Parallel Tacotron2
1.0.0
Pytorch-Implementierung von Googles Parallel Tacotron 2: Ein nicht autoregressives TTS-Modell mit differenzierbarer Dauermodellierung
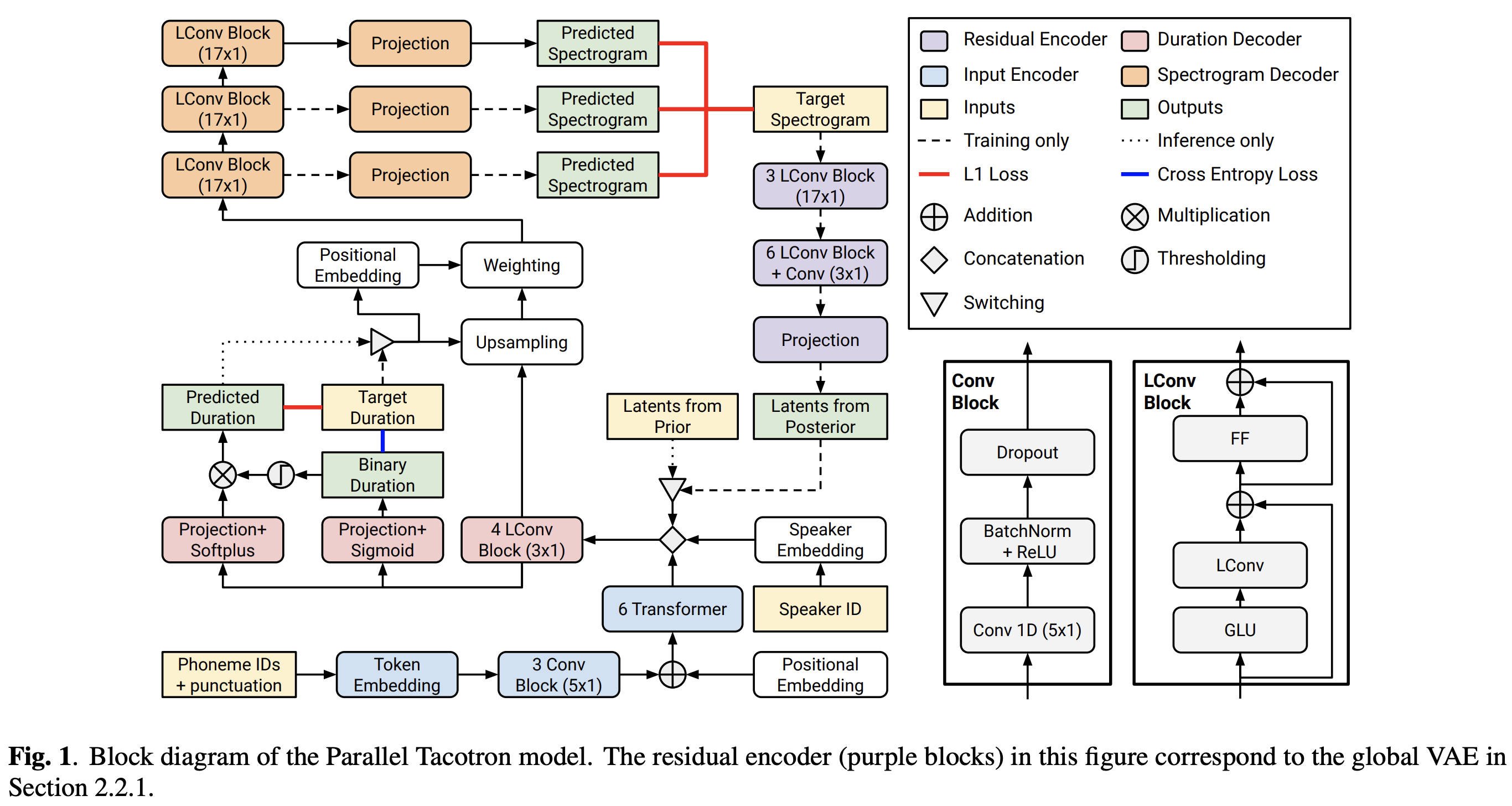
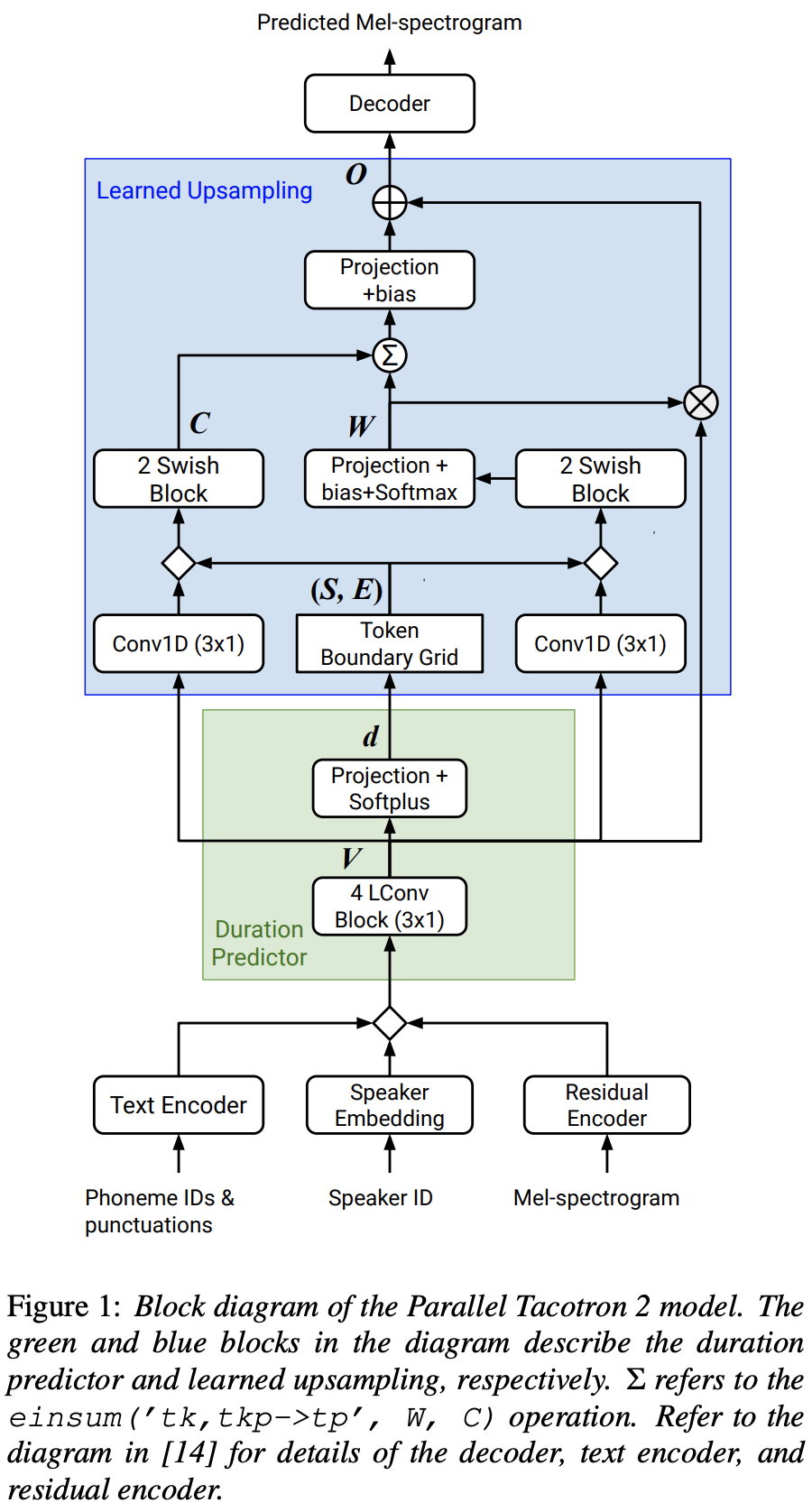
2021.05.25: Only the soft-DTW remains the last hurdle! Nach den Ratschlägen des Autors zur Implementierung habe ich mit L1 -Verlust (Fastspeech2) mehrere Tests für jedes Modul eins nach dem anderen unter einem überwachten Dauersignal durchgeführt. Bisher kann ich bestätigen, dass alle Module mit Ausnahme von Soft-DTW gut wie folgt funktionieren (synthetisiertes Spektrogramm, GT-Spektrogramm, Restausrichtung und W von LearnuPsampling von oben nach unten).
