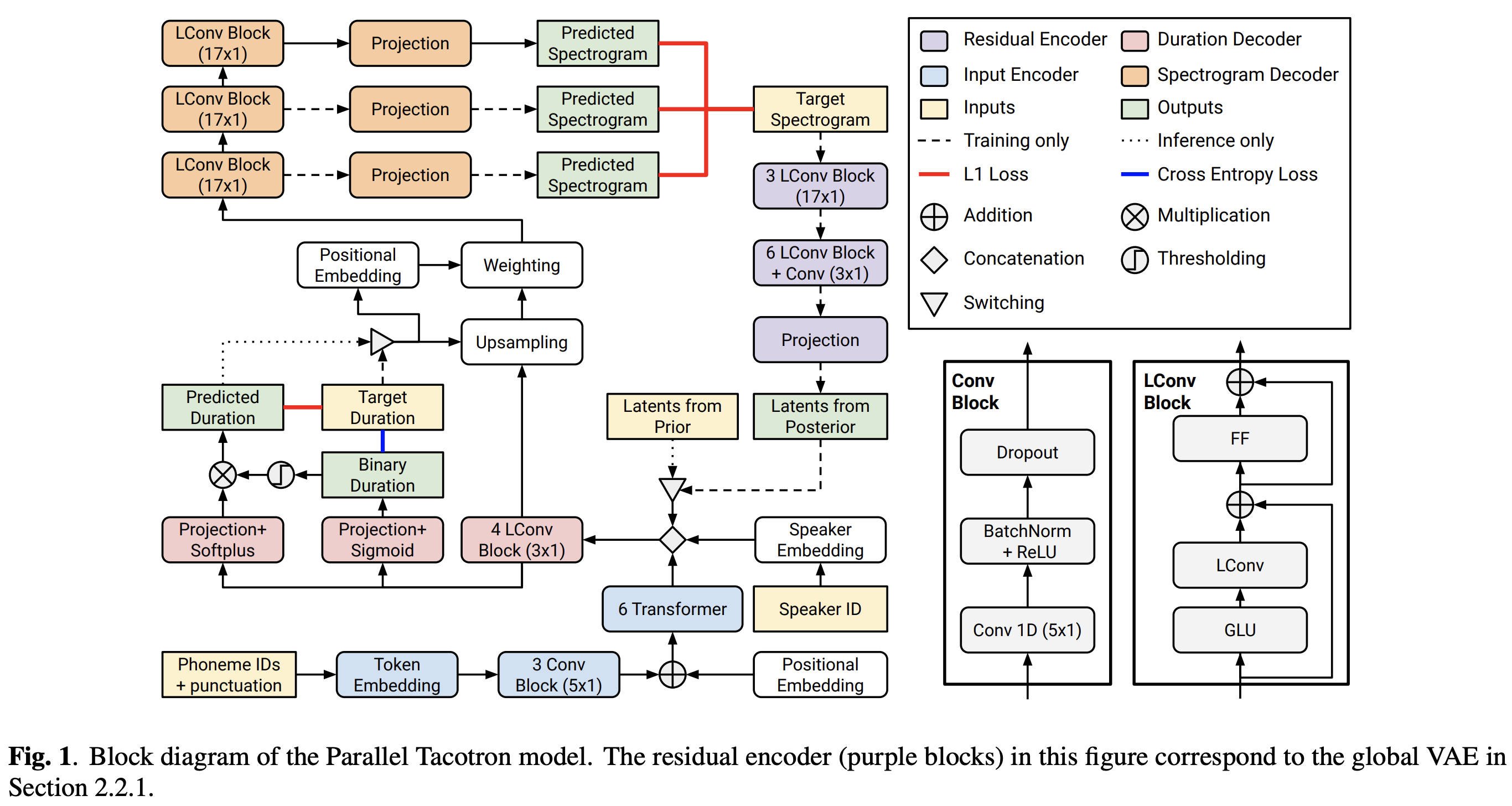
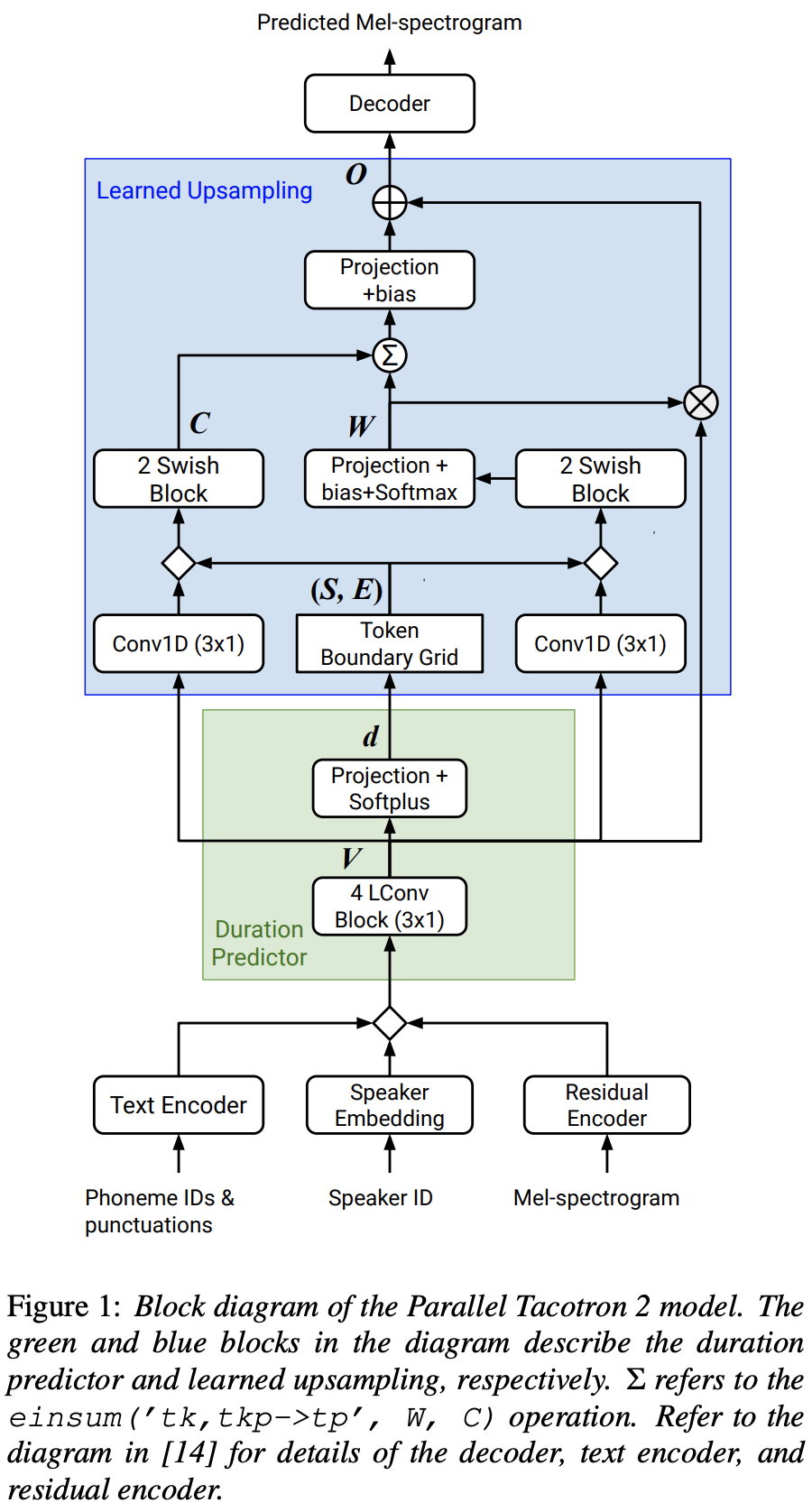
Parallel Tacotron2
1.0.0
Implementasi Pytorch dari Google Paralel Tacotron 2: Model TTS Neural Non-Autoregressive dengan pemodelan durasi yang dapat dibedakan
2021.05.25: Only the soft-DTW remains the last hurdle! Mengikuti saran penulis tentang implementasi, saya mengambil beberapa tes pada setiap modul satu per satu di bawah sinyal durasi yang diawasi dengan kehilangan L1 (FastSpeech2). Sampai sekarang, saya dapat mengonfirmasi bahwa semua modul kecuali Soft-DTW berfungsi dengan baik sebagai berikut (spektrogram yang disintesis, spektrogram GT, penyelarasan residual, dan W dari unggulan yang dipelajari dari atas ke bawah).
