Parallel Tacotron2
1.0.0
تنفيذ Pytorch من Google Tacotron 2: نموذج TTS العصبي غير التوت مع نمذجة مدة قابلة للتمييز
2021.05.25: Only the soft-DTW remains the last hurdle! بعد نصيحة المؤلف بشأن التنفيذ ، أجريت عدة اختبارات على كل وحدة واحدة تلو الأخرى تحت إشارة مدة خاضعة للإشراف مع فقدان L1 (Fastspeade2). حتى الآن ، يمكنني أن أؤكد أن جميع الوحدات باستثناء Soft-DTW تعمل بشكل جيد كما يلي (الطيف المركب ، طيفية GT ، المحاذاة المتبقية ، و W من existrupsampling من أعلى إلى أسفل).
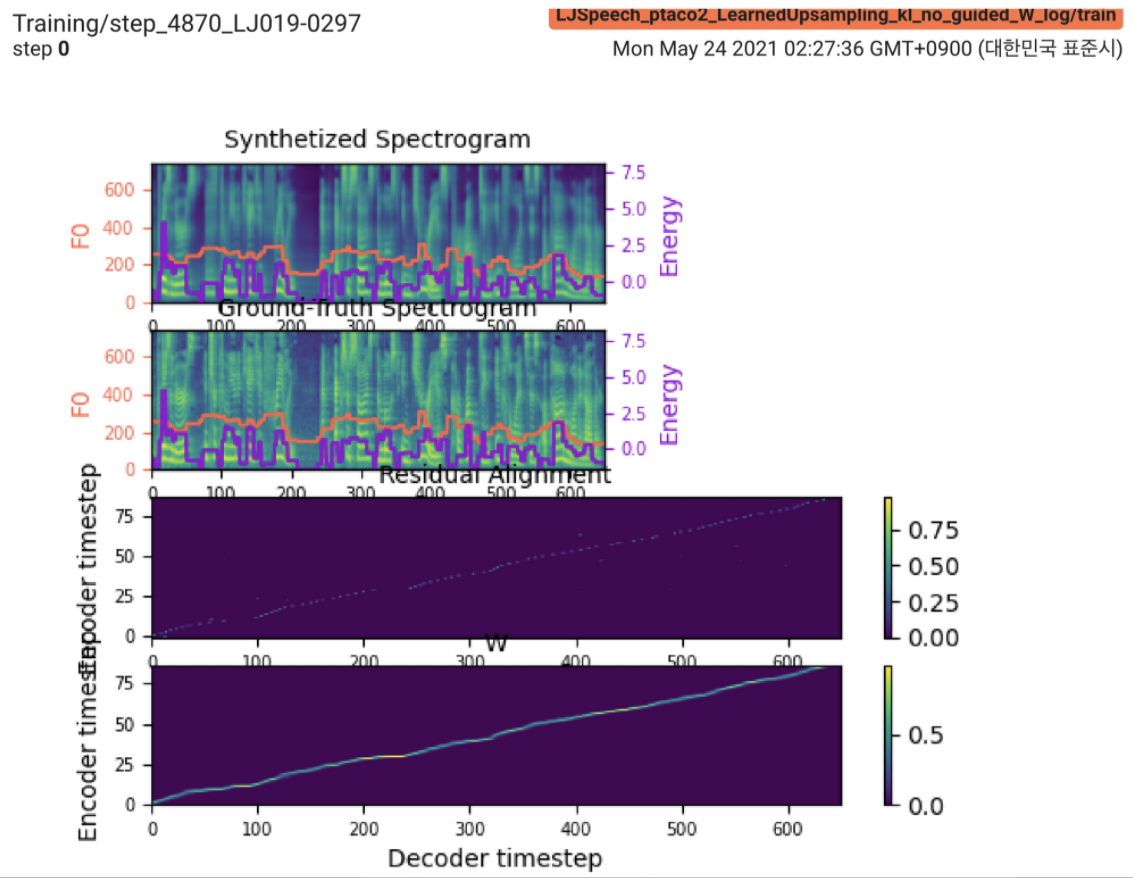
للحصول على التفاصيل ، يرجى التحقق من أحدث سجل الالتزام وقسم مشكلات التنفيذ المحدثة. أيضًا ، يمكنك العثور على التجارب المستمرة على https://github.com/keonlee9420/fastspeade2/commits/ptaco2.
