Stepwise_Monotonic_Multihead_Attention
1.0.0
Pytorch Mise en œuvre de l'attention multi-tête monotone (SMA) similaire à l'amélioration de la monotonie pour un transformateur autorégressif robuste TTS
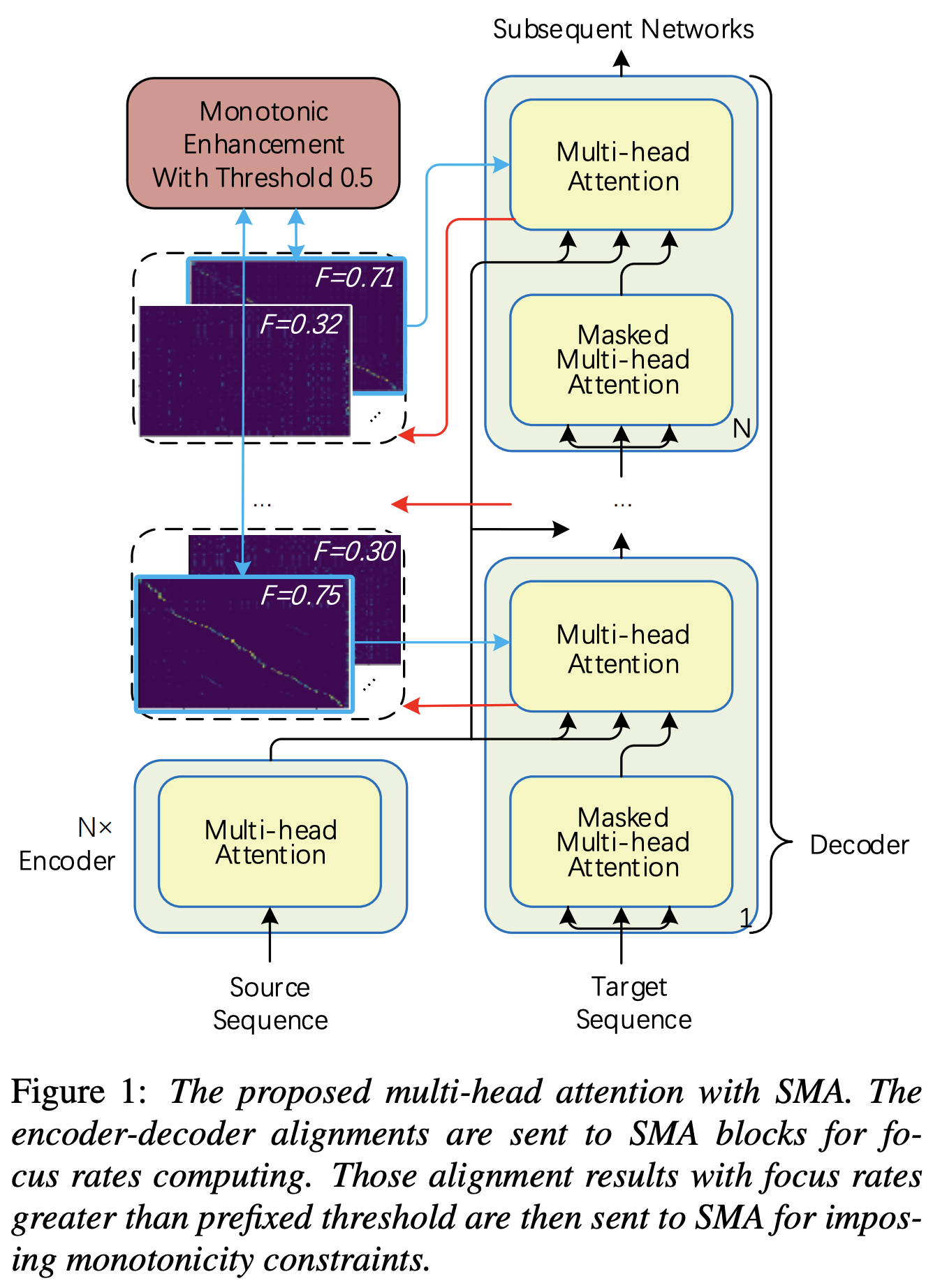
Vous pouvez appliquer SMA pour faire correspondre le spectrogramme MEL au texte dans la longueur des séquences. Vous trouverez ci-dessous quelques résultats montrant l'efficacité de la SMA. Le premier chiffre est l'alignement sans SMA ( hp.sma_tunable=False ) à 115k étapes. La deuxième figure est celle avec SMA Tunning ( hp.sma_tunable=True ) à 125k étapes.
