Parallel Tacotron2
1.0.0
Pytorch Implémentation du Tacotron parallèle de Google 2: un modèle TTS neuronal non autorégressif avec modélisation de durée différenciable
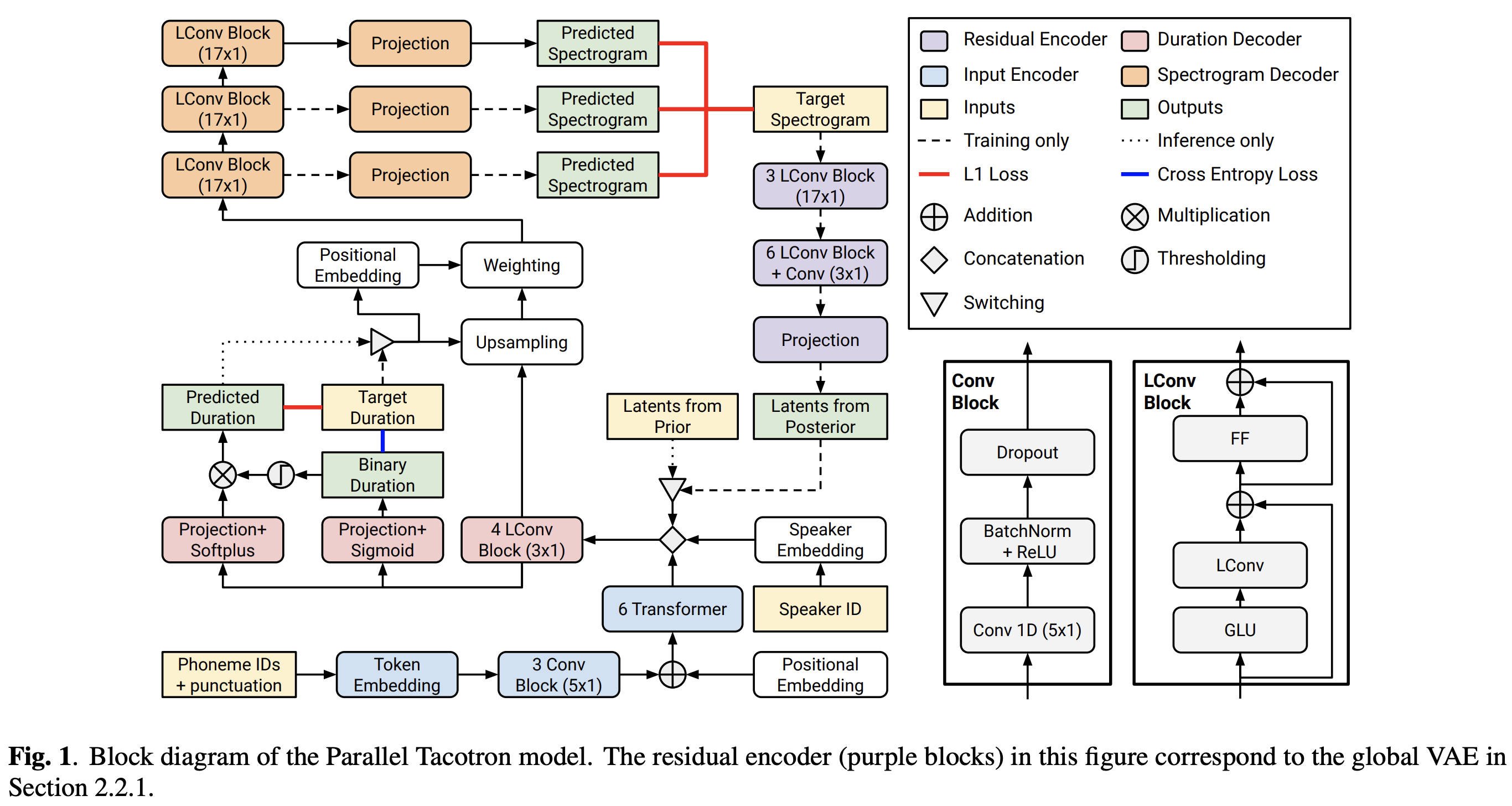
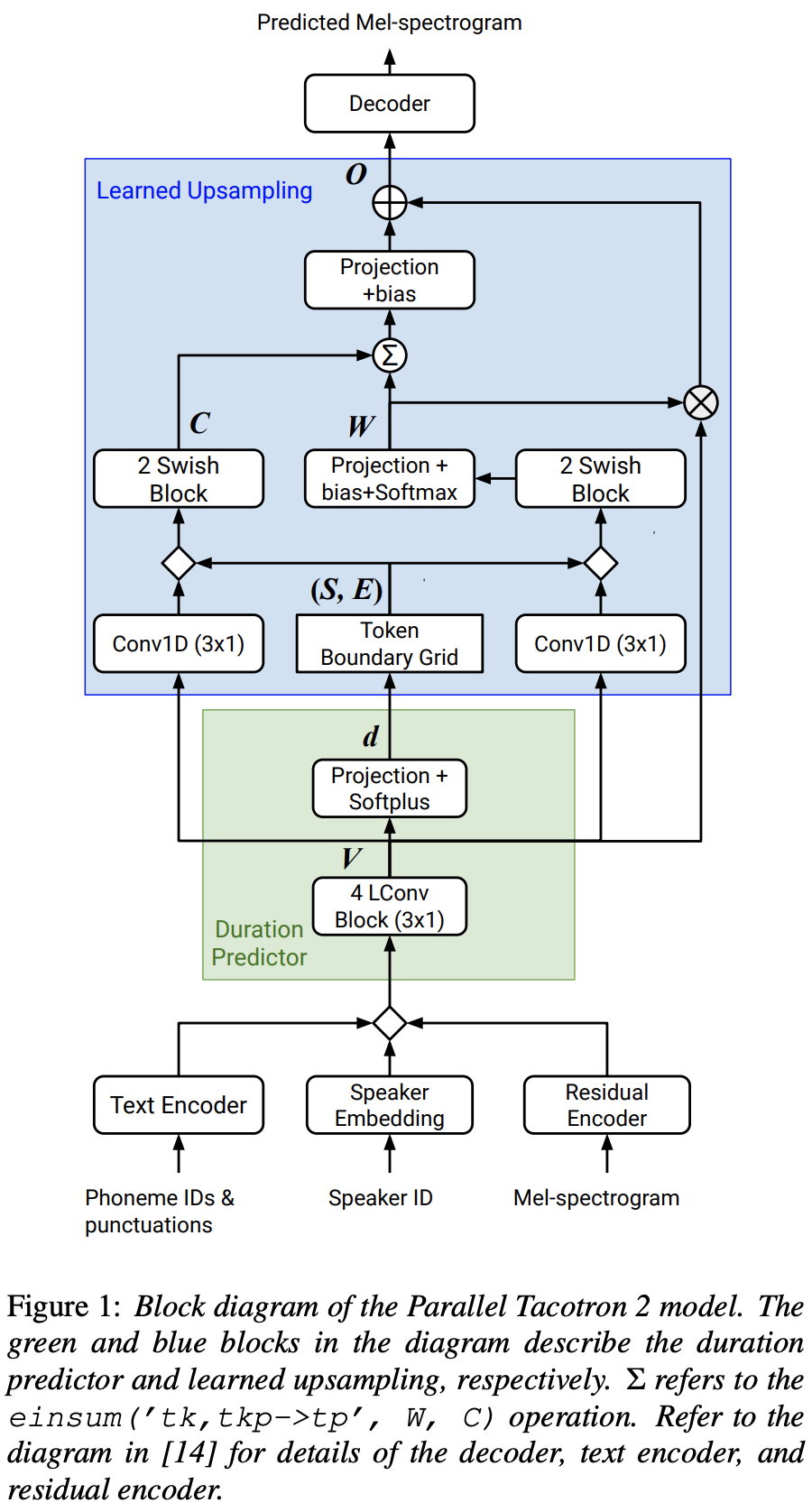
2021.05.25: Only the soft-DTW remains the last hurdle! Suite aux conseils de l'auteur sur la mise en œuvre, j'ai passé plusieurs tests sur chaque module un par un sous un signal de durée supervisé avec L1 Loss (FastSpeech2). Jusqu'à présent, je peux confirmer que tous les modules sauf Soft-DTW fonctionnent bien comme suit (spectrogramme synthétisé, spectrogramme GT, alignement résiduel et W de l'échantillonnage d'apprentissage de haut en bas).
