Stepwise_Monotonic_Multihead_Attention
1.0.0
Pytorch Implementasi Perhatian Multihead Monotonik bertahap (SMA) Mirip dengan meningkatkan monotonisitas untuk TT transformator autoregresif yang kuat
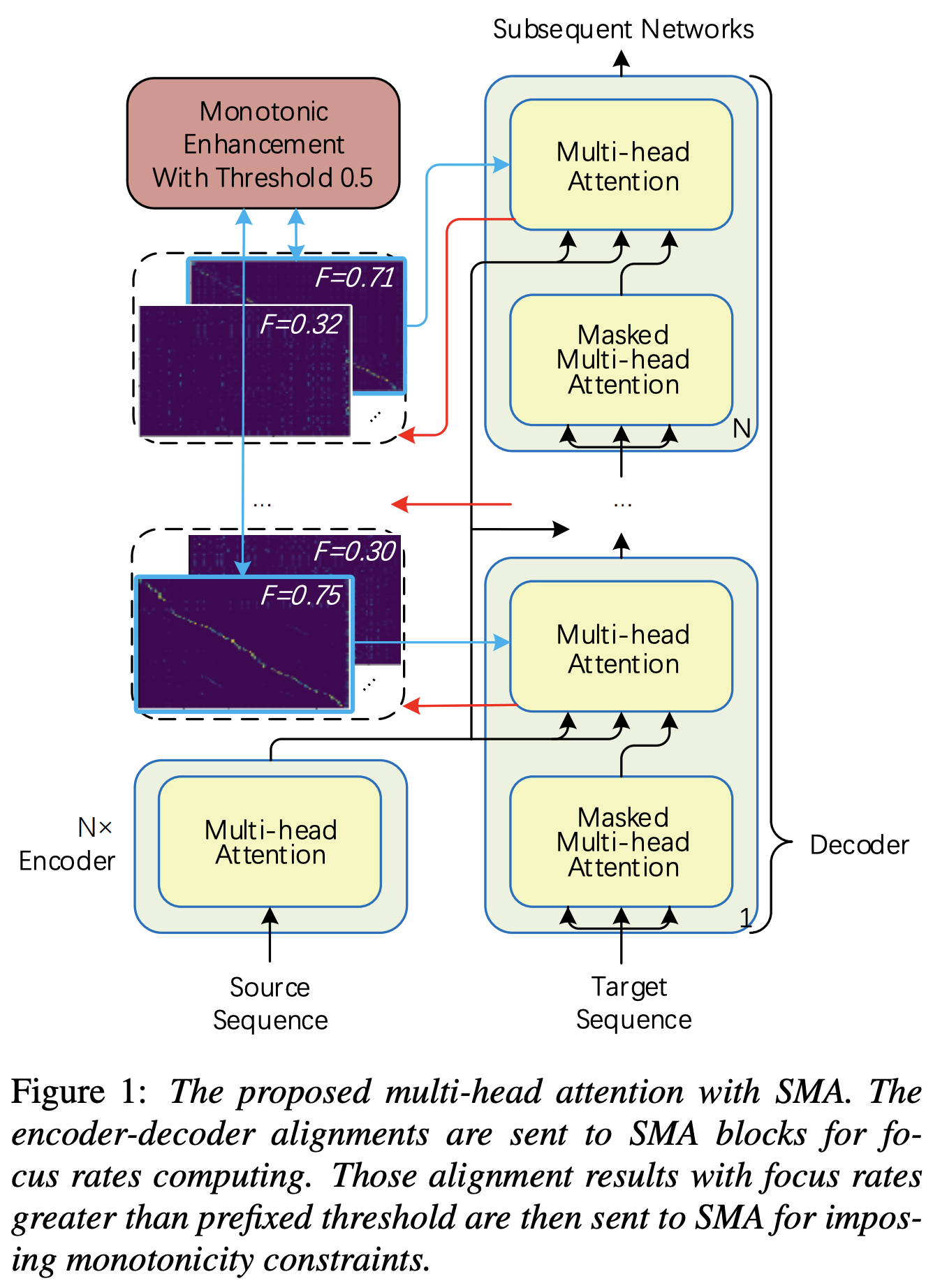
Anda dapat menerapkan SMA untuk mencocokkan Mel-Spectrogram dengan teks dalam panjang urutan. Di bawah ini adalah beberapa hasil yang menunjukkan efektivitas SMA. Angka pertama adalah penyelarasan tanpa SMA ( hp.sma_tunable=False ) pada langkah 115k. Sosok kedua adalah satu dengan tunning SMA ( hp.sma_tunable=True ) pada langkah 125k.
