Parallel Tacotron2
1.0.0
Implementación de Pytorch de Tacotron 2 paralelo de Google: un modelo TTS neural no autorgresivo con modelado de duración diferenciable
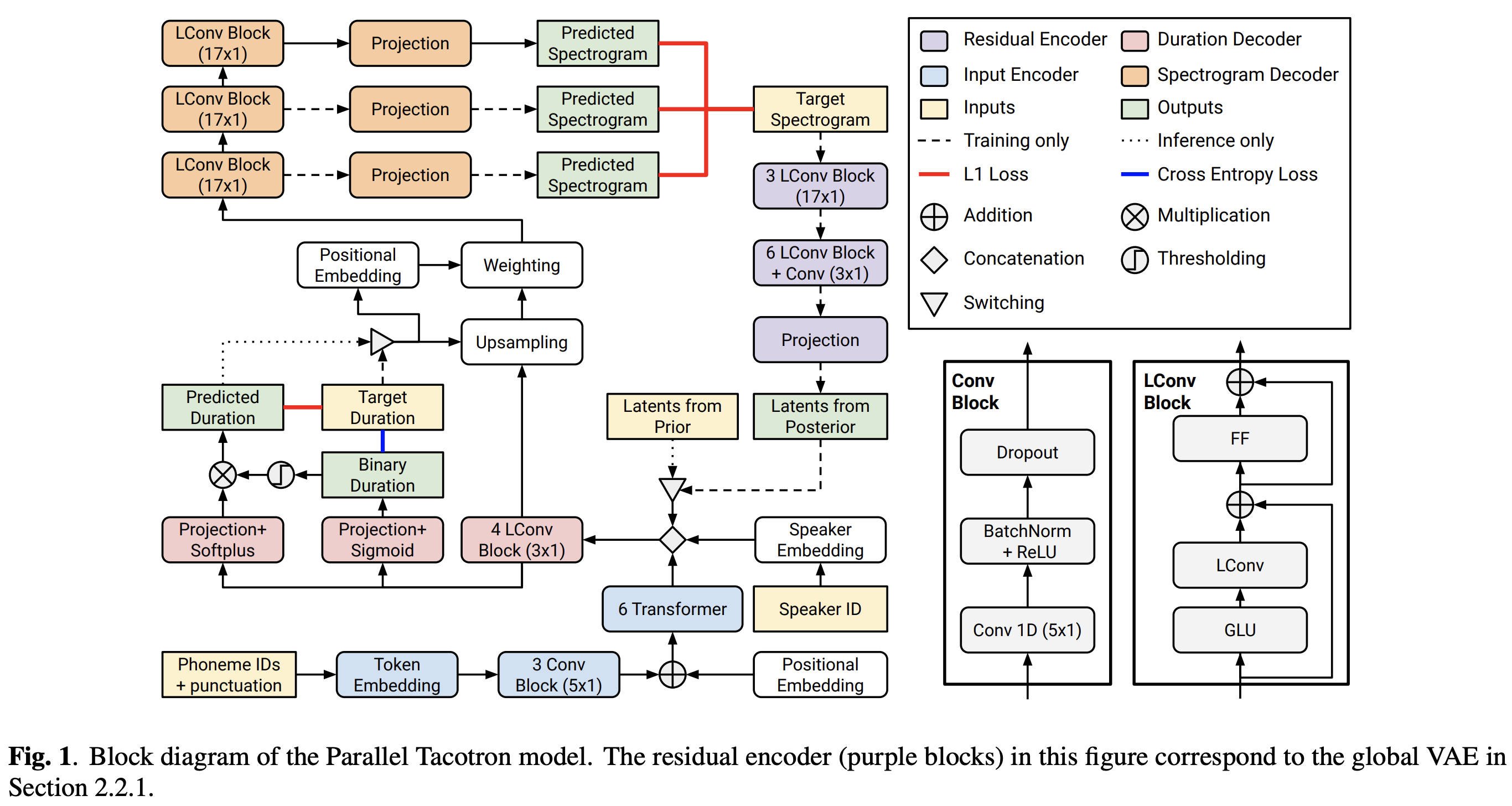
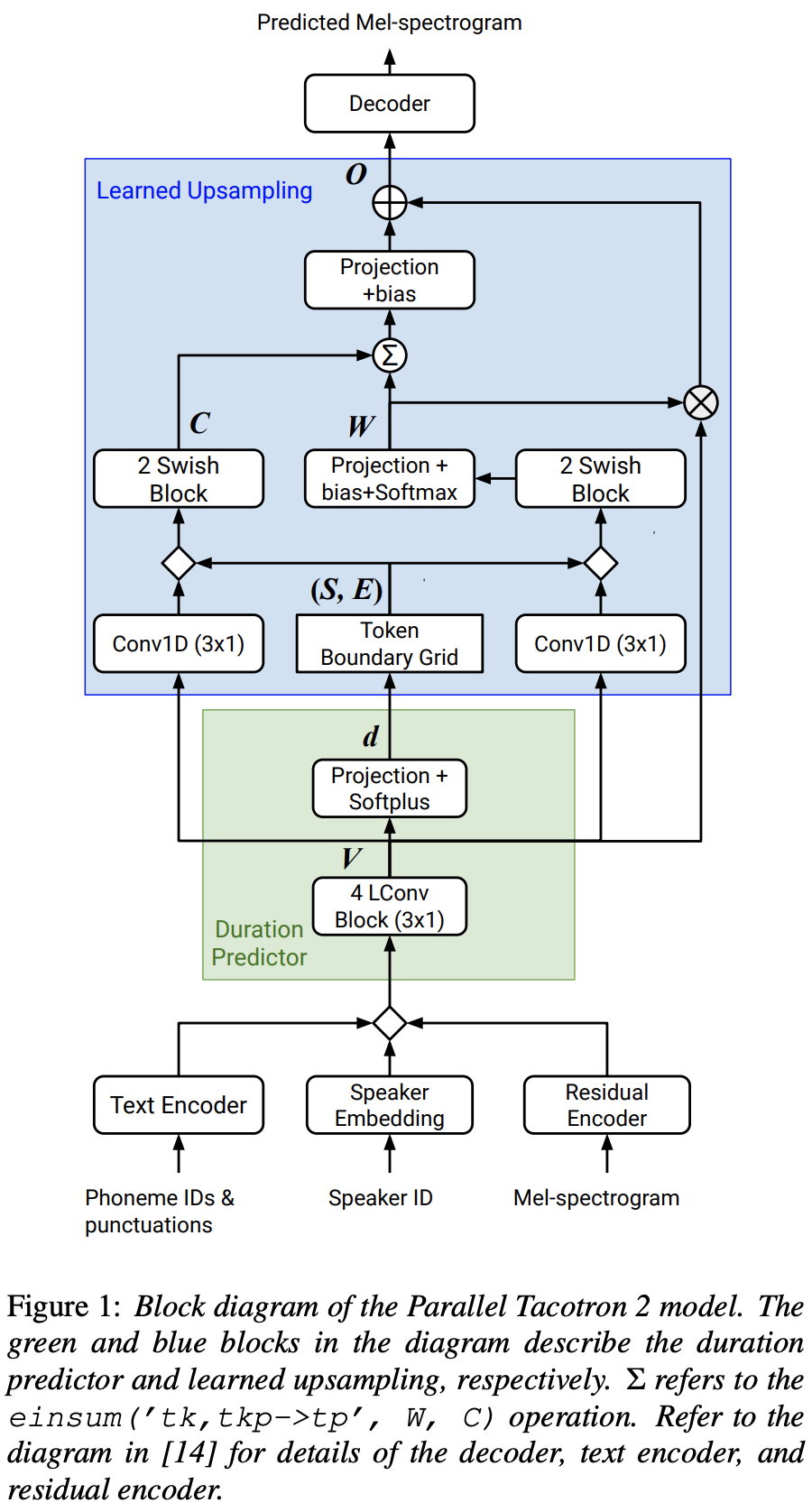
2021.05.25: Only the soft-DTW remains the last hurdle! Siguiendo el consejo del autor sobre la implementación, tomé varias pruebas en cada módulo una por una bajo una señal de duración supervisada con pérdida de L1 (FastSpeech2). Hasta ahora, puedo confirmar que todos los módulos, excepto Soft-DTW, funcionan bien de la siguiente manera (espectrograma sintetizado, espectrograma GT, alineación residual y W de Learnupsampling de arriba a abajo).