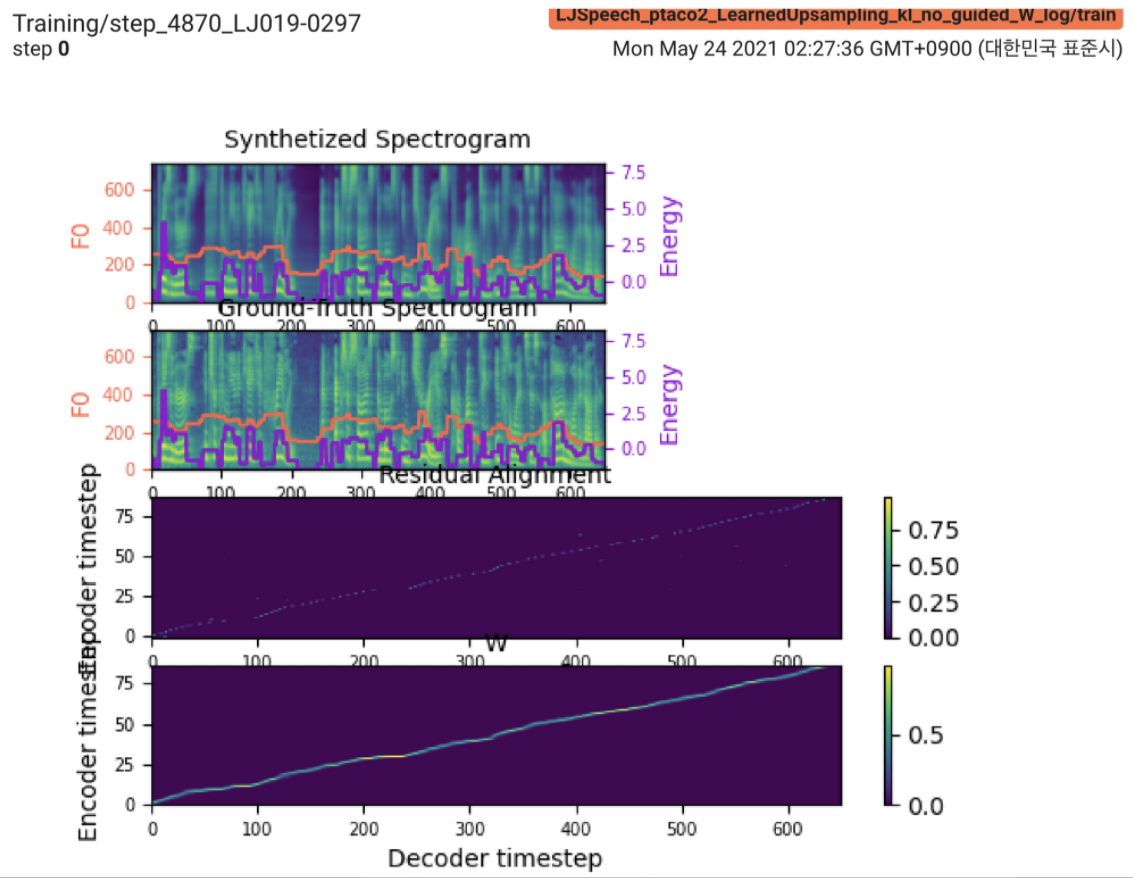
Pour les détails, veuillez consulter le dernier journal de validation et la section des problèmes d'implémentation mis à jour. En outre, vous pouvez trouver les expériences en cours sur https://github.com/keonlee9420/fastSpeech2/commits/ptaco2.
2021.05.15: Implémentation effectuée. Vérification de la santé mentale sur la formation et l'inférence. Mais le modèle ne peut toujours pas converger.
I'm waiting for your contribution! Veuillez m'informer si vous trouvez des erreurs dans ma mise en œuvre ou des conseils précieux pour former le modèle avec succès. Voir la section des problèmes de mise en œuvre.
Vous pouvez installer les dépendances Python avec
pip3 install -r requirements.txt Installez Fairseq (document officiel, GitHub) pour utiliser LConvBlock . Veuillez vérifier le n ° 5 pour résoudre tout problème lors de l'installation.
Les ensembles de données pris en charge:
Après avoir téléchargé les ensembles de données, définissez le corpus_path dans preprocess.yaml et exécutez le script de préparation:
python3 prepare_data.py config/LJSpeech/preprocess.yaml
Ensuite, exécutez le script de prétraitement:
python3 preprocess.py config/LJSpeech/preprocess.yaml
Former votre modèle avec
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Le modèle ne peut pas encore converger. Je débogage mais ce serait stimulé si votre contribution impressionnante est prête!
Pour une seule inférence, courez
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 900000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Les énoncés générés seront enregistrés en output/result/ .
L'inférence par lots est également prise en charge, essayez
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step 900000 --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Pour synthétiser toutes les énoncés dans preprocessed_data/LJSpeech/val.txt .
Utiliser
tensorboard --logdir output/log/LJSpeech
pour servir Tensorboard sur votre hôte local.
Dans l'ensemble, la normalisation ou l'activation, qui n'est pas suggérée dans l'article d'origine, est correctement organisée pour empêcher la valeur NAN (gradient) sur les calculs avant et arrière. (Nan indique que quelque chose ne va pas dans le réseau)
FFTBlock de FASTSPEECH2 pour le bloc transformateur de l'encodeur de texte.0.2 pour le ConvBlock de l'encodeur de texte.grapheme_to_phoneme . (Voir ./text/ init ). 80 channels MEL-Spectrogrom au lieu de 128-bin .nn.SiLU() pour l'activation de swish.W et C , le fonctionnement de la concaténation est appliqué entre S , E et V après le domaine trame (domaine T) de V LConvBlock et l'intégration régulière de la position sinusoïdale.nn.Tanh() à chaque sortie LConvBLock (suivant le modèle d'activation de la partie du décodeur dans FastSpeech2). model/soft_dtw_cuda.py , reflétant la récursivité suggérée dans l'article d'origine.E est calculé. Mais employé comme fonction de perte, le produit jacobien est ajouté pour renvoyer la cible dérivée de l'entrée R WRT X .8 en GPU 24GIB (TITAN RTX) en raison du problème de complexité de l'espace dans la perte Soft-DTW. @misc{lee2021parallel_tacotron2,
author = {Lee, Keon},
title = {Parallel-Tacotron2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Parallel-Tacotron2}}
}


