Stepwise_Monotonic_Multihead_Attention
1.0.0
Implementação de Pytorch de atenção multi -cabeça monotônica e passo a passo semelhante ao aprimoramento da monotonicidade para transformadores autoregressivos robustos TTS TTS
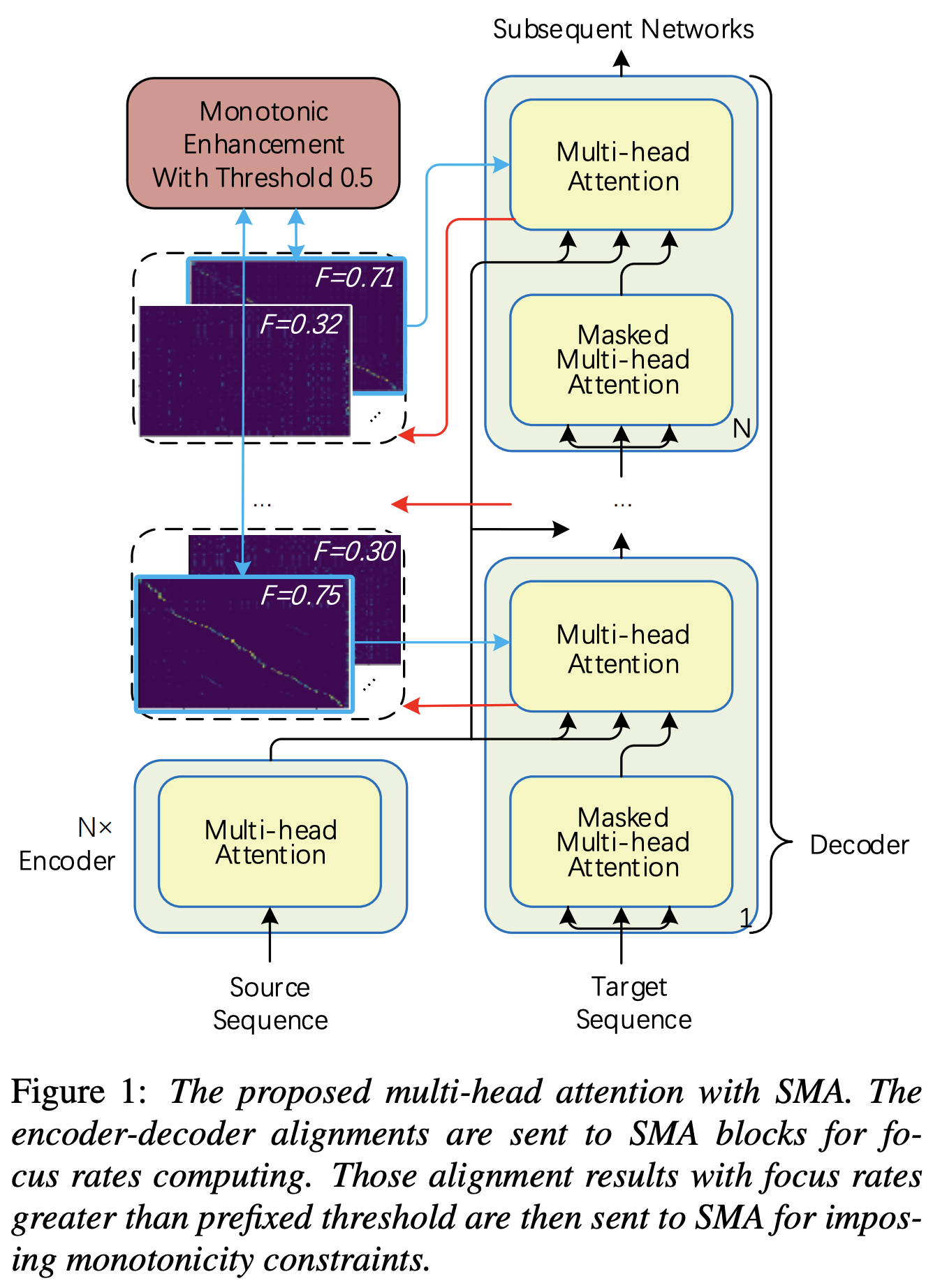
Você pode aplicar o SMA para corresponder ao espectrograma MEL ao texto no comprimento das seqüências. Abaixo estão alguns resultados que mostram a eficácia da SMA. A primeira figura é o alinhamento sem SMA ( hp.sma_tunable=False ) em 115k etapas. A segunda figura é aquela com ajuste SMA ( hp.sma_tunable=True ) em 125k etapas.
