Parallel Tacotron2
1.0.0
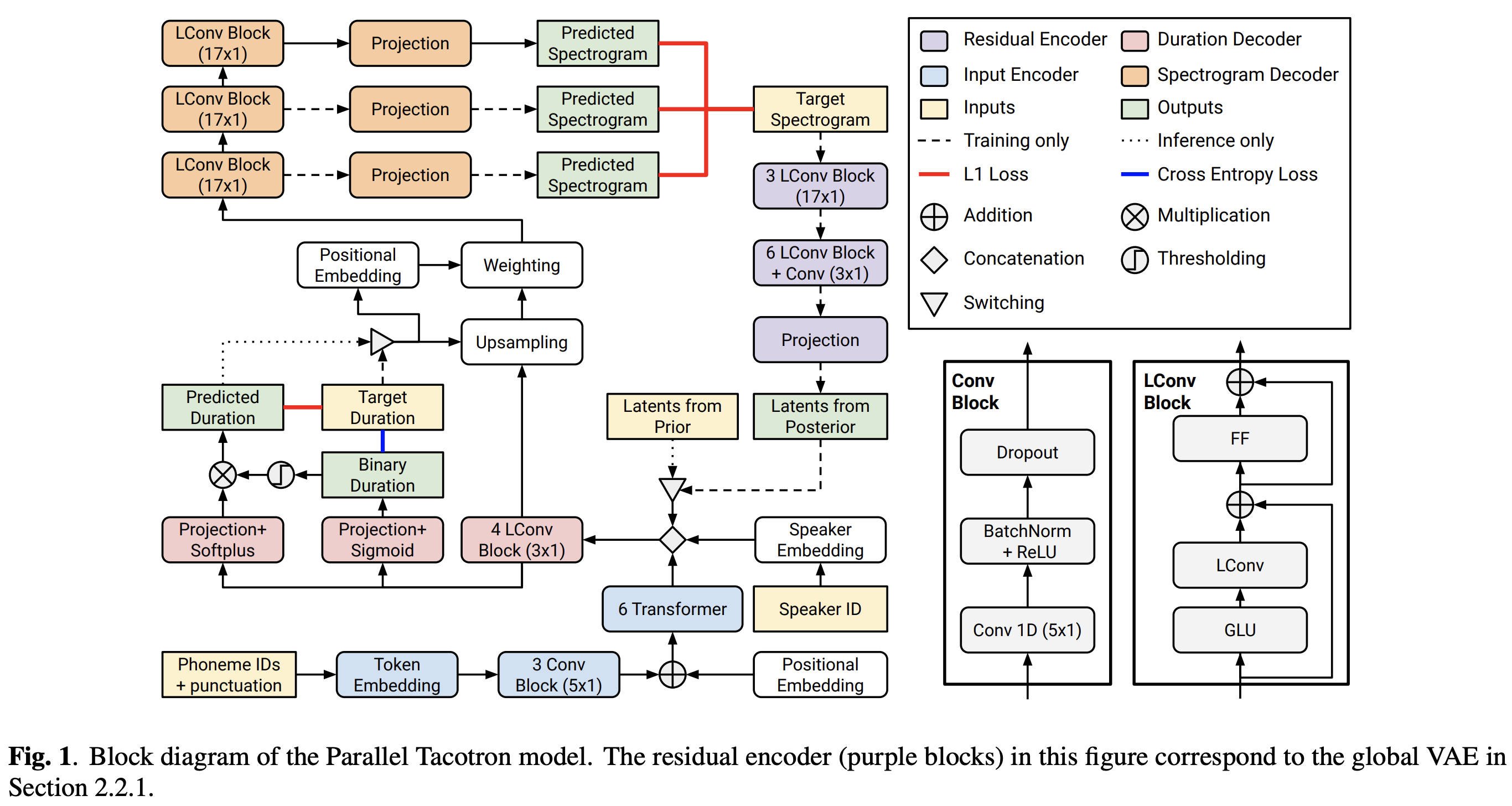
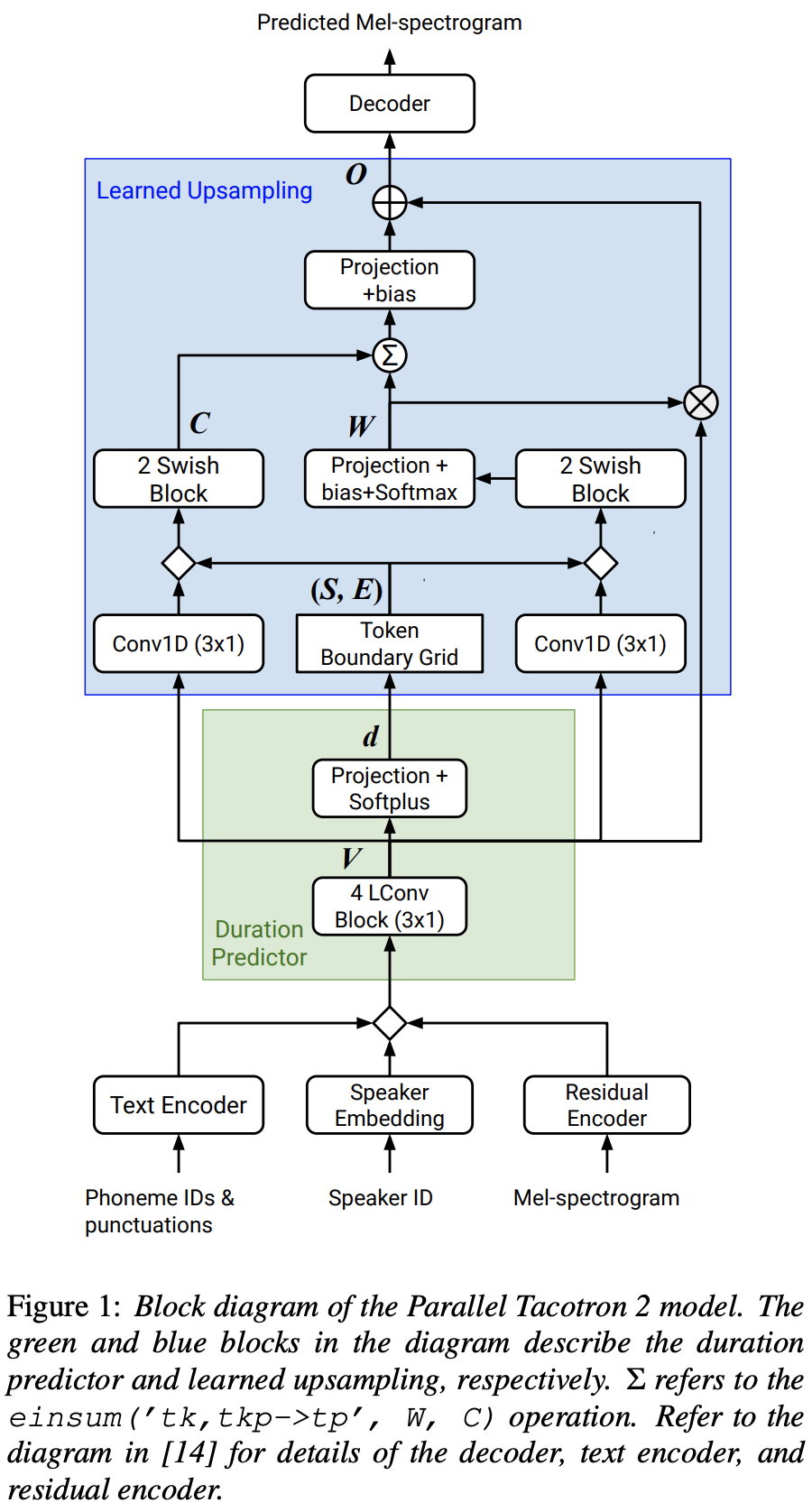
Google의 병렬 타코트론 2의 Pytorch 구현 : 차별화 가능한 지속 시간 모델링을 갖춘 비 유포적 신경 TTS 모델
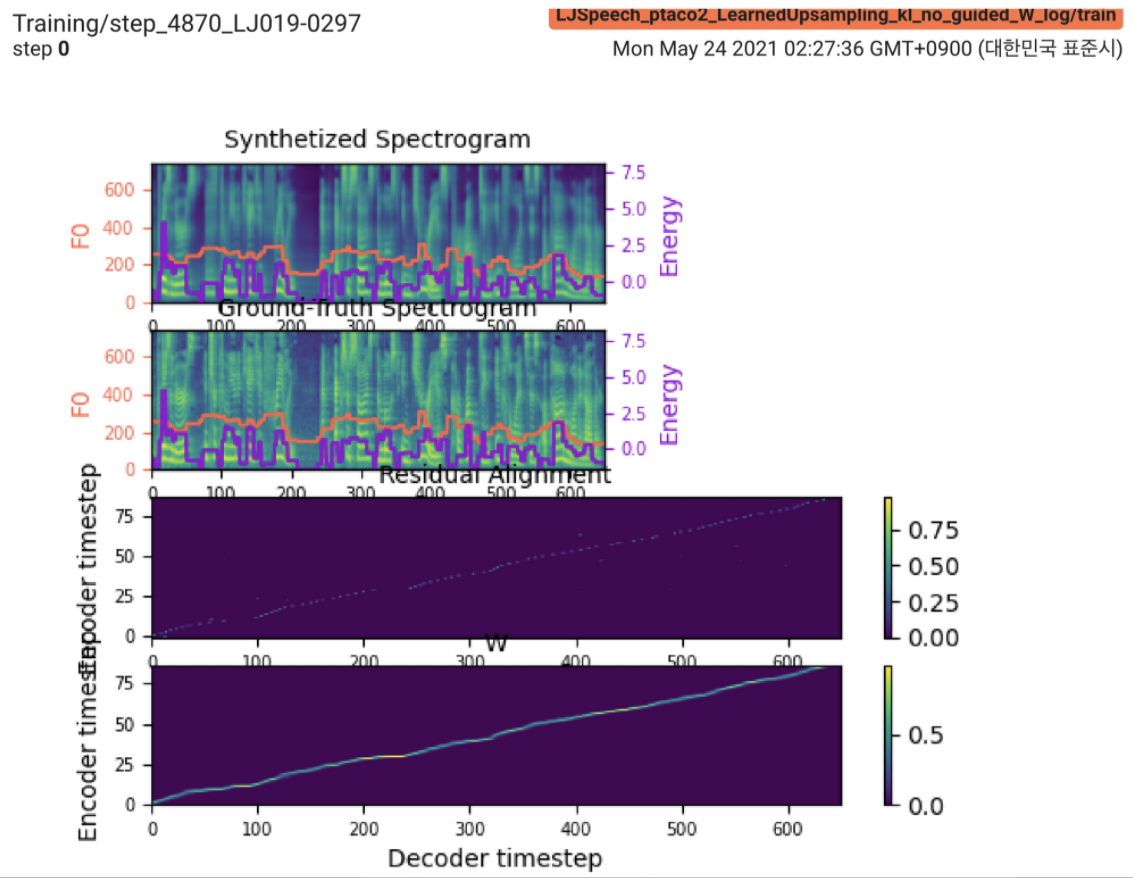
2021.05.25 : Only the soft-DTW remains the last hurdle! 구현에 대한 저자의 조언에 따라 L1 손실 (FastSpeech2)으로 감독 된 지속 시간 신호하에 각 모듈에 대해 여러 테스트를 하나씩 테스트했습니다. 지금까지 Soft-DTW를 제외한 모든 모듈이 다음과 같이 잘 작동하고 있음을 확인할 수 있습니다 (합성 된 스펙트럼, GT 스펙트로 그램, 잔류 정렬 및 Wearnupsampling의 W에서 W w).
자세한 내용은 최신 커밋 로그 및 업데이트 된 구현 문제 섹션을 확인하십시오. 또한 https://github.com/keonlee9420/fastspeech2/commits/ptaco2에서 진행중인 실험을 찾을 수 있습니다.
2021.05.15 : 구현 완료. 정신적 검사 훈련 및 추론. 그러나 여전히 모델은 수렴 할 수 없습니다.
I'm waiting for your contribution! 내 구현에 실수가 있거나 모델을 성공적으로 훈련시키기위한 귀중한 조언을 찾으면 알려주십시오. 구현 문제 섹션을 참조하십시오.
파이썬 종속성을 설치할 수 있습니다
