Stepwise_Monotonic_Multihead_Attention
1.0.0
تنفيذ Pytorch من الانتباه المتعدد الراتجة (SMA) على غرار تعزيز الرتابة لمحولات القطب القوية tts tts
يمكنك تطبيق SMA لمطابقة طيف الميل مع النص في طول التسلسل. فيما يلي بعض النتائج التي توضح فعالية SMA. الشكل الأول هو المحاذاة بدون SMA ( hp.sma_tunable=False ) عند خطوات 115k. الشكل الثاني هو الشكل الذي يحتوي على SMA Tunning ( hp.sma_tunable=True ) عند خطوات 125k.
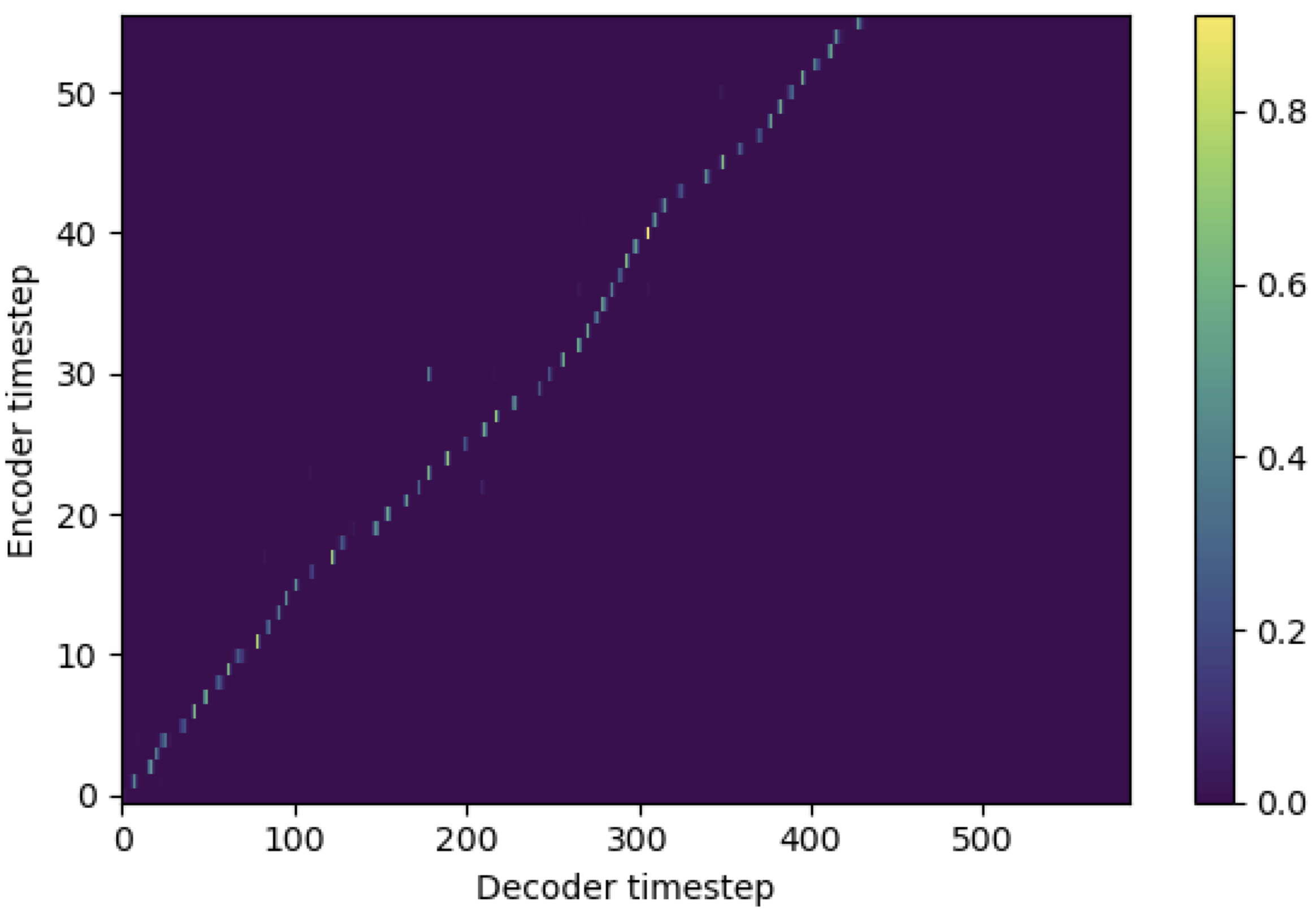
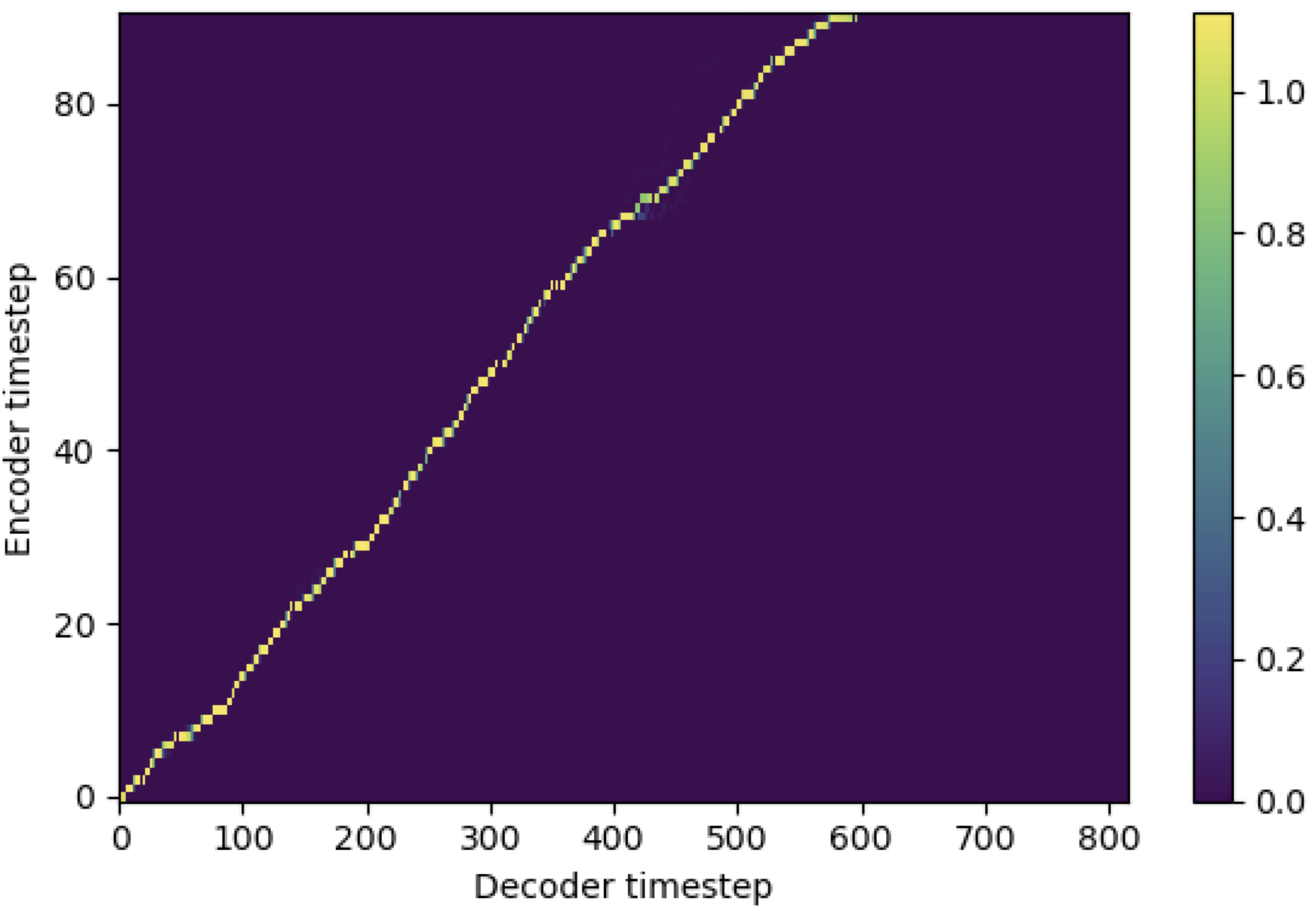
كما ترون ، يمكنني أن أؤكد أن المحاذاة أقوى للغاية من الاهتمام العادي متعدد الرأس بعد تطبيق SMA Tunning.
