Parallel Tacotron2
1.0.0
Реализация Pytorch Parallel Tacotron 2: неавторегрессивная модель нейронной TTS с дифференцируемой моделированием продолжительности
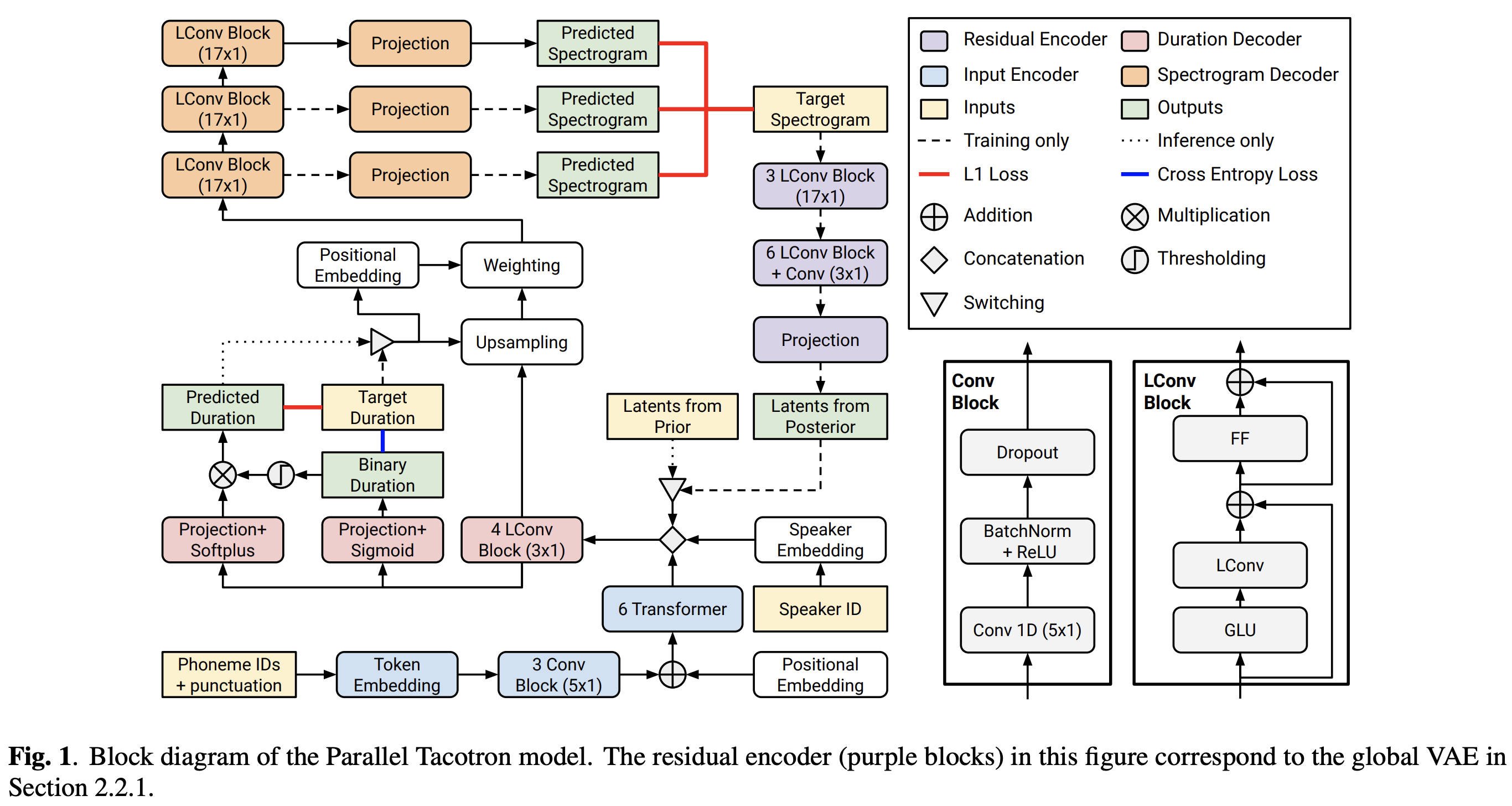
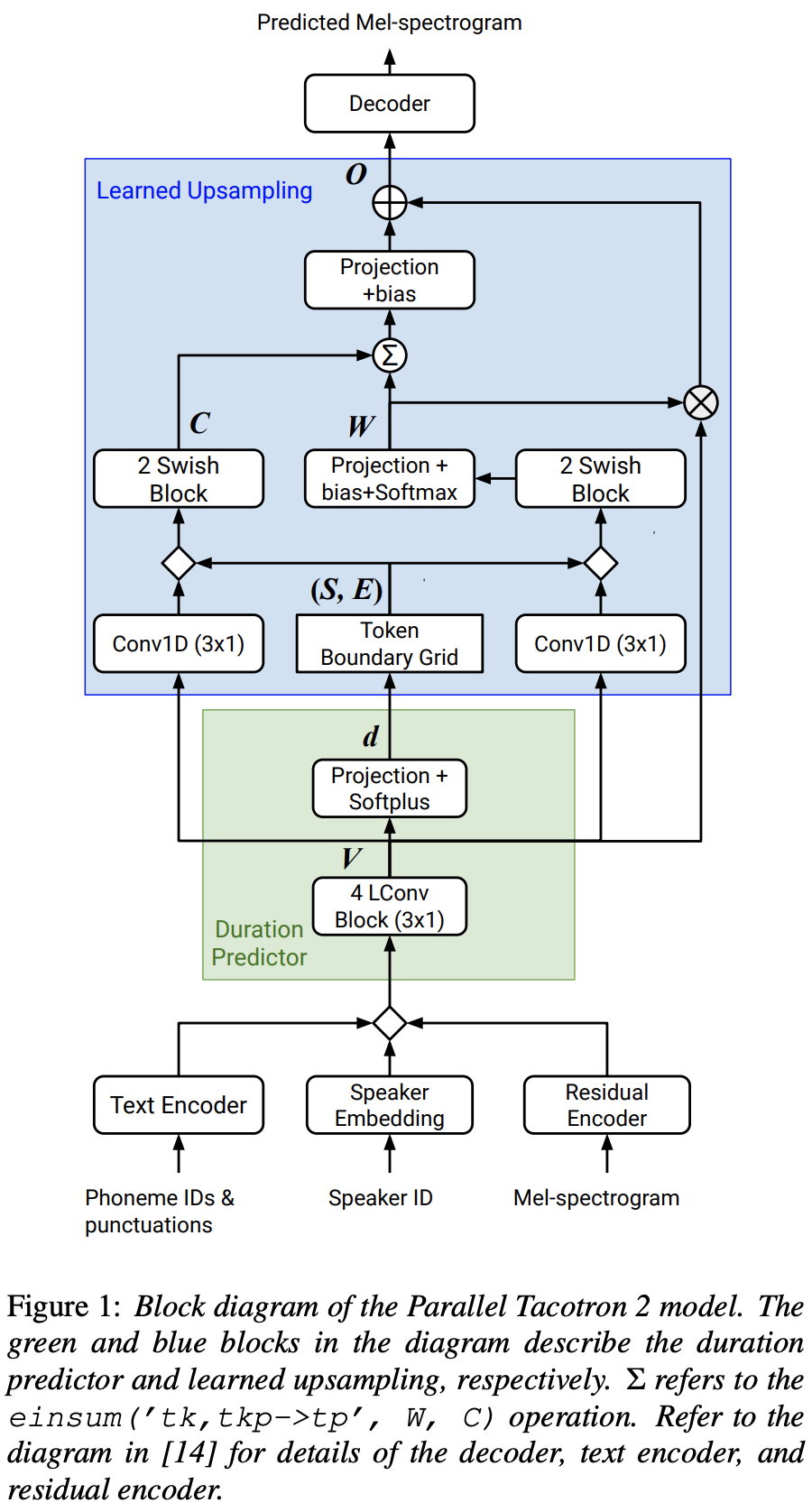
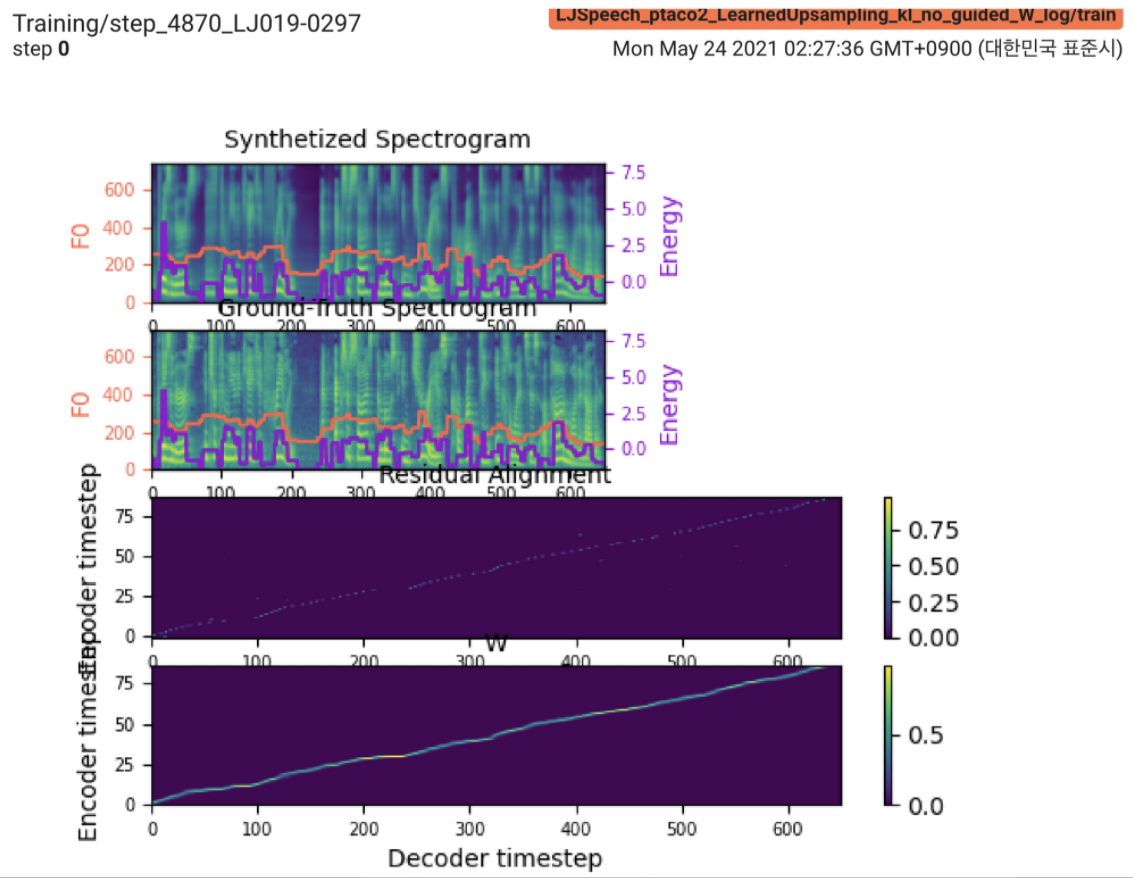
2021.05.25: Only the soft-DTW remains the last hurdle! Следуя совету автора по реализации, я провел несколько тестов на каждом модуле один за другим под контролируемым сигналом продолжительности с потерей L1 (Fastspeech2). До сих пор я могу подтвердить, что все модули, кроме Soft-DTW, работают хорошо следующим образом (синтезированная спектрограмма, спектрограмма GT, остаточное выравнивание и W от изучаемой Upsampling сверху вниз).
Для получения информации, пожалуйста, проверьте последний журнал коммит и раздел «Обновленные проблемы реализации». Кроме того, вы можете найти текущие эксперименты по адресу https://github.com/keonlee9420/fastspeech2/commits/ptaco2.
2021.05.15: реализация выполнена. Значительные проверки на обучение и вывод. Но все же модель не может сходиться.
I'm waiting for your contribution! Пожалуйста, сообщите мне, если вы найдете какие -либо ошибки в моей реализации или какие -либо ценные советы для успешного обучения модели. См. Раздел «Вопросы реализации».