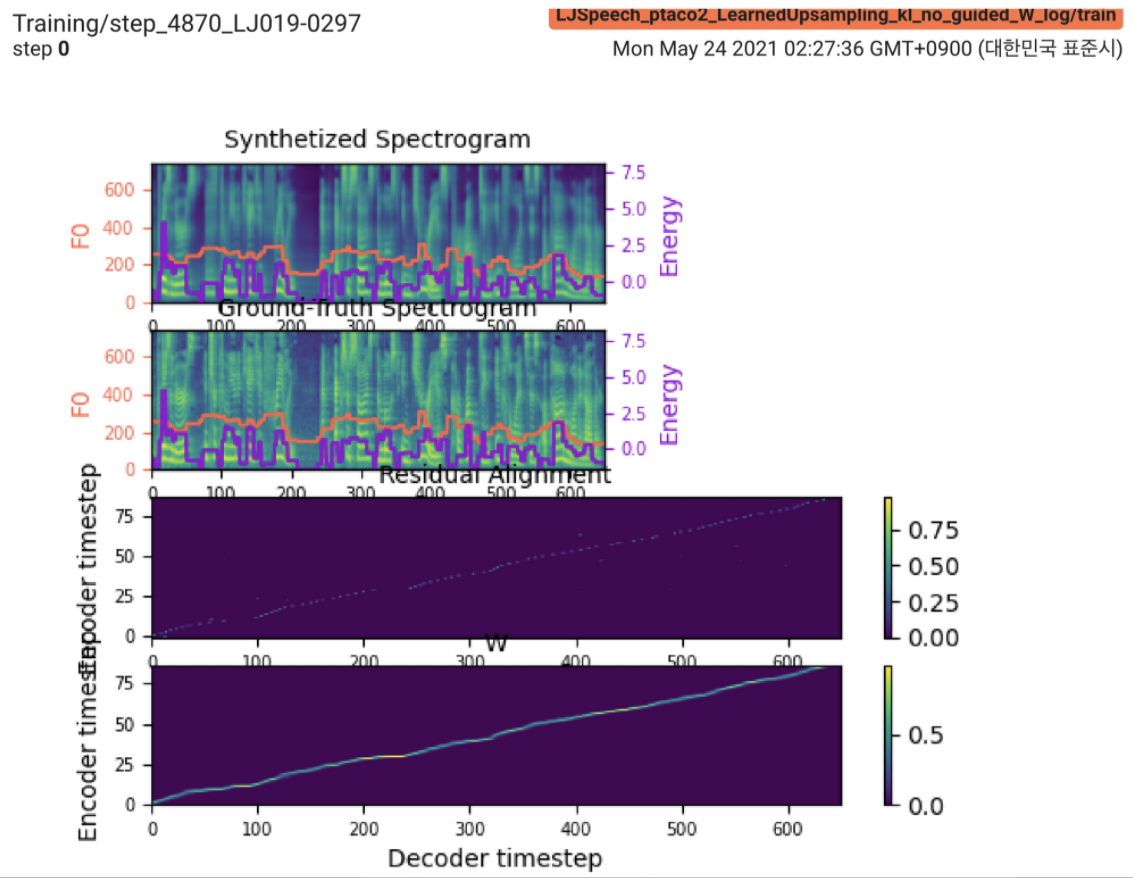
Die Details finden Sie unter dem Abschnitt "Neueste Commit -Protokoll" und "Aktualisierte Implementierungsprobleme". Außerdem finden Sie die laufenden Experimente unter https://github.com/keonlee9420/fastspeech2/commits/ptaco2.