أولا ، حدد SMA. دعنا نقول أن لدينا ترميز 256 الأبعاد والاهتمام 4-multihead.
from sma import StepwiseMonotonicMultiheadAttention
ref_attention = StepwiseMonotonicMultiheadAttention ( 256 , 256 // 4 , 256 // 4 ) وبعد ذلك ، يمكنك تطبيق الانتباه والحصول على محاذاة على النحو التالي. mel_len هو حجم الإطار للصوت المرجعي ، و seq_len هو طول نص الإدخال (الذي عادة ما يكون تسلسل الصوتيات). fr_max هي القيمة القصوى لمعدل التركيز من وظيفة focused_head() . كل من text_mask و attn_mask لهما 1. للقيم التي سيتم إخفاءها و 0. ليتم الاحتفاظ بالآخرين.
"""
enc_out --- [batch, seq_len, 256]
attn --- [batch, seq_len, mel_len]
enc_text --- [batch, seq_len, 256]
enc_audio --- [batch, mel_len, 256]
text_mask --- [batch, seq_len, 1]
attn_mask --- [batch, seq_len, mel_len]
"""
# Attention
enc_out , attn , fr_max = ref_attention ( enc_text , enc_audio , enc_audio ,
mel_len , mask = attn_mask , query_mask = text_mask ) كما ترون ، تقوم SMA بإرجاع دمج النص في حجم النص ( seq_len ) بغض النظر عن حجم الصوت ( mel_len ).
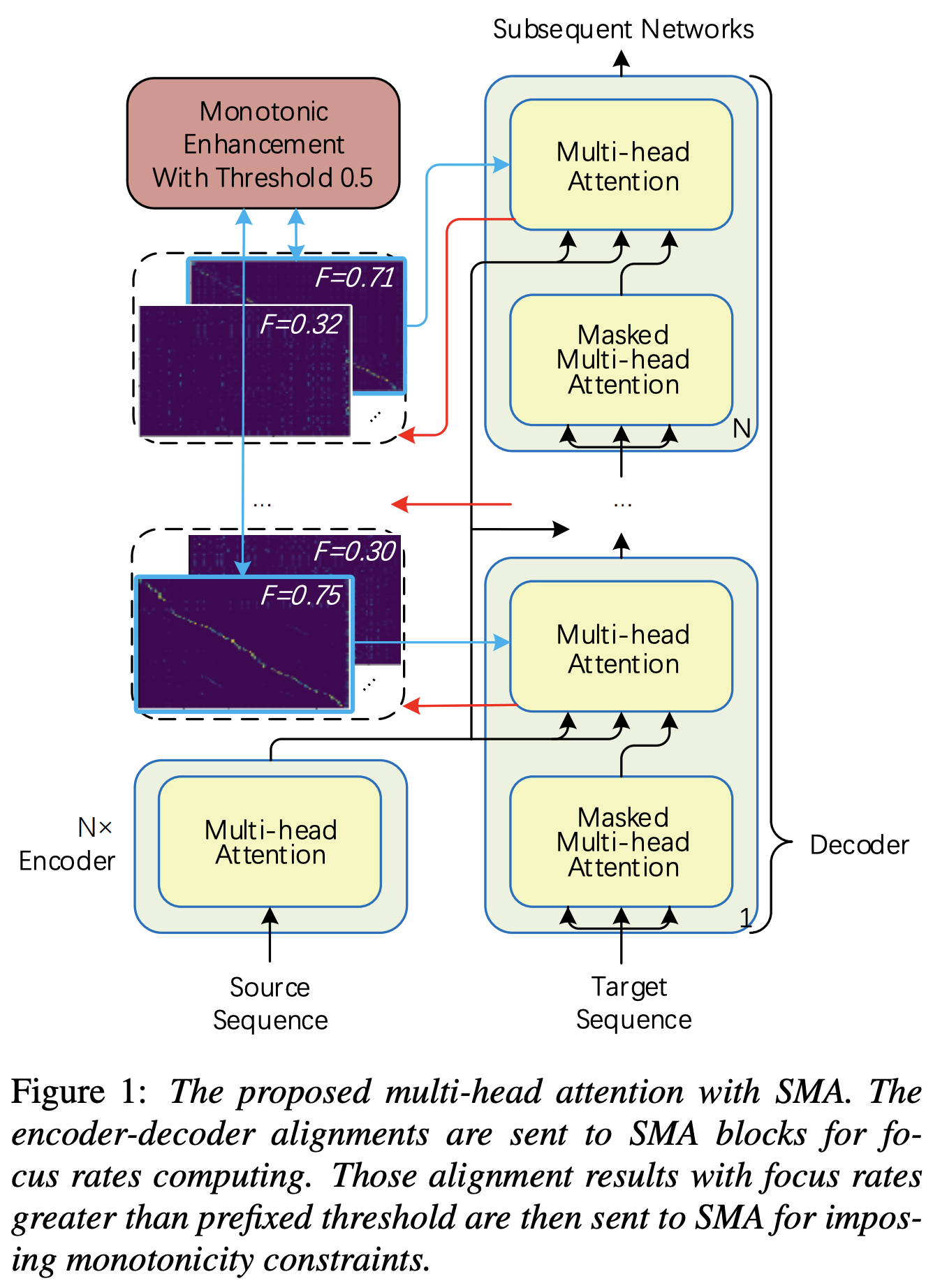
hp.sma_tunable هو المتقلب الذي يمكنه تبديل مخطط التغلب على الاهتمام المتعدد الرتابة التدريجي. إذا تم True ، يتم تنشيط الاهتمام المتعدد الرتابة التدريجي. وإلا ، فهو اهتمام طبيعي متعدد الرأس ، تمامًا كما هو الحال في المحول. كما هو