Вы можете установить зависимости Python с
pip3 install -r requirements.txt Установите Fairseq (официальный документ, GitHub), чтобы использовать LConvBlock . Пожалуйста, проверьте #5, чтобы решить любую проблему при установке.
Поддерживаемые наборы данных:
После загрузки наборов данных установите corpus_path в preprocess.yaml и запустите скрипт подготовки:
python3 prepare_data.py config/LJSpeech/preprocess.yaml
Затем запустите сценарий предварительной обработки:
python3 preprocess.py config/LJSpeech/preprocess.yaml
Тренировать свою модель с
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Модель еще не может сходиться. Я отлаживаю, но это было бы повышено, если ваш потрясающий вклад будет готов!
Для единого вывода, запустите
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 900000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Сгенерированные высказывания будут сохранены в output/result/ .
Пакетный вывод также поддерживается, попробуйте
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step 900000 --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
синтезировать все высказывания в preprocessed_data/LJSpeech/val.txt .
Использовать
tensorboard --logdir output/log/LJSpeech
Подавать в Tensorboard на вашем местном хосте.
В целом, нормализация или активация, которая не предложена в исходной статье, адекватно расположена для предотвращения значения NAN (градиент) на прямом и обратном расчетах. (Нан указывает, что в сети что -то не так)
FFTBlock of Fastspeech2 для блока трансформатора текстового энкодера.0.2 для ConvBlock текстового энкодера.grapheme_to_phoneme . (См. ./Text/ init ). 80 channels Mel-Spectrogrom вместо 128-bin .nn.SiLU() для активации SWISH.W и C операция конкатенации применяется между S , E и V после вещания V-домен (T-домен) V LConvBlock и регулярное синусоидальное позиционное внедрение.nn.Tanh() к каждому выходу LConvBLock (после шаблона активации части декодера в Fastspeech2). model/soft_dtw_cuda.py , отражая рекурсию, предложенную в исходной статье.E Но используется в качестве функции убытки, якобианский продукт добавляется для возврата целевого производного от R wrt input X .8 в 24-г-на графическом процессоре (Titan RTX) из-за проблемы сложности пространства при потери Soft-DTW. @misc{lee2021parallel_tacotron2,
author = {Lee, Keon},
title = {Parallel-Tacotron2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Parallel-Tacotron2}}
}


