Stepwise_Monotonic_Multihead_Attention
1.0.0
Pytorch -Implementierung der schrittweisen monotonischen Multihead -Aufmerksamkeit (SMA) ähnlich der Verbesserung der Monotonizität für robuste autoregressive Transformator -TTs
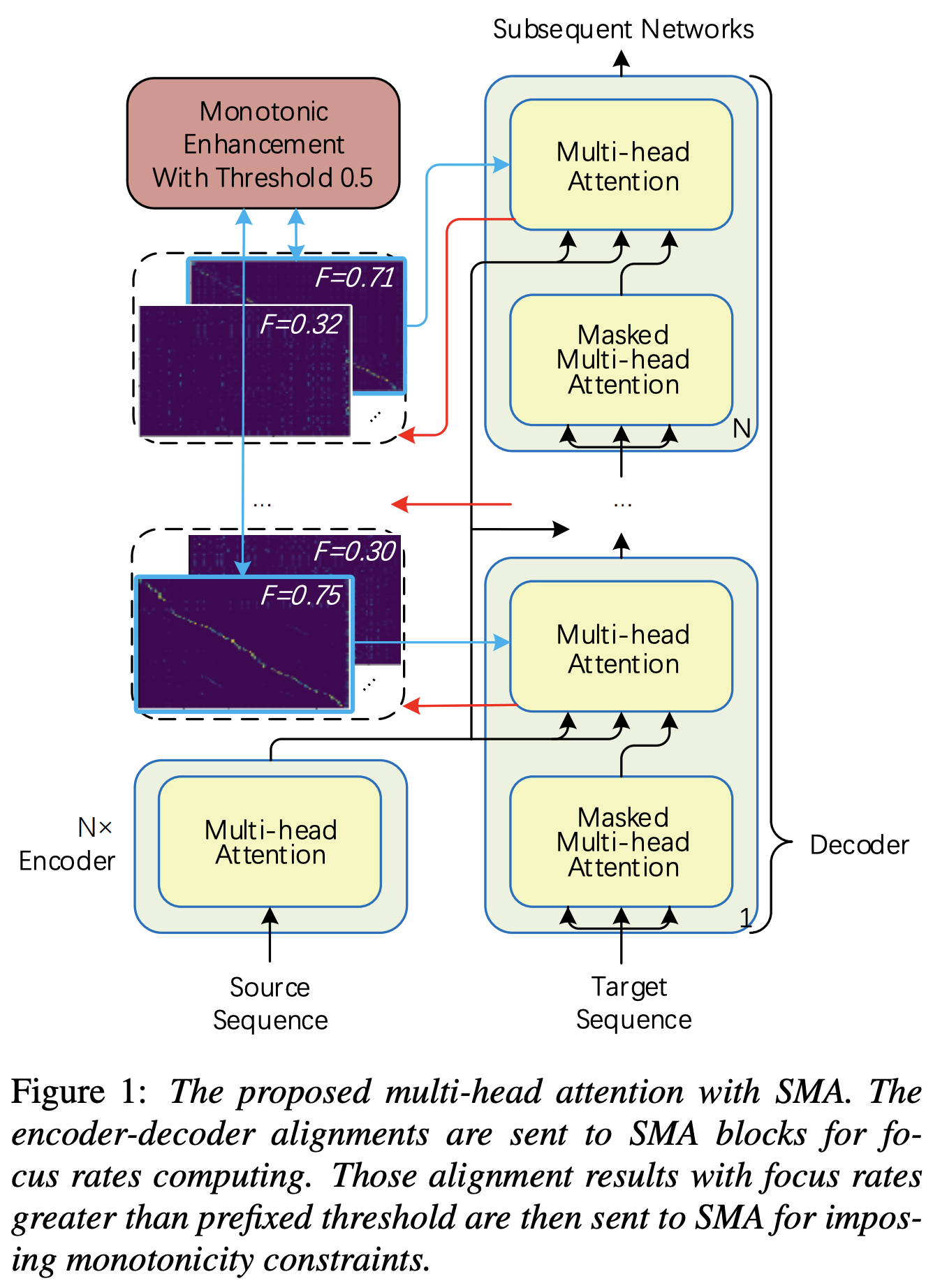
Sie können SMA anwenden, um das melspektrogramm mit dem Text in der Länge der Sequenzen anzupassen. Im Folgenden finden Sie einige Ergebnisse, die die Wirksamkeit von SMA zeigen. Die erste Abbildung ist die Ausrichtung ohne SMA ( hp.sma_tunable=False ) bei 115K -Schritten. Die zweite Abbildung ist die mit SMA Tunning ( hp.sma_tunable=True ) bei 125K -Schritten.