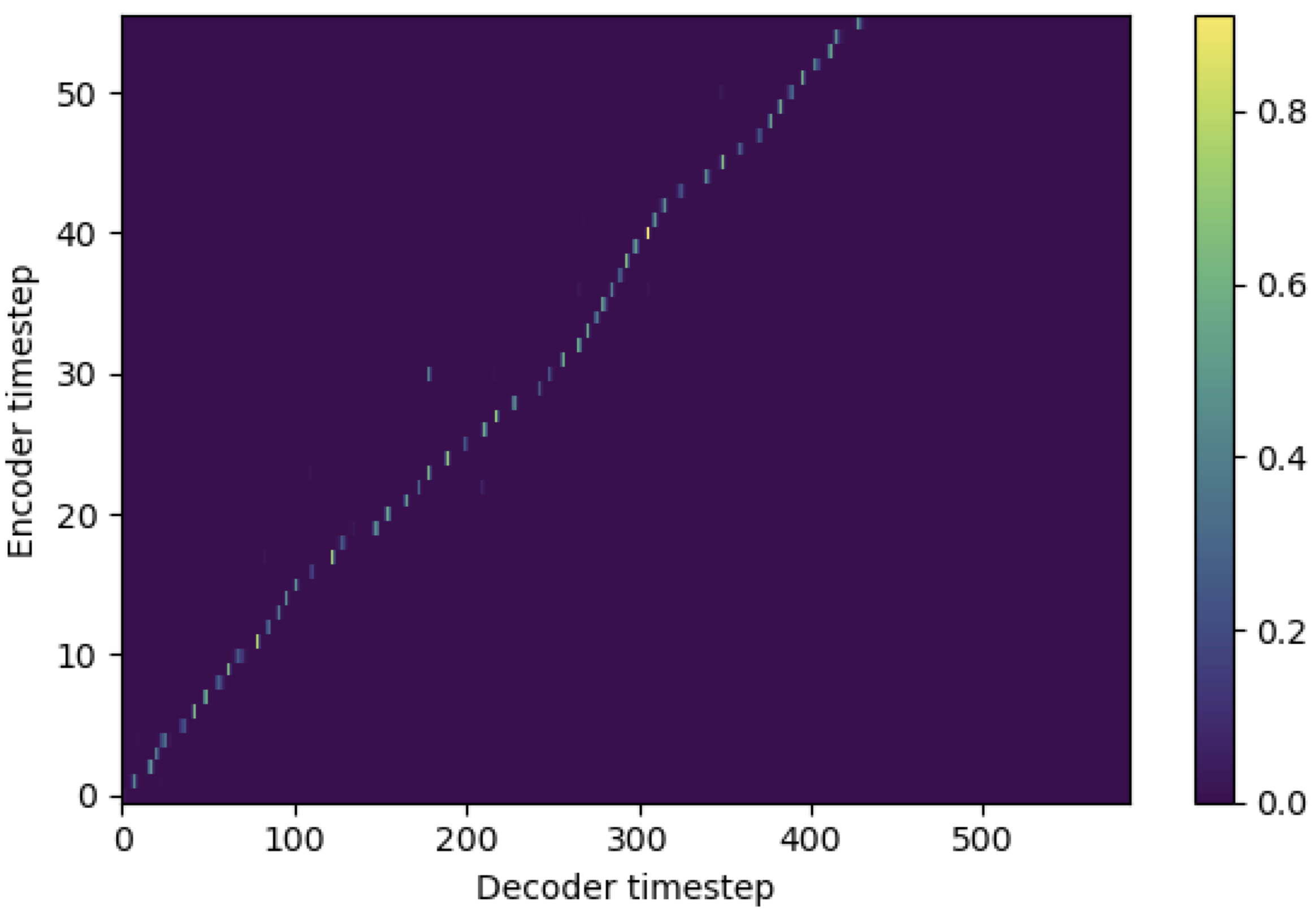
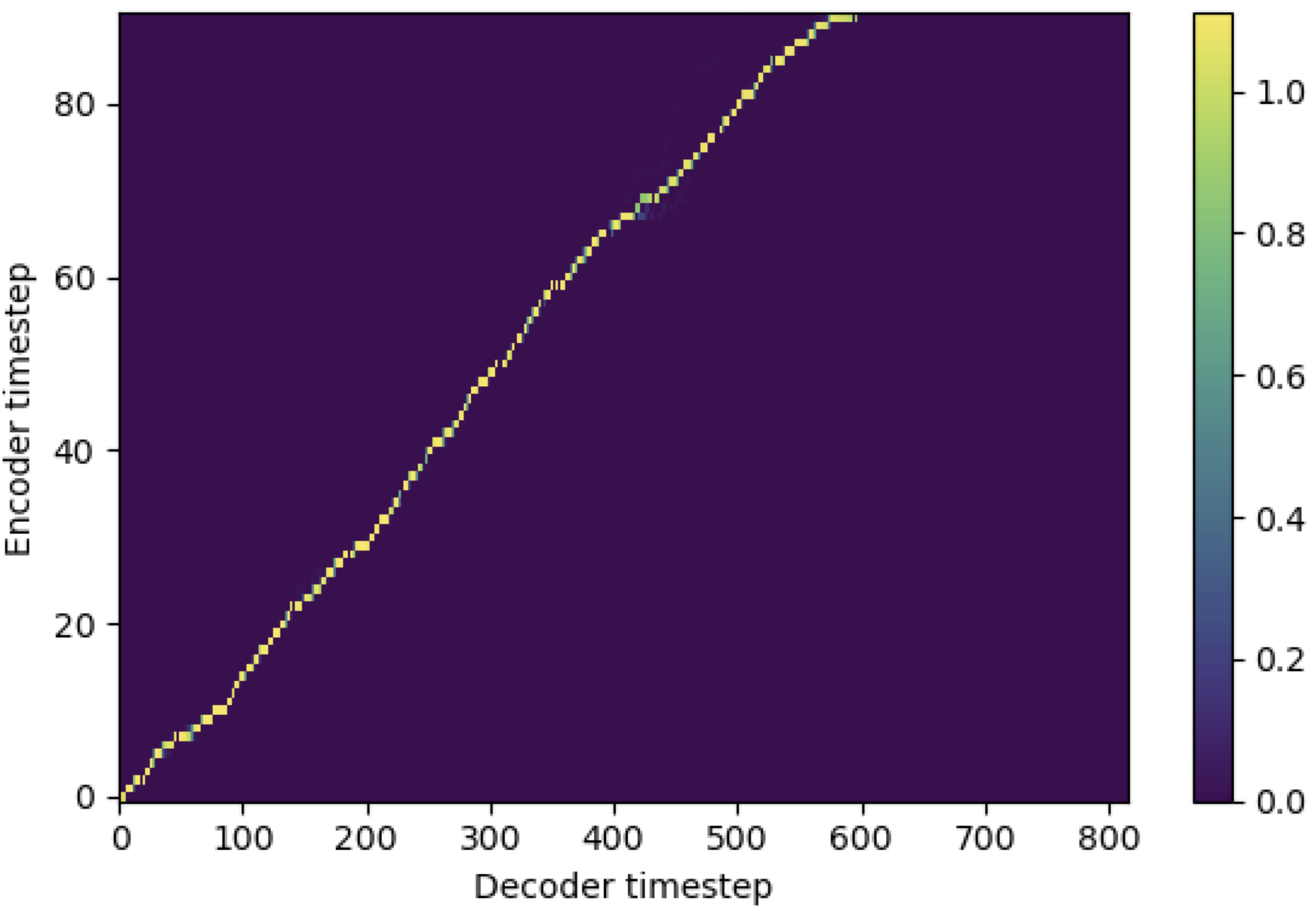
Seperti yang Anda lihat, saya dapat mengonfirmasi bahwa perataannya menjadi sangat kuat dari perhatian multi -kepala normal setelah menerapkan tunning SMA.