الحال في تعزيز رتابة TTS القوية المحول التلقائي (سوف نسمي هذه الورقة بأنها "ورقة مرجعية" في المستندات التالية) ، على سبيل المثال ، يمكنك تدريب الوحدة النمطية دون SMA لبعض الخطوات على التدريب الأسرع ونموذج النموذج ، ثم تنشيط SMA عن طريق تحديد sma_tunable=True أن يتنقل قوي في خطوات قليلة.expectation() هو FUCNTION حساب درجة التوقعات الرتابة التدريجي التي يُشار إليها على أنها alpha في الورقة المرجعية.encoder بشكل عام TTS الإطار) والفتاح والقيمة من ترميز طيف MEL (إخراج reference encoder في إطار تشفير طيف MEL-SPEMWORG ، على سبيل المثال ، EGER المرجعي في مخطط GST). نتيجة لذلك ، تقوم وحدة SMA الحالية بتحويل ترميز طيف الميل من طول طيف الميل إلى طول النص. يجب عليك تعديل البعد (خاصة في وظيفة expectation ) من الاستعلام والمفتاح والقيمة اعتمادًا على المهمة.focused_head أفضل محاذاة قطرية (متزايدة رتابة) بين الرؤوس. يتبع "معدل التركيز" في إطار عمل سريع كما في الورقة المرجعية. يختلف عن الورقة المرجعية ، يتم اختيار الحد الأقصى للرأس المصنّع من التركيز بدلاً من العتبة. ومع ذلك ، يمكنك تبنيه ببساطة عن طريق إضافة prefixed_threshold (على سبيل المثال ، 0.5 ) إلى وظيفة focused_head . @misc{lee2021sma,
author = {Lee, Keon},
title = {Stepwise_Monotonic_Multihead_Attention},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Stepwise_Monotonic_Multihead_Attention}}
}