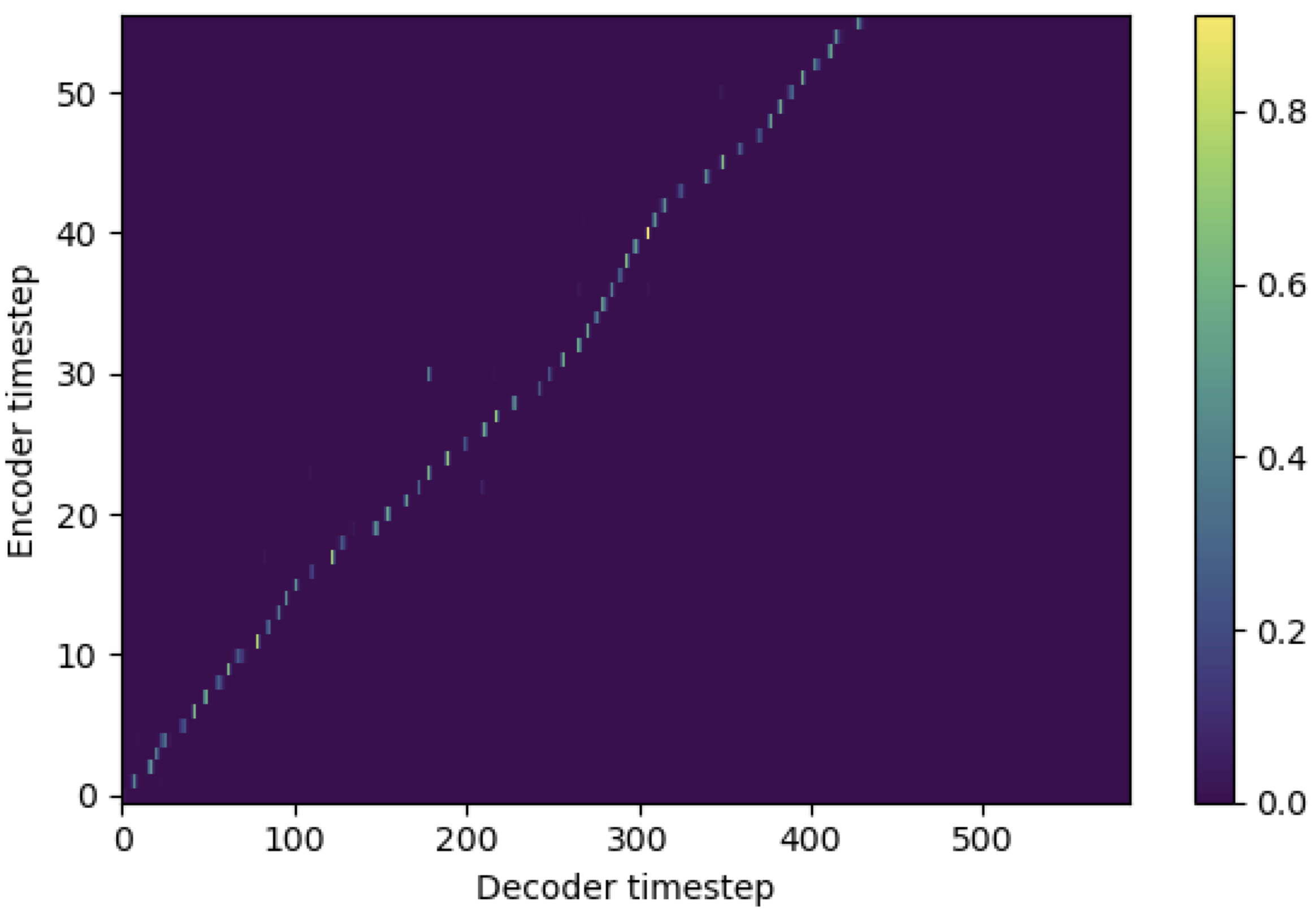
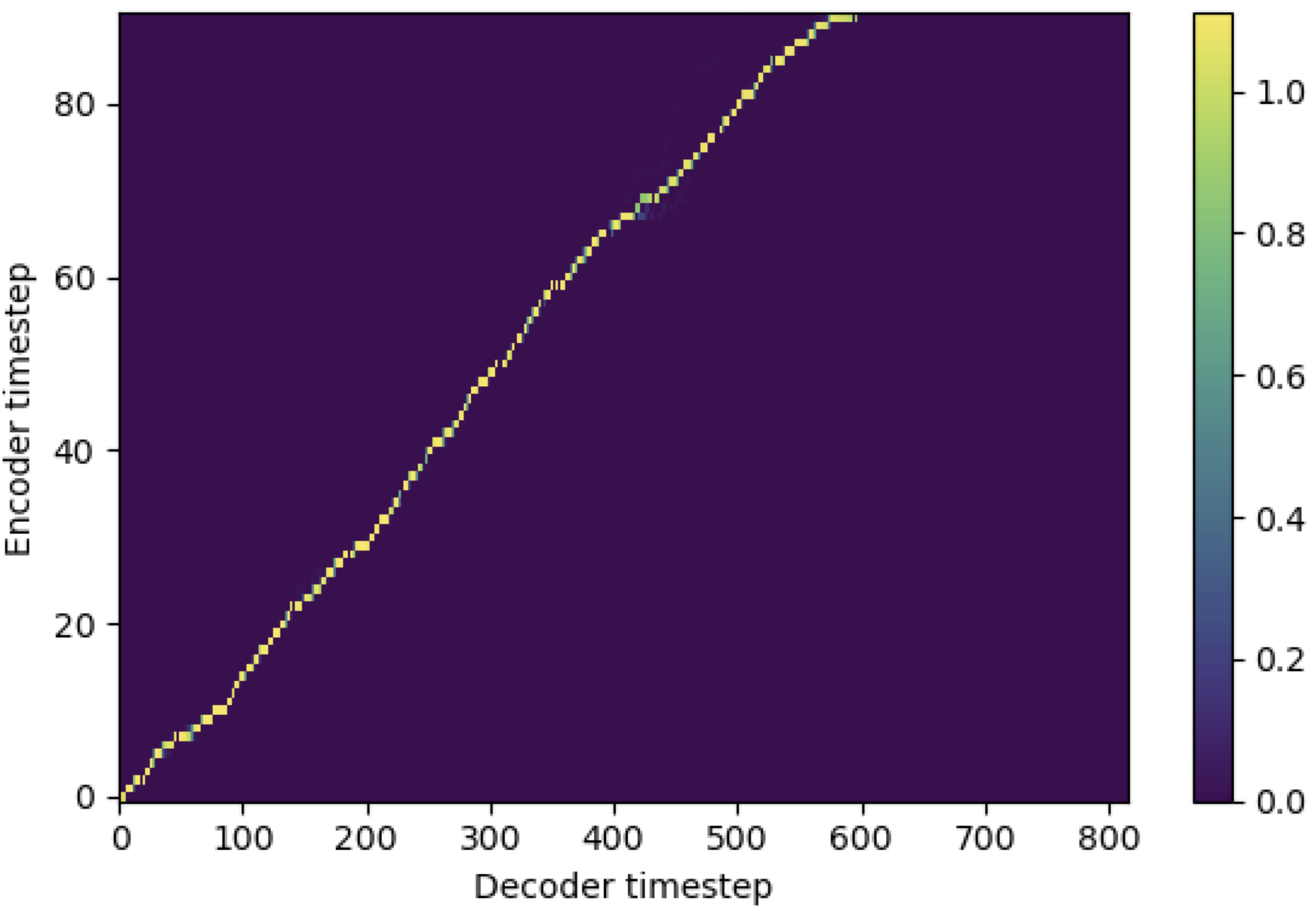
Wie Sie sehen können, kann ich bestätigen, dass die Ausrichtung nach der Anwendung von SMA Tunning sehr stärker ist als die normale Aufmerksamkeit von Multiheads.