Pertama, tentukan SMA. Katakanlah kita memiliki 256 pengkodean dimensi dan perhatian 4-multi.
from sma import StepwiseMonotonicMultiheadAttention
ref_attention = StepwiseMonotonicMultiheadAttention ( 256 , 256 // 4 , 256 // 4 ) Dan kemudian, Anda bisa menerapkan perhatian dan mendapatkan keselarasan sebagai berikut. mel_len adalah ukuran bingkai audio referensi, dan seq_len adalah panjang teks input (yang biasanya merupakan urutan fonem). fr_max adalah nilai maksimum laju fokus dari fungsi focused_head() . Baik text_mask dan attn_mask memiliki 1. Untuk nilai -nilai yang akan ditutup dan 0. agar orang lain disimpan.
"""
enc_out --- [batch, seq_len, 256]
attn --- [batch, seq_len, mel_len]
enc_text --- [batch, seq_len, 256]
enc_audio --- [batch, mel_len, 256]
text_mask --- [batch, seq_len, 1]
attn_mask --- [batch, seq_len, mel_len]
"""
# Attention
enc_out , attn , fr_max = ref_attention ( enc_text , enc_audio , enc_audio ,
mel_len , mask = attn_mask , query_mask = text_mask ) Seperti yang Anda lihat, SMA mengembalikan fusi teks-audio dalam ukuran teks ( seq_len ) terlepas dari ukuran audio ( mel_len ).
hp.sma_tunable adalah hiperparameter yang dapat beralih dari skema tunning perhatian multi -kepala bertahap monotonik. Jika ditetapkan True , perhatian multi -stepwise monotonik diaktifkan. Lain, ini adalah perhatian multi -kepala yang normal, seperti di Transformer. Seperti dalam meningkatkan monotonisitas untuk TT transformator autoregresif yang kuat (kami akan menyebut makalah ini sebagai 'kertas referensi' dalam dokumen -dokumen berikut), misalnya, Anda dapat melatih modul tanpa SMA untuk langkah -langkah tertentu ke pelatihan dan model yang lebih cepat, dan kemudian mengaktifkan SMA dengan mengatur sma_tunable=True untuk membuat alignment monotonik yang kuat dalam beberapa langkah.expectation() adalah skor ekspektasi monotonik bertahap menghitung yang dilambangkan sebagai alpha dalam kertas referensi.encoder dalam kerangka kerja TTS umum) dan kunci dan nilainya berasal dari pengkodean Mel-spectrogram (output dari reference encoder dalam kerangka pengkodean pengkodean spektrogram Mel-Mel umum, misalnya, enkoder referensi dalam skema GST). Akibatnya, modul SMA saat ini mengonversi pengkodean Mel-spectrogram dari panjang Mel-spectrogram ke panjang teks. Anda harus dengan hati -hati memodifikasi dimensi (terutama dalam fungsi expectation ) dari kueri, kunci, dan nilai tergantung pada tugas.focused_head akan memilih penyelarasan diagonal terbaik (peningkatan monotonik) di antara kepala. Ini mengikuti 'laju fokus' dalam kerangka fastspeech seperti pada makalah referensi. Berbeda dari kertas referensi, kepala peringkat fokus maksimum dipilih daripada dengan ambang batas. Namun, Anda dapat mengadopsinya dengan hanya menambahkan prefixed_threshold (misalnya, 0.5 ) ke fungsi focused_head . @misc{lee2021sma,
author = {Lee, Keon},
title = {Stepwise_Monotonic_Multihead_Attention},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Stepwise_Monotonic_Multihead_Attention}}
}


