Stepwise_Monotonic_Multihead_Attention
1.0.0
Реализация Pytorch пошагового монотонного внимания мультиголов (SMA), аналогичная улучшению монотонности для надежных авторегрессивных трансформаторов
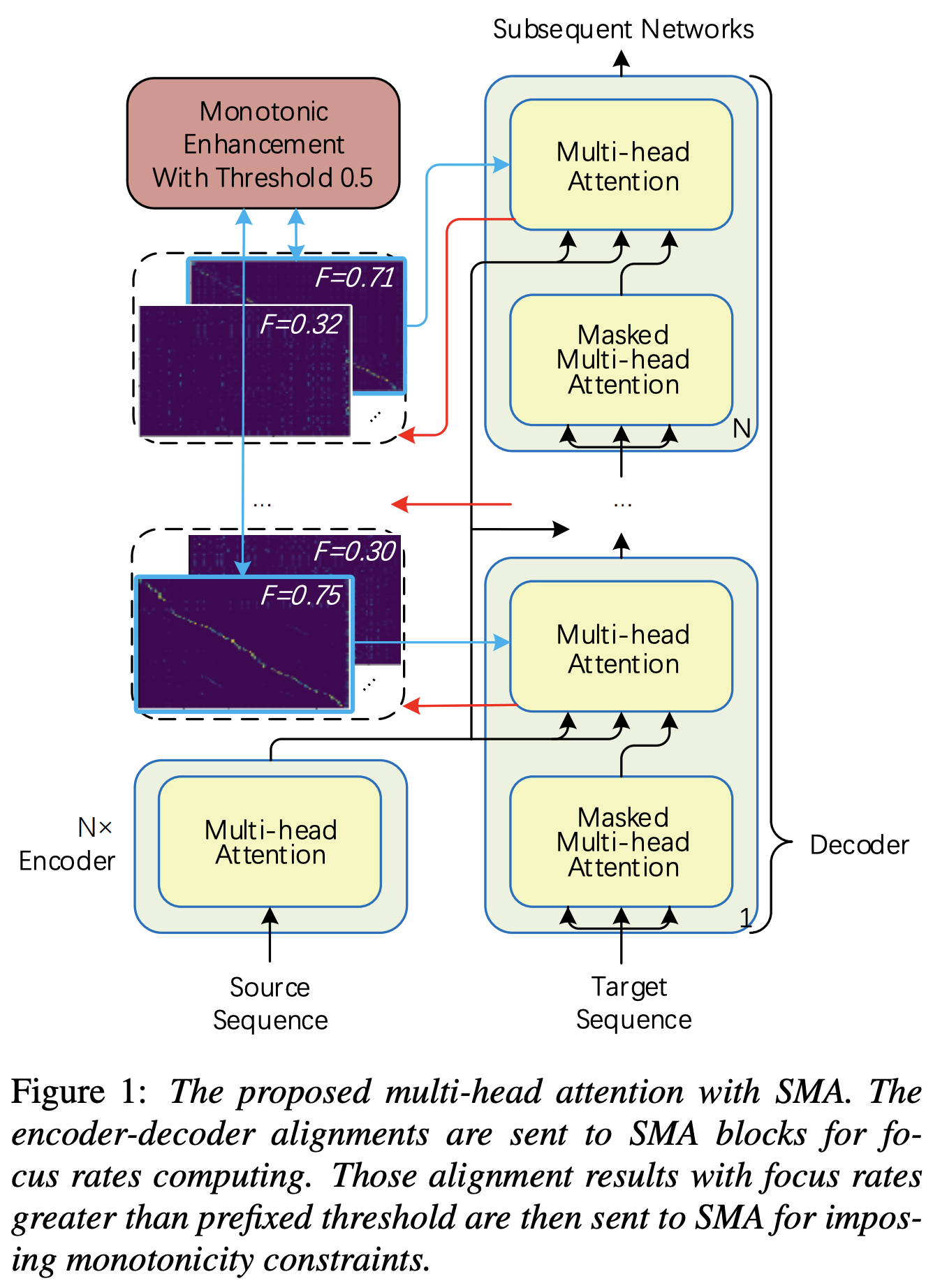
Вы можете применить SMA в соответствии с мель-спектрограммой для текста в длине последовательностей. Ниже приведены некоторые результаты, показывающие эффективность SMA. Первая фигура - выравнивание без SMA ( hp.sma_tunable=False ) на 115 тысячах шагов. Вторая фигура - такая с SMA Tunning ( hp.sma_tunable=True ) на 125 тысячах шагов.