Definieren Sie zuerst die SMA. Nehmen wir an, wir haben 256 dimensionale Codierung und 4-Multihead-Aufmerksamkeit.
from sma import StepwiseMonotonicMultiheadAttention
ref_attention = StepwiseMonotonicMultiheadAttention ( 256 , 256 // 4 , 256 // 4 ) Und dann können Sie die Aufmerksamkeit auf sich auftragen und eine Ausrichtung wie folgt erhalten. mel_len ist die Rahmengröße des Referenz -Audios, und seq_len ist die Länge des Eingabetxtes (die normalerweise eine Abfolge von Phonemen ist). fr_max ist ein maximaler Wert der Fokusrate aus der Funktion focused_head() . Sowohl text_mask als auch attn_mask haben 1. Für Werte, die maskiert werden, und 0. damit andere aufbewahrt werden.
"""
enc_out --- [batch, seq_len, 256]
attn --- [batch, seq_len, mel_len]
enc_text --- [batch, seq_len, 256]
enc_audio --- [batch, mel_len, 256]
text_mask --- [batch, seq_len, 1]
attn_mask --- [batch, seq_len, mel_len]
"""
# Attention
enc_out , attn , fr_max = ref_attention ( enc_text , enc_audio , enc_audio ,
mel_len , mask = attn_mask , query_mask = text_mask ) Wie Sie sehen können, gibt SMA die Text-Audio-Fusion in Textgröße ( seq_len ) unabhängig von der Audiogröße ( mel_len ) zurück.
hp.sma_tunable ist der Hyperparameter, der das maßgebliche Schema der schrittweisen monotonischen Multihead -Aufmerksamkeit umschalten kann. Wenn True , wird die schrittweise monotonische Multi -Kopf -Aufmerksamkeit aktiviert. Andernfalls ist es eine normale Aufmerksamkeit mit mehreren Köpfen, genau wie im Transformator. Wie bei der Verbesserung der Monotonizität für robuste autoregressive Transformator -TTs (wir werden dieses Papier in den folgenden Dokumenten als "Referenzpapier" bezeichnen) können Sie beispielsweise das Modul ohne SMA für bestimmte Schritte zum schnelleren Training und Modell konvergieren, und aktivieren Sie SMA, indem Sie sma_tunable=True um eine starke monotonische Ausrichtung in wenigen Schritten festzulegen.expectation() ist der fuktulierende schrittweise monotonische Erwartungswert, der als alpha im Referenzpapier bezeichnet wird.encoder im allgemeinen TTS-Framework) und der Schlüssel und der Wert stammen aus der Melspektrogramm-Codierung (Ausgabe des reference encoder im allgemeinen Melspektrogramm-Codierungsrahmen, z. B. Referenzcodierer im GST-Schema). Infolgedessen konvertiert das Strom-SMA-Modul die Melspektogramm, die von der Länge des Melspektrogramms in die Textlänge kodiert. Sie müssen die Dimension (insbesondere in der expectation ) von Abfrage, Schlüssel und Wert in Abhängigkeit von der Aufgabe sorgfältig ändern.focused_head -Funktion die beste diagonale (monotonisch zunehmende) Ausrichtung zwischen den Köpfen aus. Es folgt der "Fokusrate" im Fastspeech -Framework wie im Referenzpapier. Anders als beim Referenzpapier wird der maximale Kopf der Fokus bewertet und nicht durch Schwellenwert ausgewählt. Sie können es jedoch übernehmen, indem 0.5 einfach prefixed_threshold focused_head . @misc{lee2021sma,
author = {Lee, Keon},
title = {Stepwise_Monotonic_Multihead_Attention},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Stepwise_Monotonic_Multihead_Attention}}
}


