Parallel Tacotron2
1.0.0
การใช้งาน Pytorch ของ Tacotron 2 คู่ขนานของ Google: โมเดล TTS ที่ไม่ใช่ระบบประสาทแบบอัตโนมัติที่มีการสร้างแบบจำลองระยะเวลาที่แตกต่างกัน
2021.05.25: Only the soft-DTW remains the last hurdle! ตามคำแนะนำของผู้เขียนเกี่ยวกับการดำเนินการฉันได้ทำการทดสอบหลายครั้งในแต่ละโมดูลทีละโมเลกุลภายใต้สัญญาณระยะเวลาภายใต้การดูแลด้วยการสูญเสีย L1 (FastSpeech2) จนถึงตอนนี้ฉันสามารถยืนยันได้ว่าโมดูลทั้งหมดยกเว้น Soft-DTW ทำงานได้ดีดังนี้ (synthesized spectrogram, GT spectrogram, การจัดตำแหน่งที่เหลือและ W จากการเรียนรู้ที่เรียนรู้จากบนลงล่าง)
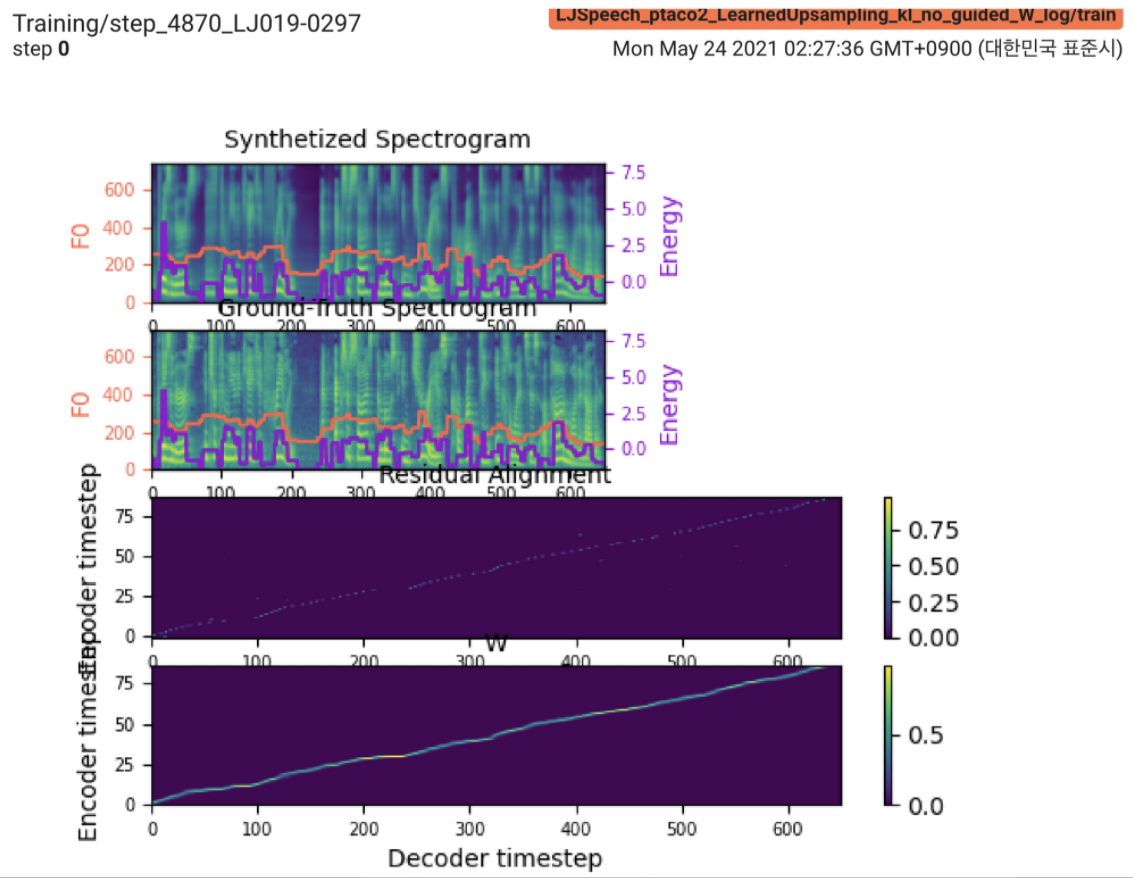
สำหรับรายละเอียดโปรดตรวจสอบบันทึกการกระทำล่าสุดและส่วนปัญหาการใช้งานที่อัปเดต นอกจากนี้คุณสามารถค้นหาการทดลองอย่างต่อเนื่องได้ที่ https://github.com/keonlee9420/fastspeech2/commits/ptaco2
2021.05.15: การดำเนินการเสร็จสิ้น ตรวจสอบสติในการฝึกอบรมและการอนุมาน แต่ก็ยังไม่สามารถมาบรรจบกันได้
I'm waiting for your contribution! โปรดแจ้งให้ฉันทราบหากคุณพบข้อผิดพลาดใด ๆ ในการดำเนินการของฉันหรือคำแนะนำที่มีค่าใด ๆ ในการฝึกอบรมแบบจำลองให้สำเร็จ ดูส่วนปัญหาการใช้งาน
คุณสามารถติดตั้งการพึ่งพา Python ด้วย
pip3 install -r requirements.txt ติดตั้ง Fairseq (เอกสารอย่างเป็นทางการ, GitHub) เพื่อใช้ประโยชน์ LConvBlock โปรดตรวจสอบ #5 เพื่อแก้ไขปัญหาใด ๆ เกี่ยวกับการติดตั้ง
ชุดข้อมูลที่รองรับ:
หลังจากดาวน์โหลดชุดข้อมูลให้ตั้งค่า corpus_path ใน preprocess.yaml และเรียกใช้สคริปต์การเตรียมการ:
python3 prepare_data.py config/LJSpeech/preprocess.yaml
จากนั้นเรียกใช้สคริปต์การประมวลผลล่วงหน้า:
python3 preprocess.py config/LJSpeech/preprocess.yaml
ฝึกอบรมแบบจำลองของคุณด้วย
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