2021.05.15: تنفيذ. العقلانية يتحقق من التدريب والاستدلال. ولكن لا يزال النموذج لا يمكن أن يتلاقى.
I'm waiting for your contribution! يرجى إبلاغي إذا وجدت أي أخطاء في تنفيذي أو أي نصيحة قيمة لتدريب النموذج بنجاح. انظر قسم قضايا التنفيذ.
يمكنك تثبيت تبعيات Python مع
pip3 install -r requirements.txt قم بتثبيت FairSeq (المستند الرسمي ، Github) لاستخدام LConvBlock . يرجى التحقق من #5 لحل أي مشكلة عند التثبيت.
مجموعات البيانات المدعومة:
بعد تنزيل مجموعات البيانات ، قم بتعيين corpus_path في preprocess.yaml وقم بتشغيل برنامج التحضير:
python3 prepare_data.py config/LJSpeech/preprocess.yaml
ثم ، قم بتشغيل البرنامج النصي المسبق:
python3 preprocess.py config/LJSpeech/preprocess.yaml
تدريب النموذج الخاص بك مع
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
لا يمكن أن يتقارب النموذج بعد. أنا أخطئ في التصحيح ولكن سيتم تعزيزه إذا كانت مساهمتك الرائعة جاهزة!
لاستنتاج واحد ، قم بالتشغيل
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 900000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
سيتم حفظ الكلمات المولدة في output/result/ .
يتم دعم استنتاج الدُفعات أيضًا ، حاول
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step 900000 --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
لتوليف جميع الكلمات في preprocessed_data/LJSpeech/val.txt .
يستخدم
tensorboard --logdir output/log/LJSpeech
لخدمة Tensorboard على مضيفك المحلي.
بشكل عام ، يتم ترتيب التطبيع أو التنشيط ، الذي لا يتم اقتراحه في الورقة الأصلية ، بشكل كاف لمنع قيمة NAN (التدرج) على الحسابات الأمامية والخلف. (تشير نان إلى أن هناك خطأ ما في الشبكة)
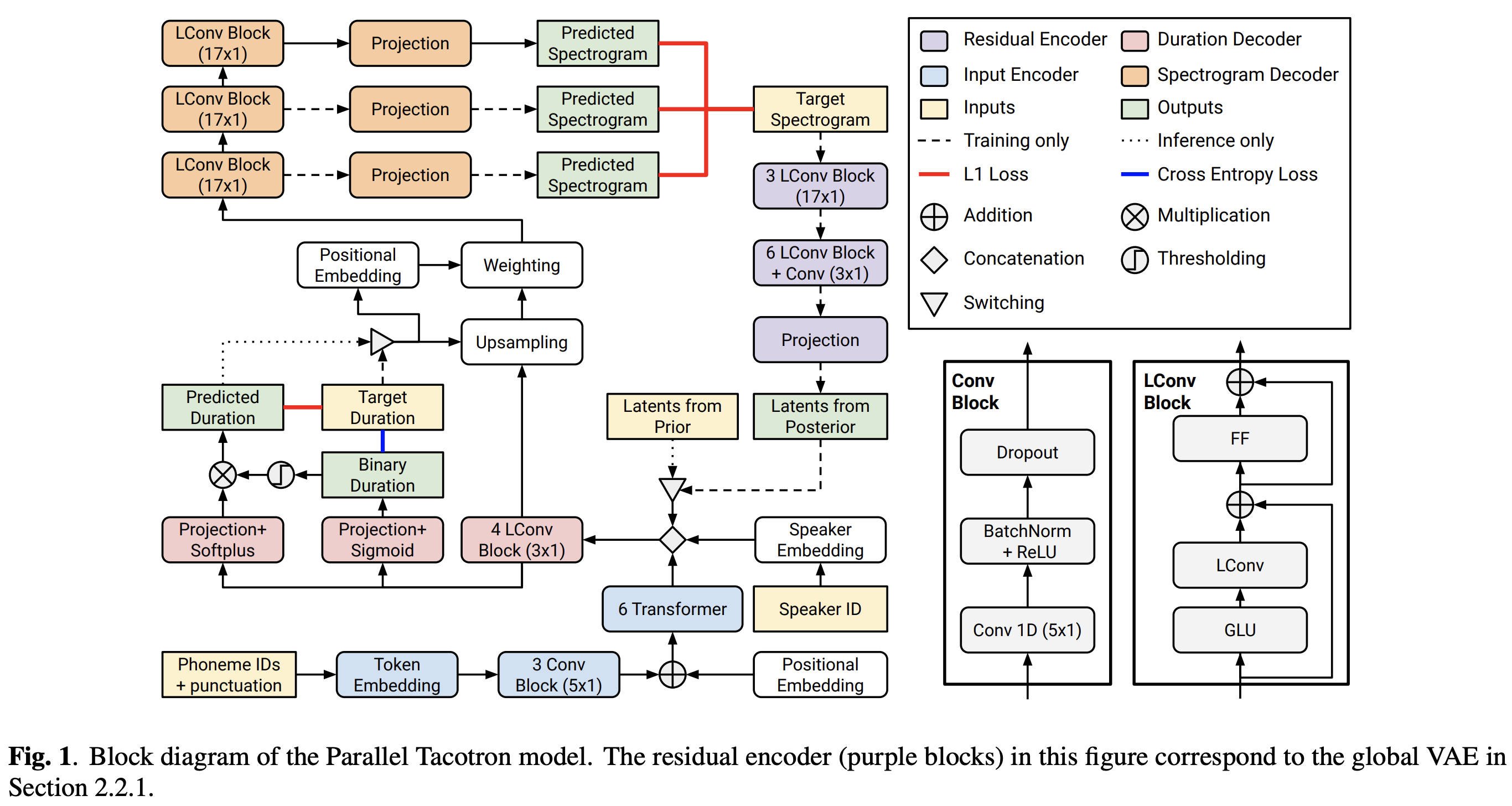
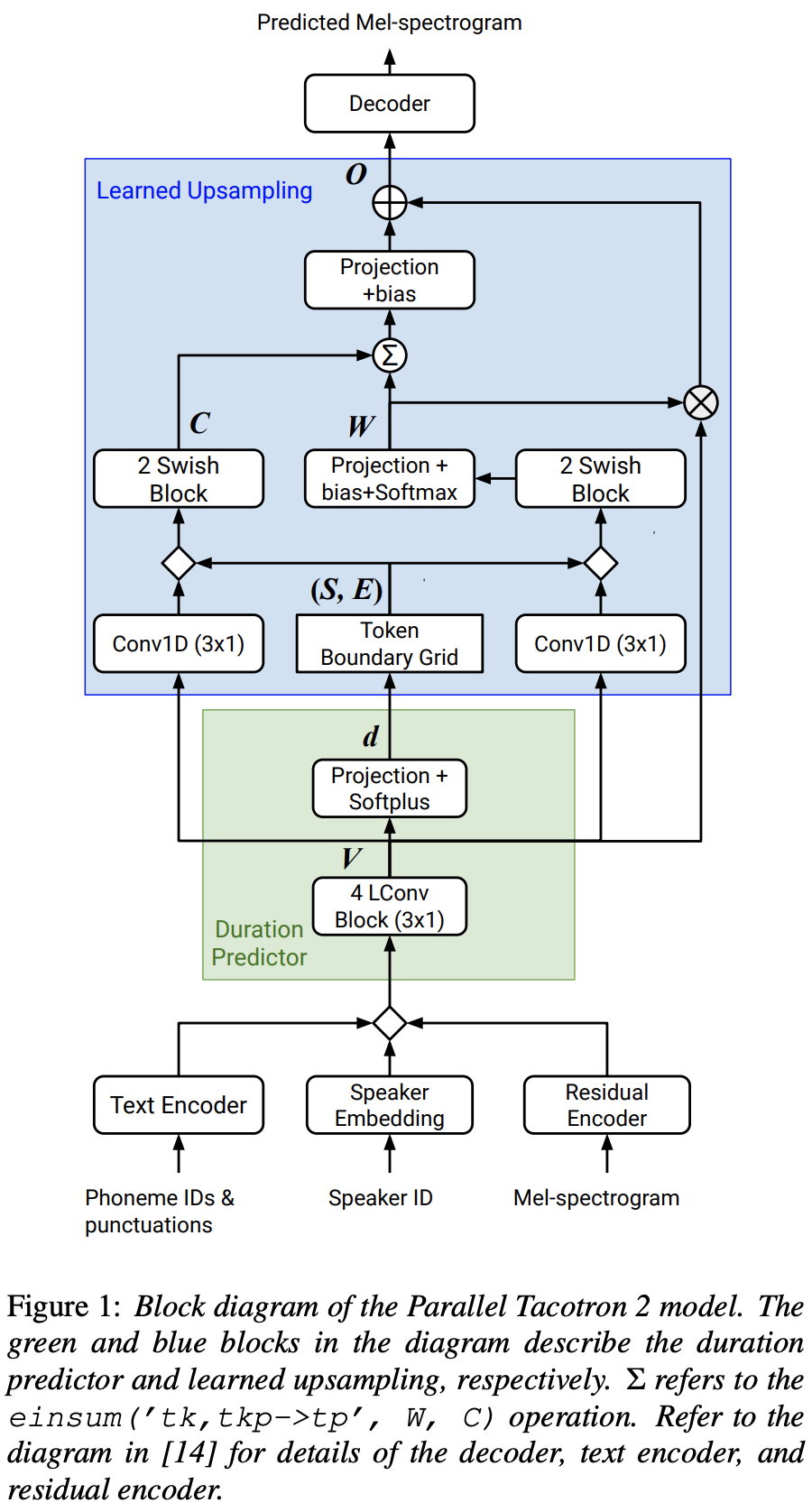
FFTBlock من fastspeade2 لكتلة المحولات من تشفير النص.0.2 ل ConvBlock من تشفير النص.grapheme_to_phoneme . (انظر ./text/ init ). 80 channels Mel-spectrogrom بدلاً من 128-bin .nn.SiLU() لتفعيل Swish.W و C ، يتم تطبيق عملية التسلسل بين S و E و V بعد إطار المجال (المجال T) من V LConvBlock والتضمين الموضعية الجيبية العادية.nn.Tanh() على كل إخراج LConvBLock (بعد نمط التنشيط لجزء وحدة فك الترميز في Fastspeech2). model/soft_dtw_cuda.py ، مما يعكس العودية المقترحة في الورقة الأصلية.E فقط. ولكن يتم استخدامه كدالة خسارة ، يتم إضافة منتج يعقوبي لإرجاع المشتق المستهدف من إدخال R WRT X8 في GPU 24GIB (TITAN RTX) بسبب مشكلة تعقيد الفضاء في فقدان SOFT-DTW. @misc{lee2021parallel_tacotron2,
author = {Lee, Keon},
title = {Parallel-Tacotron2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Parallel-Tacotron2}}
}