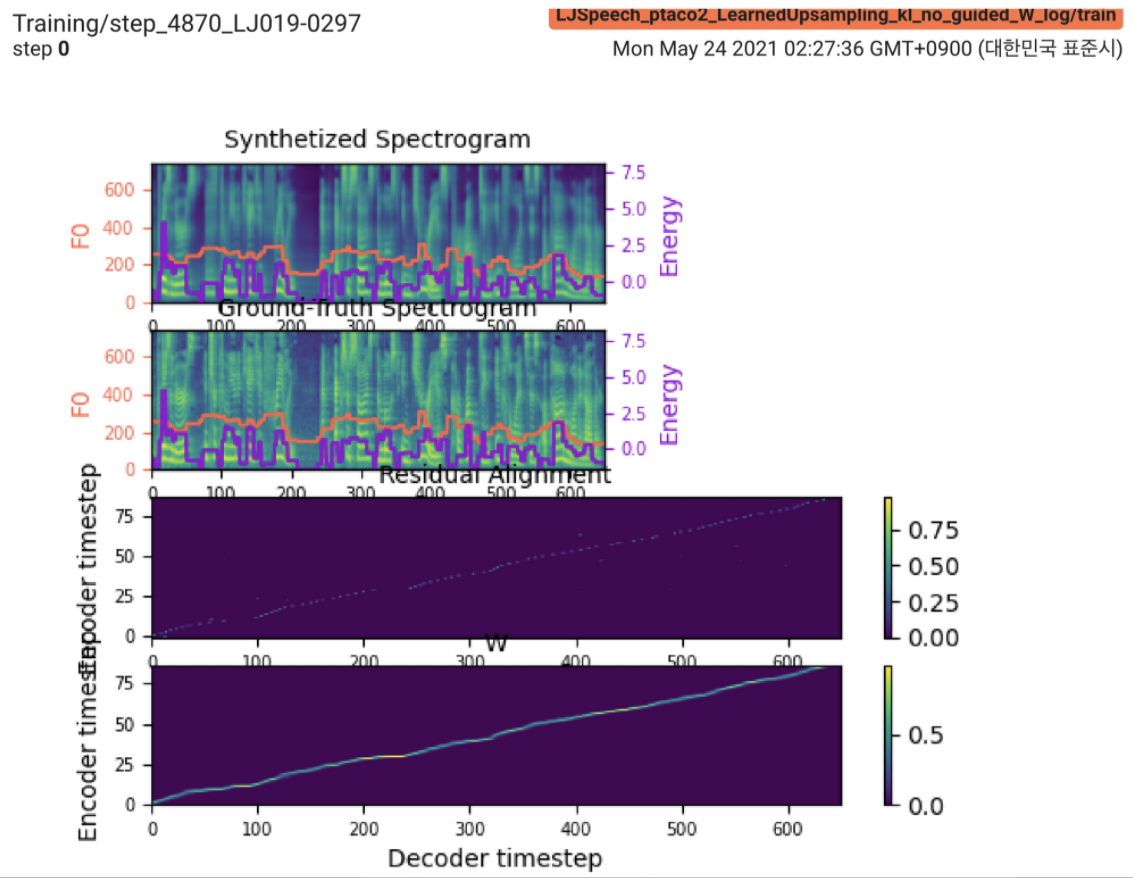
Para ver los detalles, consulte el último registro de confirmación y la sección de problemas de implementación actualizados. Además, puede encontrar los experimentos en curso en https://github.com/keonlee9420/fastspeech2/commits/ptaco2.
2021.05.15: Implementación realizada. Verificación de la cordura en la capacitación e inferencia. Pero aún así el modelo no puede converger.
I'm waiting for your contribution! Infórmeme si encuentra algún error en mi implementación o algún consejo valioso para capacitar al modelo con éxito. Consulte la sección Problemas de implementación.
Puede instalar las dependencias de Python con
pip3 install -r requirements.txt Instale Fairseq (documento oficial, GitHub) para utilizar LConvBlock . Verifique el n. ° 5 para resolver cualquier problema en la instalación.
Los conjuntos de datos compatibles:
Después de descargar los conjuntos de datos, configure el corpus_path en preprocess.yaml y ejecute el script de preparación:
python3 prepare_data.py config/LJSpeech/preprocess.yaml
Luego, ejecute el script de preprocesamiento:
python3 preprocess.py config/LJSpeech/preprocess.yaml
Entrena tu modelo con
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
El modelo aún no puede converger. ¡Estoy depurando, pero se aumentaría si tu increíble contribución está lista!
Para una sola inferencia, ejecute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 900000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Las expresiones generadas se guardarán en output/result/ .
También es compatible con la inferencia por lotes, intente
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step 900000 --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Para sintetizar todas las expresiones en preprocessed_data/LJSpeech/val.txt .
Usar
tensorboard --logdir output/log/LJSpeech
para servir tensorboard en su localhost.
En general, la normalización o la activación, que no se sugiere en el documento original, está adecuadamente dispuesto para evitar el valor de NAN (gradiente) en los cálculos hacia adelante y hacia atrás. (Nan indica que algo está mal en la red)
FFTBlock de FastSpeech2 para el bloque de transformador del codificador de texto.0.2 para el ConvBlock del codificador de texto.grapheme_to_phoneme . (Ver ./text/ init ). 80 channels de espectrogromo MEL en lugar de 128-bin .nn.SiLU() para la activación swish.W y C , la operación de concatenación se aplica entre S , E y V después del dominio del marco (dominio t) de transmisión de V . LConvBlock y una incrustación posicional sinusoidal regular.nn.Tanh() a cada salida LConvBLock (después del patrón de activación de la parte del decodificador en FastSpeech2). model/soft_dtw_cuda.py , reflejando la recursión sugerida en el documento original.E se calcula. Pero empleado como una función de pérdida, se agrega producto jacobiano para devolver el derivado del objetivo de la entrada R WRT X .8 en 24GIB GPU (Titan RTX) debido al problema de complejidad del espacio en la pérdida de DTW blando. @misc{lee2021parallel_tacotron2,
author = {Lee, Keon},
title = {Parallel-Tacotron2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Parallel-Tacotron2}}
}