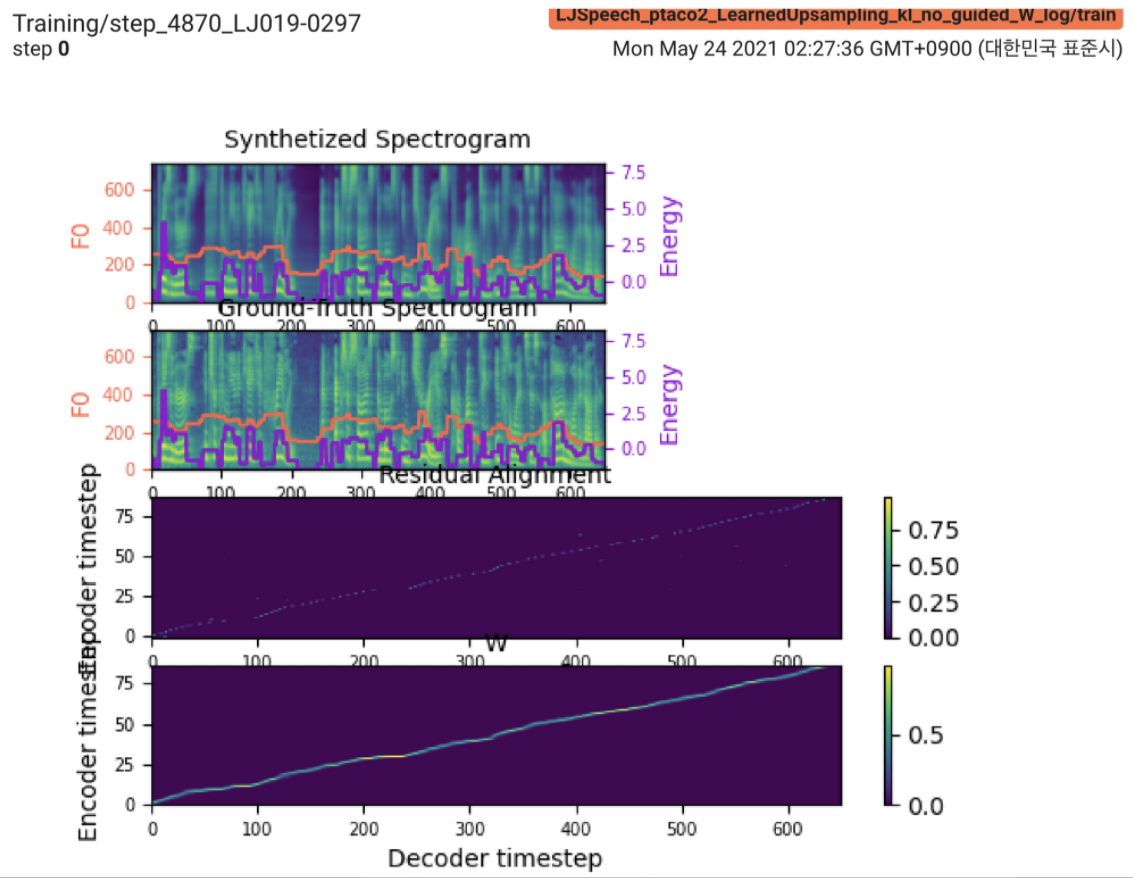
Untuk detailnya, silakan periksa log komit terbaru dan bagian masalah implementasi yang diperbarui. Anda juga dapat menemukan percobaan yang sedang berlangsung di https://github.com/keonlee9420/fastspeech2/commits/ptaco2.
2021.05.15: Implementasi dilakukan. Pemeriksaan kewarasan tentang pelatihan dan kesimpulan. Tapi tetap saja modelnya tidak bisa bertemu.
I'm waiting for your contribution! Harap beri tahu saya jika Anda menemukan kesalahan dalam implementasi saya atau saran berharga untuk melatih model dengan sukses. Lihat bagian Masalah Implementasi.
Anda dapat menginstal dependensi Python dengan
pip3 install -r requirements.txt Instal Fairseq (Dokumen Resmi, GitHub) untuk memanfaatkan LConvBlock . Silakan periksa #5 untuk menyelesaikan masalah apa pun saat menginstal.
Dataset yang didukung:
Setelah mengunduh dataset, atur corpus_path di preprocess.yaml dan jalankan skrip persiapan:
python3 prepare_data.py config/LJSpeech/preprocess.yaml
Kemudian, jalankan skrip preprocessing:
python3 preprocess.py config/LJSpeech/preprocess.yaml
Latih model Anda dengan
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Model belum bisa bertemu. Saya debugging tetapi akan ditingkatkan jika kontribusi Anda yang luar biasa siap!
Untuk satu kesimpulan, jalankan
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 900000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Ucapan yang dihasilkan akan disimpan dalam output/result/ .
Inferensi batch juga didukung, coba
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step 900000 --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Untuk mensintesis semua ucapan di preprocessed_data/LJSpeech/val.txt .
Menggunakan
tensorboard --logdir output/log/LJSpeech
untuk melayani Tensorboard di Localhost Anda.
Secara keseluruhan, normalisasi atau aktivasi, yang tidak disarankan dalam kertas asli, diatur secara memadai untuk mencegah nilai NAN (gradien) pada perhitungan ke depan dan ke belakang. (NAN menunjukkan bahwa ada sesuatu yang salah dalam jaringan)
FFTBlock fastspeech2 untuk blok transformator encoder teks.0.2 untuk ConvBlock encoder teks.grapheme_to_phoneme . (Lihat ./text/ init ). 80 channels Mel-Spectrogrom bukan 128-bin .nn.SiLU() untuk aktivasi swish.W dan C , operasi gabungan diterapkan di antara S , E , dan V setelah domain bingkai (domain T) dari V LConvBlock dan embedding posisi sinusoidal biasa.nn.Tanh() untuk setiap output LConvBLock (mengikuti pola aktivasi bagian dekoder di fastspeech2). model/soft_dtw_cuda.py , yang mencerminkan rekursi yang disarankan dalam kertas asli.E yang dihitung. Tetapi dipekerjakan sebagai fungsi kerugian, produk Jacobian ditambahkan untuk mengembalikan target target input R WRT X .8 dalam 24Gib GPU (Titan RTX) karena masalah kompleksitas ruang dalam kehilangan-DTW soft-DTW. @misc{lee2021parallel_tacotron2,
author = {Lee, Keon},
title = {Parallel-Tacotron2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Parallel-Tacotron2}}
}