2021.05.15: Implementierung durchgeführt. Geistige Gesundheitsprüfungen über Training und Inferenz. Trotzdem kann das Modell nicht konvergieren.
I'm waiting for your contribution! Bitte informieren Sie mich, wenn Sie Fehler in meiner Implementierung oder wertvolle Ratschläge finden, um das Modell erfolgreich auszubilden. Siehe Abschnitt "Implementierungsprobleme".
Sie können die Python -Abhängigkeiten mit installieren
pip3 install -r requirements.txt Installieren Sie Fairseq (offizielles Dokument, Github), um LConvBlock zu verwenden. Bitte überprüfen Sie Nr. 5, um ein Problem bei der Installation zu beheben.
Die unterstützten Datensätze:
Setzen Sie nach dem Herunterladen der Datensätze den corpus_path in preprocess.yaml und führen Sie das Vorbereitungsskript aus:
python3 prepare_data.py config/LJSpeech/preprocess.yaml
Führen Sie dann das Vorverarbeitungsskript aus:
python3 preprocess.py config/LJSpeech/preprocess.yaml
Trainieren Sie Ihr Modell mit
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Das Modell kann noch nicht konvergieren. Ich debuggiere, aber es würde verstärkt, wenn Ihr großartiger Beitrag fertig ist!
Für eine einzelne Inferenz laufen Sie
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 900000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Die erzeugten Äußerungen werden in output/result/ .
Batch -Inferenz wird ebenfalls unterstützt, versuchen Sie es
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step 900000 --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
So synthetisieren Sie alle Äußerungen in preprocessed_data/LJSpeech/val.txt .
Verwenden
tensorboard --logdir output/log/LJSpeech
Tensorboard auf Ihrem örtlichen Haus servieren.
Insgesamt ist die Normalisierung oder Aktivierung, die im ursprünglichen Papier nicht vorgeschlagen wird, angemessen angeordnet, um den NAN -Wert (Gradienten) bei Vorwärts- und Rückwärtsberechnungen zu verhindern. (Nan zeigt an, dass im Netzwerk etwas nicht stimmt)
FFTBlock von Fastspeech2 für den Transformatorblock des Textcodierers.0.2 für die ConvBlock des Textcodierers.grapheme_to_phoneme . (Siehe ./text/ init ). 80 channels melspektrogrom anstelle von 128-bin .nn.SiLU() für die Swish -Aktivierung.W und C wird der Verkettungsvorgang zwischen S , E und V nach dem Rundfunk (T-Domäne) von V . LConvBlock und regelmäßige sinusförmige Positionseinbettung.nn.Tanh() auf jeden LConvBLock -Ausgang an (nach Aktivierungsmuster des Decoder -Teils in Fastspeech2). model/soft_dtw_cuda.py , wobei die im Originalpapier vorgeschlagene Rekursion widerspiegelt.E berechnet. Jacobian wird jedoch als Verlustfunktion eingesetzt und wird hinzugefügt, um das Zielderivet von R WRT Eingabe X zurückzugeben.8 in 24-Gib-GPU (Titan RTX) aufgrund des Raumkomplexitätsproblems beim Verlust von Soft-DTW. @misc{lee2021parallel_tacotron2,
author = {Lee, Keon},
title = {Parallel-Tacotron2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Parallel-Tacotron2}}
}