pip3 install -r requirements.txt LConvBlock 활용하려면 FairSeQ (GitHub)를 설치하십시오. 설치시 문제를 해결하려면 #5를 확인하십시오.
지원되는 데이터 세트 :
데이터 세트를 다운로드 한 후 corpus_path preprocess.yaml 로 설정하고 준비 스크립트를 실행하십시오.
python3 prepare_data.py config/LJSpeech/preprocess.yaml
그런 다음 전처리 스크립트를 실행하십시오.
python3 preprocess.py config/LJSpeech/preprocess.yaml
모델을 훈련하십시오
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
모델은 아직 수렴 할 수 없습니다. 디버깅하지만 멋진 기여가 준비되면 향상 될 것입니다!
단일 추론을 위해 실행하십시오
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 900000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
생성 된 발화는 output/result/ 로 저장됩니다.
배치 추론도 지원됩니다
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step 900000 --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
preprocessed_data/LJSpeech/val.txt 의 모든 발화를 종합합니다.
사용
tensorboard --logdir output/log/LJSpeech
지역 호스트에서 텐서 보드를 제공합니다.
전반적으로, 원래 논문에서 제안되지 않은 정규화 또는 활성화는 전방 및 후진 계산에서 NAN 값 (그라디언트)을 방지하기 위해 적절하게 배열됩니다. (Nan은 네트워크에서 무언가 잘못되었음을 나타냅니다)
FFTBlock 사용하십시오.ConvBlock 에 드롭 아웃 0.2 사용하십시오.grapheme_to_phoneme 함수를 구현하십시오. (./text/ init 참조). 128-bin 대신 80 channels Mel-Spectrogrom을 사용하십시오.nn.SiLU() 사용하십시오.W 및 C 얻을 때, V 의 프레임 도메인 (T 도메인) 방송 후 S , E 및 V 에 연결 작업이 적용된다. LConvBlock 및 규칙적인 정현파 위치 임베딩을 사용하십시오.LConvBLock 출력에 nn.Tanh() 적용합니다 (FastSpeech2에서 디코더 부품의 활성화 패턴에 따라). model/soft_dtw_cuda.py 에서 맞춤형 소프트 DTW를 구현하여 원래 논문에서 제안 된 재귀를 반영합니다.E 만 계산됩니다. 그러나 손실 함수로 사용되는 Jacobian 제품은 R WRT 입력 X 의 목표 파생물을 반환하기 위해 추가됩니다.8 입니다. @misc{lee2021parallel_tacotron2,
author = {Lee, Keon},
title = {Parallel-Tacotron2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Parallel-Tacotron2}}
}