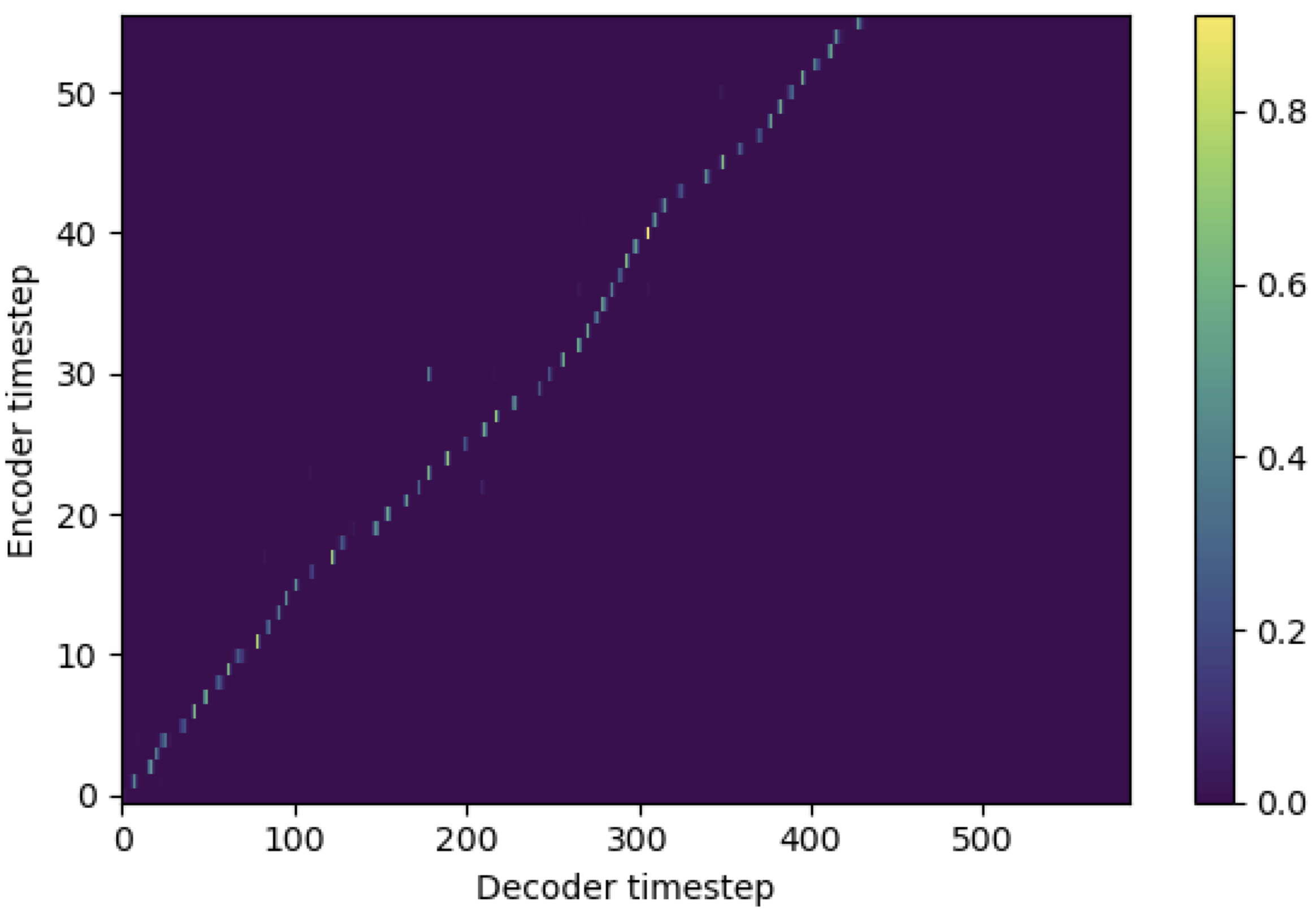
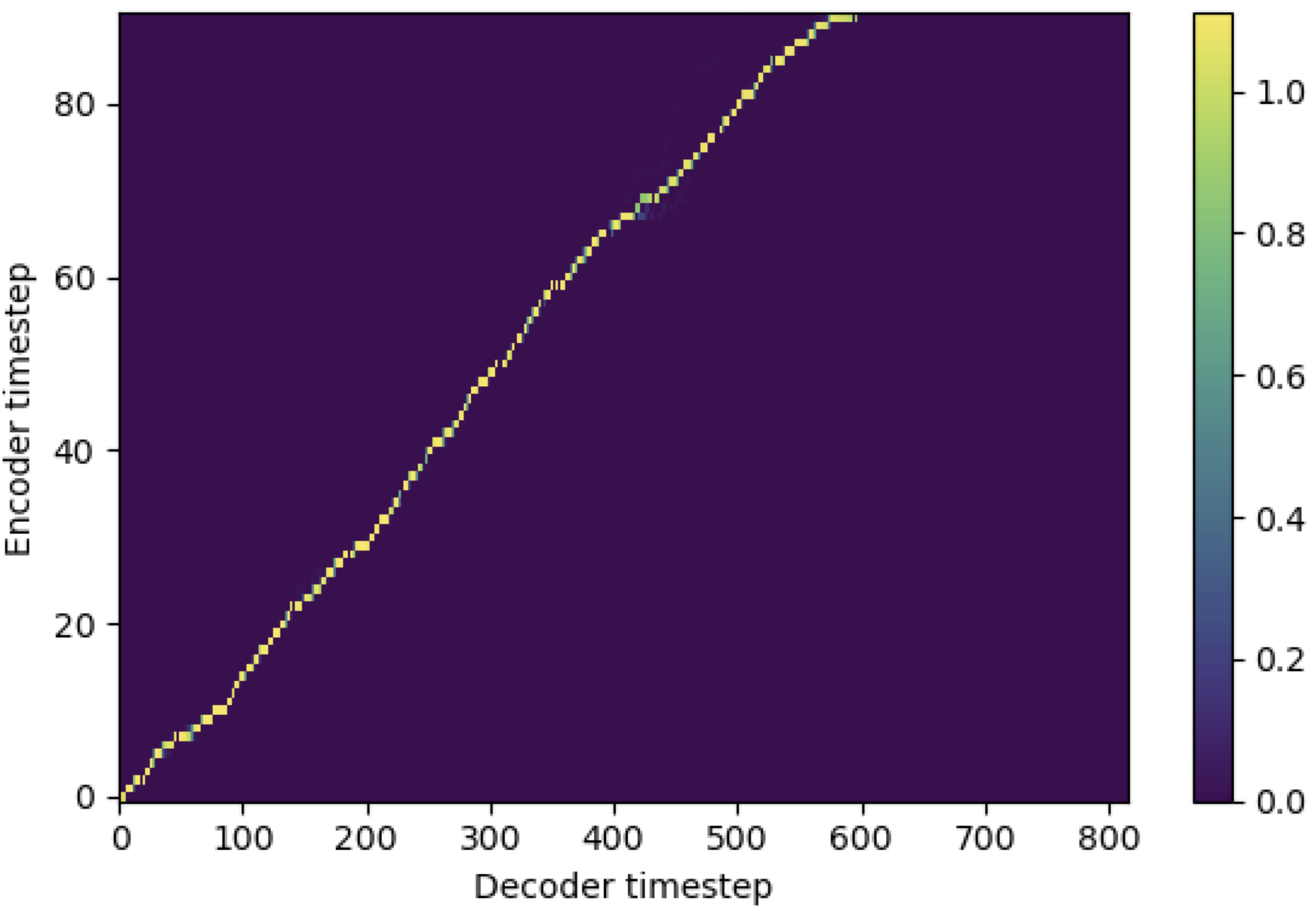
Como você pode ver, posso confirmar que o alinhamento está sendo altamente mais forte que a atenção normais de várias cabeças depois de aplicar o ajuste da SMA.