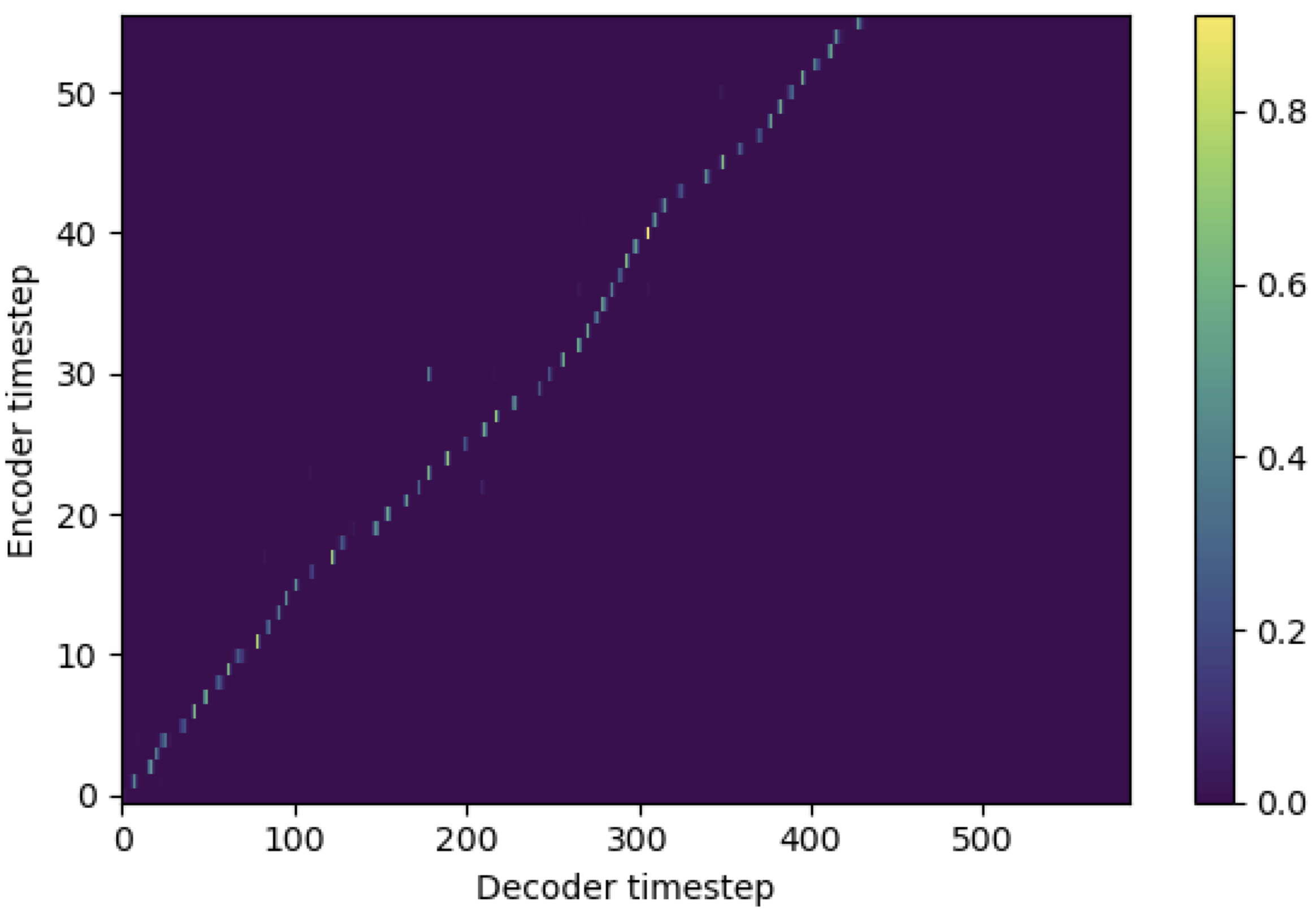
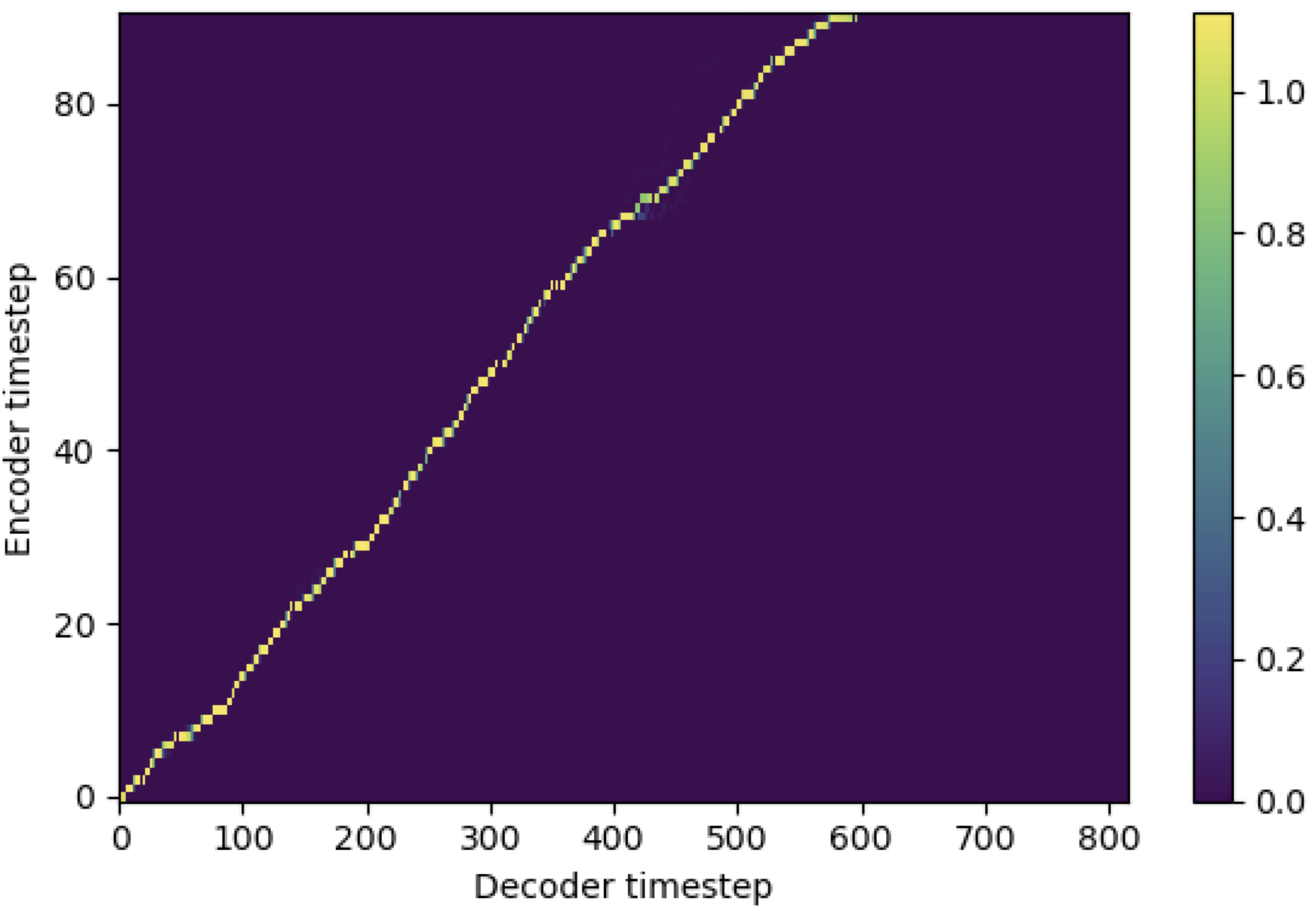
Как вы можете видеть, я могу подтвердить, что выравнивание очень сильнее, чем обычное внимание после применения SMA Tunning.