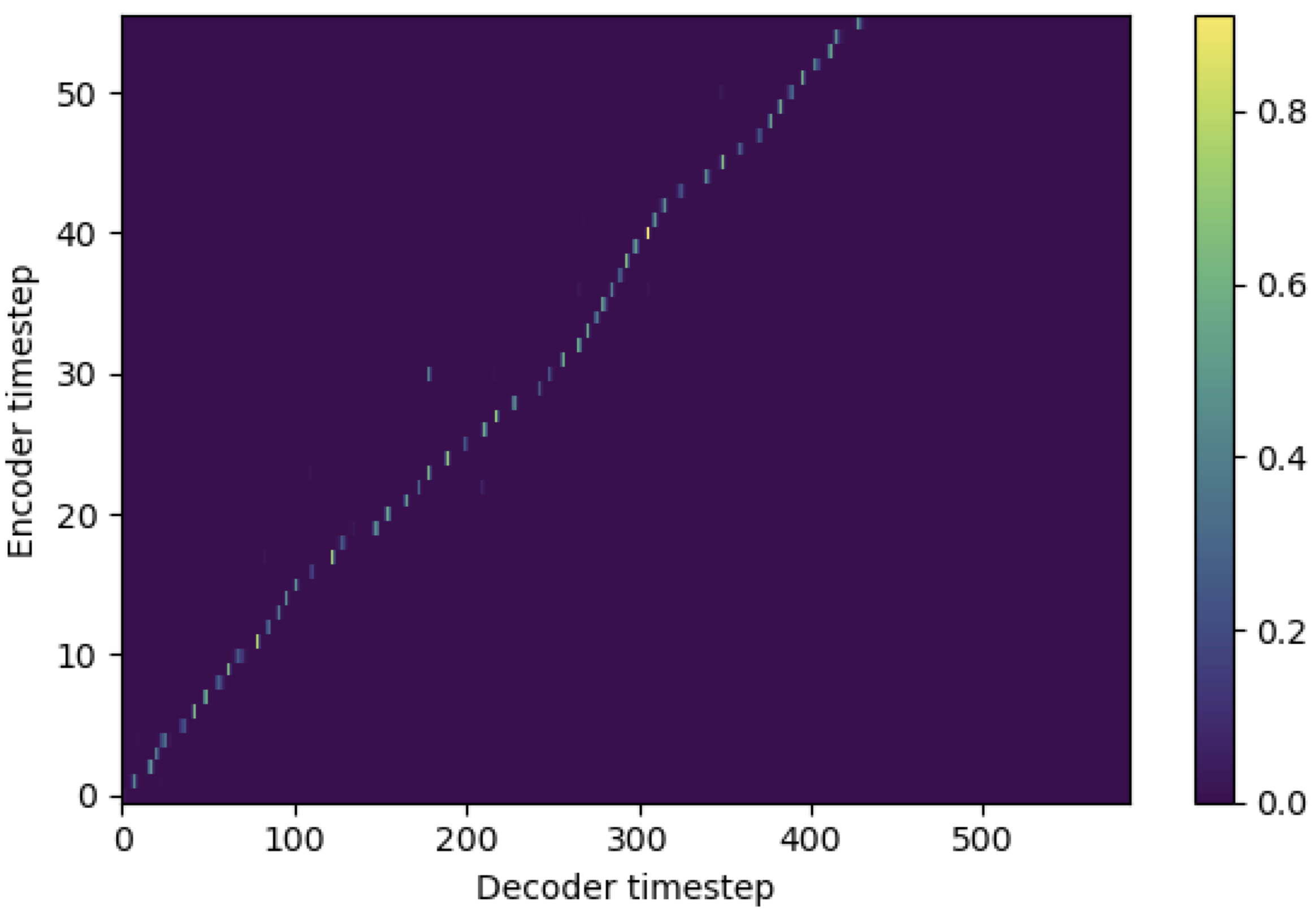
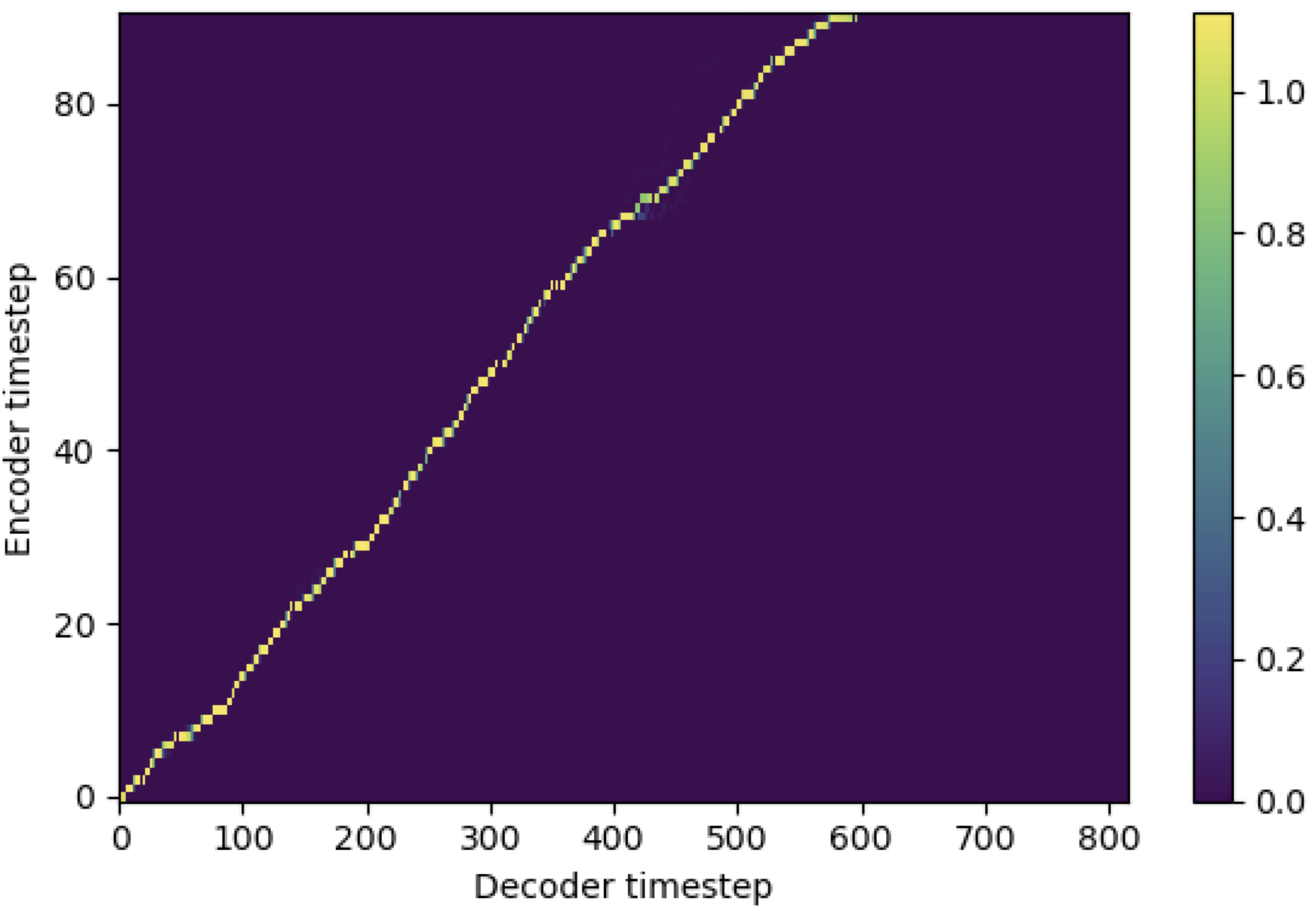
Comme vous pouvez le voir, je peux confirmer que l'alignement est très fort que l'attention multi-tête normale après avoir appliqué un tunning SMA.
