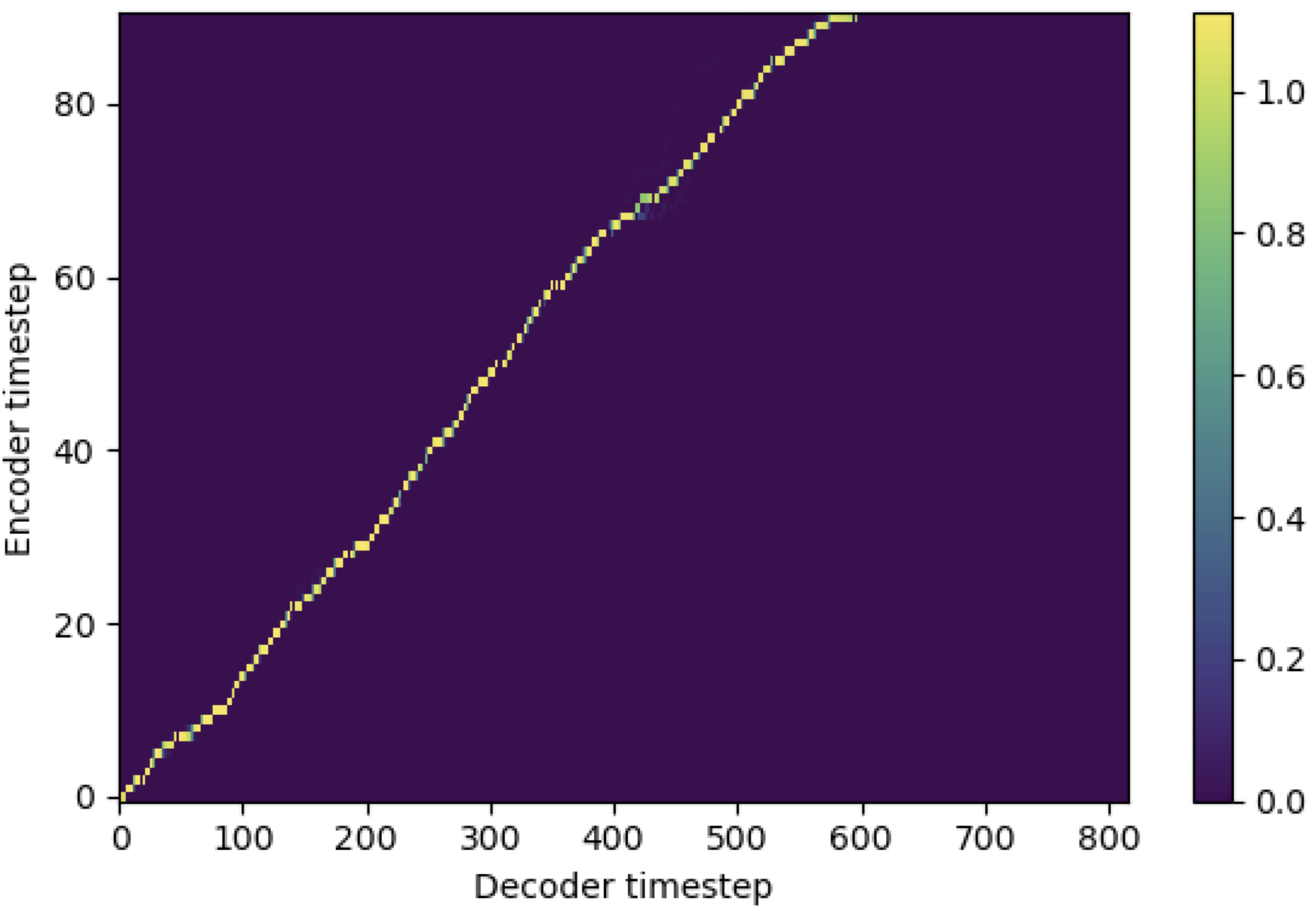
Como puede ver, puedo confirmar que la alineación es altamente más fuerte que la atención múltiple normal después de aplicar el sintonización de SMA.
Primero, defina la SMA. Digamos que tenemos una codificación dimensional y una atención de 4-Multihead.
from sma import StepwiseMonotonicMultiheadAttention
ref_attention = StepwiseMonotonicMultiheadAttention ( 256 , 256 // 4 , 256 // 4 ) Y luego, puede aplicar atención y obtener una alineación de la siguiente manera. mel_len es el tamaño de cuadro de audio de referencia, y seq_len es la longitud del texto de entrada (que generalmente es una secuencia de fonemas). fr_max es un valor máximo de la tasa de enfoque de la función focused_head() . Tanto text_mask como attn_mask tienen 1. Para valores que se enmascararán y 0. Para que otros se mantengan.
"""
enc_out --- [batch, seq_len, 256]
attn --- [batch, seq_len, mel_len]
enc_text --- [batch, seq_len, 256]
enc_audio --- [batch, mel_len, 256]
text_mask --- [batch, seq_len, 1]
attn_mask --- [batch, seq_len, mel_len]
"""
# Attention
enc_out , attn , fr_max = ref_attention ( enc_text , enc_audio , enc_audio ,
mel_len , mask = attn_mask , query_mask = text_mask ) Como puede ver, SMA devuelve la fusión de texto de texto en tamaño de texto ( seq_len ), independientemente del tamaño de audio ( mel_len ).
hp.sma_tunable es el hiperparámetro que puede alternar el esquema de sintonización de atención múltiple monótona a paso. Si se establece True , se activa la atención de múltiples cabezas múltiples paso a paso. De lo contrario, es una atención múltiple normal, al igual que en Transformer. Al igual que en la mejora de la monotonicidad para TTS de transformadores autorregresivos robustos (llamaremos a este documento como 'documento de referencia' en los siguientes documentos), por ejemplo, puede capacitar al módulo sin SMA para ciertos pasos a la capacitación más rápida y converger el modelo, y luego activar SMA mediante la configuración de sma_tunable=True para hacer una alineación monotónica fuerte en pocos pasos.expectation() es la fucntion que calcula el puntaje de expectativa monotónica paso a paso que se denota como alpha en el documento de referencia.encoder en el marco TTS general) y la clave y el valor son de la codificación del espectrograma MEL (salida del reference encoder en el marco de codificación general del espectrograma MEL, por ejemplo, codificador de referencia en el esquema GST). Como resultado, el módulo SMA de corriente convierte el espectrograma MEL que codifica desde la longitud del espectrograma MEL a la longitud del texto. Debe modificar cuidadosamente la dimensión (especialmente en la función de expectation ) de consulta, clave y valor dependiendo de la tarea.focused_head seleccionará la mejor alineación diagonal (aumentando monotónicamente) entre las cabezas. Sigue la 'tasa de enfoque' en el marco de FastSpeech como en el documento de referencia. A diferencia del documento de referencia, el cabezal calificado de enfoque máximo se selecciona en lugar de por umbral. Sin embargo, puede adoptarlo simplemente agregando prefixed_threshold (por ejemplo, 0.5 ) a la función focused_head . @misc{lee2021sma,
author = {Lee, Keon},
title = {Stepwise_Monotonic_Multihead_Attention},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Stepwise_Monotonic_Multihead_Attention}}
}