Во -первых, определить SMA. Допустим, у нас есть 256 размерных кодировков и 4-го мученика.
from sma import StepwiseMonotonicMultiheadAttention
ref_attention = StepwiseMonotonicMultiheadAttention ( 256 , 256 // 4 , 256 // 4 ) И затем вы можете применить внимание и получить выравнивание следующим образом. mel_len - это размер кадра эталонного звука, а seq_len - это длина входного текста (который обычно является последовательности фонем). fr_max - это максимальное значение скорости фокусировки от функции focused_head() . И text_mask и attn_mask имеют 1. Для значений, которые будут замаскированы, и 0. Для других, которые будут сохранены.
"""
enc_out --- [batch, seq_len, 256]
attn --- [batch, seq_len, mel_len]
enc_text --- [batch, seq_len, 256]
enc_audio --- [batch, mel_len, 256]
text_mask --- [batch, seq_len, 1]
attn_mask --- [batch, seq_len, mel_len]
"""
# Attention
enc_out , attn , fr_max = ref_attention ( enc_text , enc_audio , enc_audio ,
mel_len , mask = attn_mask , query_mask = text_mask ) Как вы можете видеть, SMA возвращает слияние текста-авторского размера ( seq_len ) независимо от размера звука ( mel_len ).
hp.sma_tunable - это гиперпараметт, который может переключать схему настроения поэтапного монотонного внимания. Если установить True , активируется пошаговое монотонное внимание с несколькими головами. В остальном это нормальное внимание, как в трансформаторе. Как и в улучшении монотонности для надежных авторегрессивных трансформаторов (мы будем называть эту статью как «справочную статью» в следующих документах), вы можете обучать модуль без SMA для определенных шагов к более быстрому обучению и сходимости модели, а затем активируйте SMA, установив sma_tunable=True для выполнения сильного монотонного выравнивания в нескольких шагах.expectation() - это исчезновение поэтапного монотонного монотонного балла, которое обозначается как alpha в эталонном документе.encoder в общей структуре TTS), а ключ и значение взяты из кодирования мель-спектрограммы (вывод reference encoder в общей структуре кодирования мель-спектрограммы, например, эталонный кодер в схеме GST). В результате ток SMA-модуль преобразует мель-спектрограмму, кодирующую от длины мель-спектрограммы в длину текста. Вы должны тщательно изменить измерение (особенно в функции expectation ) запроса, ключа и значения в зависимости от задачи.focused_head выберет наилучшее диагональное (монотонное увеличение) выравнивание среди голов. Это следует за «скоростью фокусировки» в рамках Fastspeech, как в эталонной бумаге. В отличие от эталонной бумаги, выбирается максимальная номинальная головка фокуса, а не пороговым значением. Тем не менее, вы можете принять его, просто добавив prefixed_threshold (например, 0.5 ) в функцию focused_head . @misc{lee2021sma,
author = {Lee, Keon},
title = {Stepwise_Monotonic_Multihead_Attention},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Stepwise_Monotonic_Multihead_Attention}}
}