แบบจำลองยังไม่สามารถมาบรรจบกันได้ ฉันกำลังดีบัก แต่มันจะเพิ่มขึ้นหากการบริจาคที่ยอดเยี่ยมของคุณพร้อม!
สำหรับการอนุมานครั้งเดียววิ่ง
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 900000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
คำพูดที่สร้างขึ้นจะถูกบันทึกไว้ใน output/result/
รองรับการอนุมานแบบแบทช์ด้วยลอง
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step 900000 --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
เพื่อสังเคราะห์คำพูดทั้งหมดใน preprocessed_data/LJSpeech/val.txt
ใช้
tensorboard --logdir output/log/LJSpeech
เพื่อให้บริการ Tensorboard บนบ้านของคุณ
โดยรวมแล้วการทำให้เป็นมาตรฐานหรือการเปิดใช้งานซึ่งไม่ได้แนะนำในกระดาษต้นฉบับมีการจัดเรียงอย่างเพียงพอเพื่อป้องกันค่า NAN (การไล่ระดับสี) ในการคำนวณไปข้างหน้าและย้อนกลับ (น่านระบุว่ามีบางอย่างผิดปกติในเครือข่าย)
FFTBlock ของ fastspeech2 สำหรับบล็อกหม้อแปลงของตัวเข้ารหัสข้อความ0.2 สำหรับตัว ConvBlock ข้อความgrapheme_to_phoneme (ดู ./text / init ) 80 channels mel-spectrogrom แทน 128-binnn.SiLU() สำหรับการเปิดใช้งาน SwishW และ C การดำเนินการต่อการต่อเนื่องจะถูกนำไปใช้ระหว่าง S , E และ V หลังจากการแพร่กระจายเฟรมโดเมน (T โดเมน) ของ V LConvBlock และการฝังตำแหน่งไซน์ปกติปกติnn.Tanh() กับแต่ละเอาต์พุต LConvBLock (ตามรูปแบบการเปิดใช้งานของชิ้นส่วนถอดรหัสใน FastSpeech2) model/soft_dtw_cuda.py ซึ่งสะท้อนให้เห็นถึงการเรียกซ้ำที่แนะนำในกระดาษต้นฉบับE เท่านั้น แต่ใช้เป็นฟังก์ชั่นการสูญเสียผลิตภัณฑ์ Jacobian จะถูกเพิ่มเข้ามาเพื่อส่งคืนเป้าหมายการเข้าร่วมของ R WRT Input X8 ใน 24GIB GPU (TITAN RTX) เนื่องจากปัญหาความซับซ้อนของพื้นที่ในการสูญเสีย Soft-DTW @misc{lee2021parallel_tacotron2,
author = {Lee, Keon},
title = {Parallel-Tacotron2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Parallel-Tacotron2}}
}