Primeiro, defina o SMA. Digamos que tenhamos uma codificação dimensional 256 e a atenção de 4 multi-cabeça.
from sma import StepwiseMonotonicMultiheadAttention
ref_attention = StepwiseMonotonicMultiheadAttention ( 256 , 256 // 4 , 256 // 4 ) E então, você pode aplicar atenção e obter um alinhamento da seguinte maneira. mel_len é o tamanho do quadro do áudio de referência, e seq_len é o comprimento do texto de entrada (que geralmente é uma sequência de fonemas). fr_max é um valor máximo da taxa de foco da função focused_head() . Tanto text_mask quanto attn_mask possuem 1. Para valores que serão mascarados e 0. Para que outros sejam mantidos.
"""
enc_out --- [batch, seq_len, 256]
attn --- [batch, seq_len, mel_len]
enc_text --- [batch, seq_len, 256]
enc_audio --- [batch, mel_len, 256]
text_mask --- [batch, seq_len, 1]
attn_mask --- [batch, seq_len, mel_len]
"""
# Attention
enc_out , attn , fr_max = ref_attention ( enc_text , enc_audio , enc_audio ,
mel_len , mask = attn_mask , query_mask = text_mask ) Como você pode ver, a SMA retorna a fusão de texto-Audio no tamanho do texto ( seq_len ), independentemente do tamanho do áudio ( mel_len ).
hp.sma_tunable é o hiperparâmetro que pode alternar o esquema de ajuste da atenção multi -cabeça monotônica gradual. Se definido True , a atenção multi -cabeça monotônica gradual é ativada. Caso contrário, é uma atenção normais de várias pessoas, assim como no transformador. Como no aprimoramento da monotonicidade para o TTS robusto de transformadores autoregressivos (chamaremos este artigo como 'artigo de referência' nos seguintes documentos), por exemplo, você pode treinar o módulo sem SMA para certas etapas para o treinamento e o modelo mais rápido convergirem e depois ativar a SMA, definindo sma_tunable=True para fazer um forte alinhamento monotônico em poucas etapas.expectation() é a FUCNTION calculando a pontuação de expectativa monotônica gradual, que é indicada como alpha no documento de referência.encoder na estrutura geral do TTS) e a chave e o valor são da codificação MEL-espectrograma (saída do reference encoder em geral MEL-Spectrograma Framework, por exemplo, codificador de referência no esquema GST). Como resultado, o módulo SMA de corrente converte o codificação de espectrograma MEL do comprimento do espectrograma MEL para o comprimento do texto. Você deve modificar cuidadosamente a dimensão (especialmente na função de expectation ) da consulta, chave e valor, dependendo da tarefa.focused_head selecionará o melhor alinhamento diagonal (aumentando monotonicamente) entre as cabeças. Segue -se a 'taxa de foco' na estrutura do FastSpeech, como no papel de referência. Diferente do papel de referência, a cabeça nominal máxima de foco é selecionada e não pelo limite. No entanto, você pode adotá -lo simplesmente adicionando prefixed_threshold (por exemplo, 0.5 ) à função focused_head . @misc{lee2021sma,
author = {Lee, Keon},
title = {Stepwise_Monotonic_Multihead_Attention},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Stepwise_Monotonic_Multihead_Attention}}
}