Définissez d'abord le SMA. Disons que nous avons un codage dimensionnel 256 et une attention 4-Multihead.
from sma import StepwiseMonotonicMultiheadAttention
ref_attention = StepwiseMonotonicMultiheadAttention ( 256 , 256 // 4 , 256 // 4 ) Et puis, vous pouvez appliquer l'attention et obtenir un alignement comme suit. mel_len est la taille du trame de l'audio de référence, et seq_len est la longueur du texte d'entrée (qui est généralement une séquence de phonèmes). fr_max est une valeur maximale du taux de mise au point à partir de la fonction focused_head() . text_mask et attn_mask ont 1. Pour des valeurs qui seront masquées et 0. Pour que d'autres soient conservés.
"""
enc_out --- [batch, seq_len, 256]
attn --- [batch, seq_len, mel_len]
enc_text --- [batch, seq_len, 256]
enc_audio --- [batch, mel_len, 256]
text_mask --- [batch, seq_len, 1]
attn_mask --- [batch, seq_len, mel_len]
"""
# Attention
enc_out , attn , fr_max = ref_attention ( enc_text , enc_audio , enc_audio ,
mel_len , mask = attn_mask , query_mask = text_mask ) Comme vous pouvez le voir, SMA renvoie la fusion de texte audio dans la taille du texte ( seq_len ) quelle que soit la taille de l'audio ( mel_len ).
hp.sma_tunable est l'hyperparamètre qui peut basculer le schéma de tunning de l'attention multiple monotone pas à pas. S'il est réglé True , l'attention multi-tête monotonique pas à pas est activée. Sinon, c'est une attention normale à plusieurs tête, tout comme dans Transformer. Comme dans l'amélioration de la monotonie pour un transformateur autorégressif robuste TTS (nous appellerons ce document comme un `` document de référence '' dans les documents suivants), par exemple, vous pouvez former un module sans SMA pour certaines étapes vers la formation plus rapide et modèle converge, puis activer SMA en définissant sma_tunable=True pour faire un alignement monotonique fort en quelques étapes.expectation() est le score d'attente monotonique à étapes de calcul de Fucntion qui est désignée comme alpha dans le document de référence.encoder dans le cadre TTS général) et la clé et la valeur proviennent du codage de spectrogramme de MEL (sortie du reference encoder dans le cadre général de codage de spectrogramme MEL, par exemple, encodeur de référence dans le schéma de GST). En conséquence, le module SMA actuel convertit le spectrogramme MEL codant de la longueur du spectrogramme de MEL à la longueur du texte. Vous devez modifier attentivement la dimension (en particulier dans la fonction expectation ) de la requête, de la clé et de la valeur en fonction de la tâche.focused_head sélectionnera le meilleur alignement diagonal (augmentant monotone) parmi les têtes. Il suit le «taux de mise au point» dans FastSpeech Framework comme dans le document de référence. Différent du papier de référence, la tête notée de mise au point maximale est sélectionnée plutôt que par seuil. Cependant, vous pouvez l'adopter en ajoutant simplement prefixed_threshold (par exemple, 0.5 ) à la fonction focused_head . @misc{lee2021sma,
author = {Lee, Keon},
title = {Stepwise_Monotonic_Multihead_Attention},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Stepwise_Monotonic_Multihead_Attention}}
}


