Parallel Tacotron2
1.0.0
Implementação de Pytorch do Tacotron Paralelo 2 do Google: um modelo TTS neural não autorregressivo com modelagem de duração diferenciável
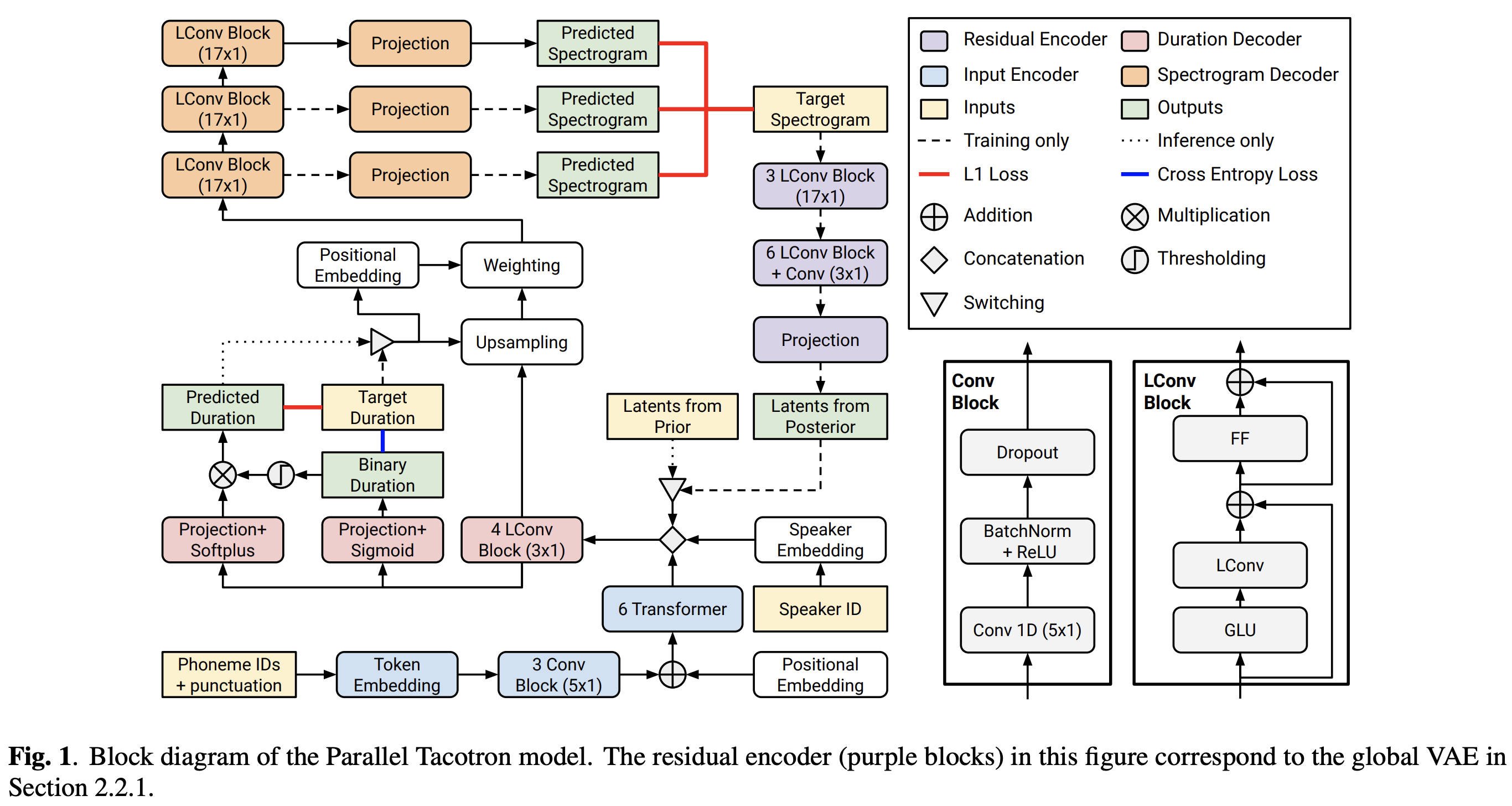
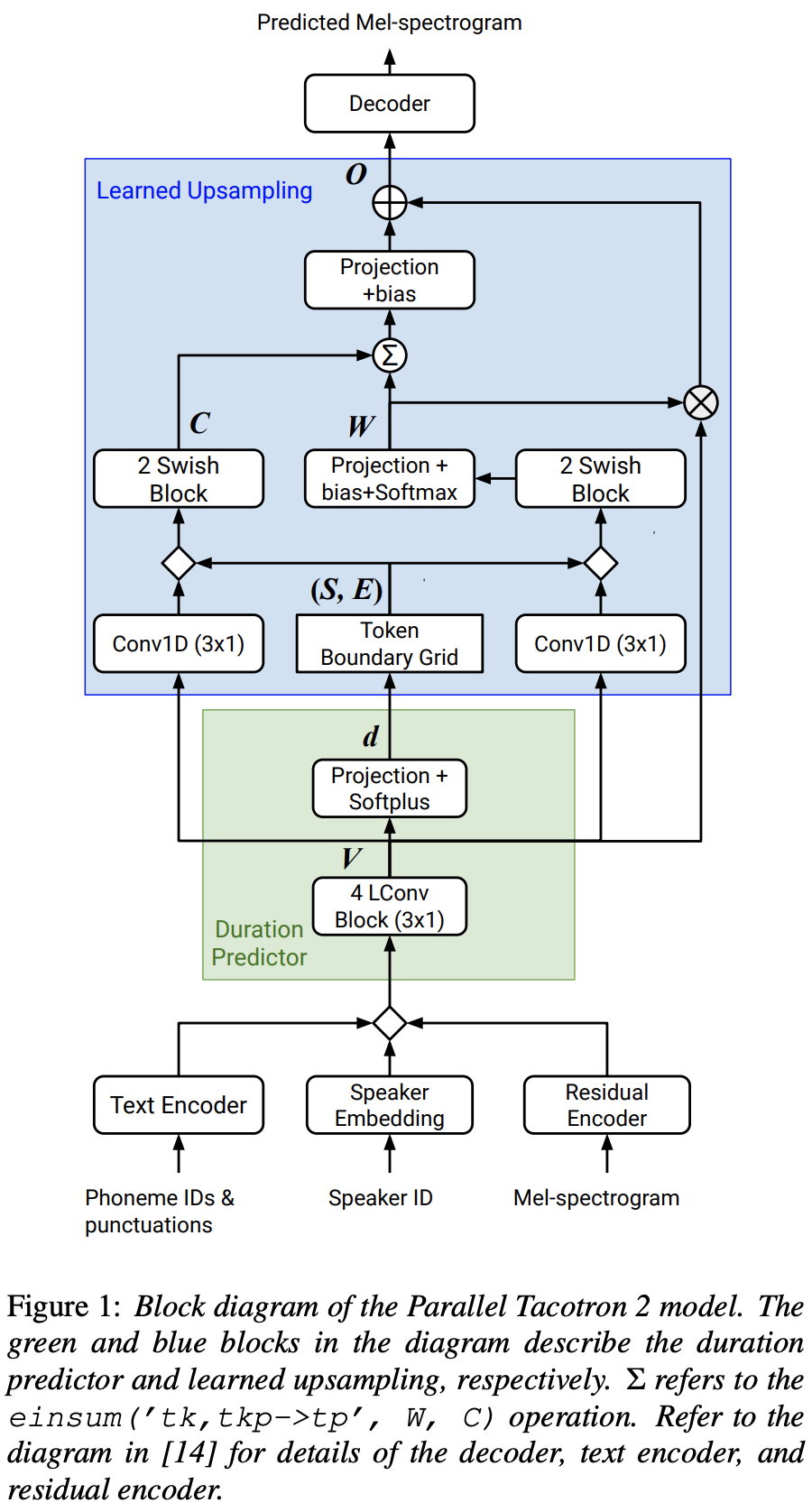
2021.05.25: Only the soft-DTW remains the last hurdle! Seguindo o conselho do autor sobre a implementação, fiz vários testes em cada módulo um por um sob um sinal de duração supervisionado com perda L1 (FastSpeech2). Até agora, posso confirmar que todos os módulos, exceto o Soft-DTW, estão funcionando bem como a seguir (espectrograma sintetizado, espectrograma GT, alinhamento residual e W do amostramento de cima para baixo).
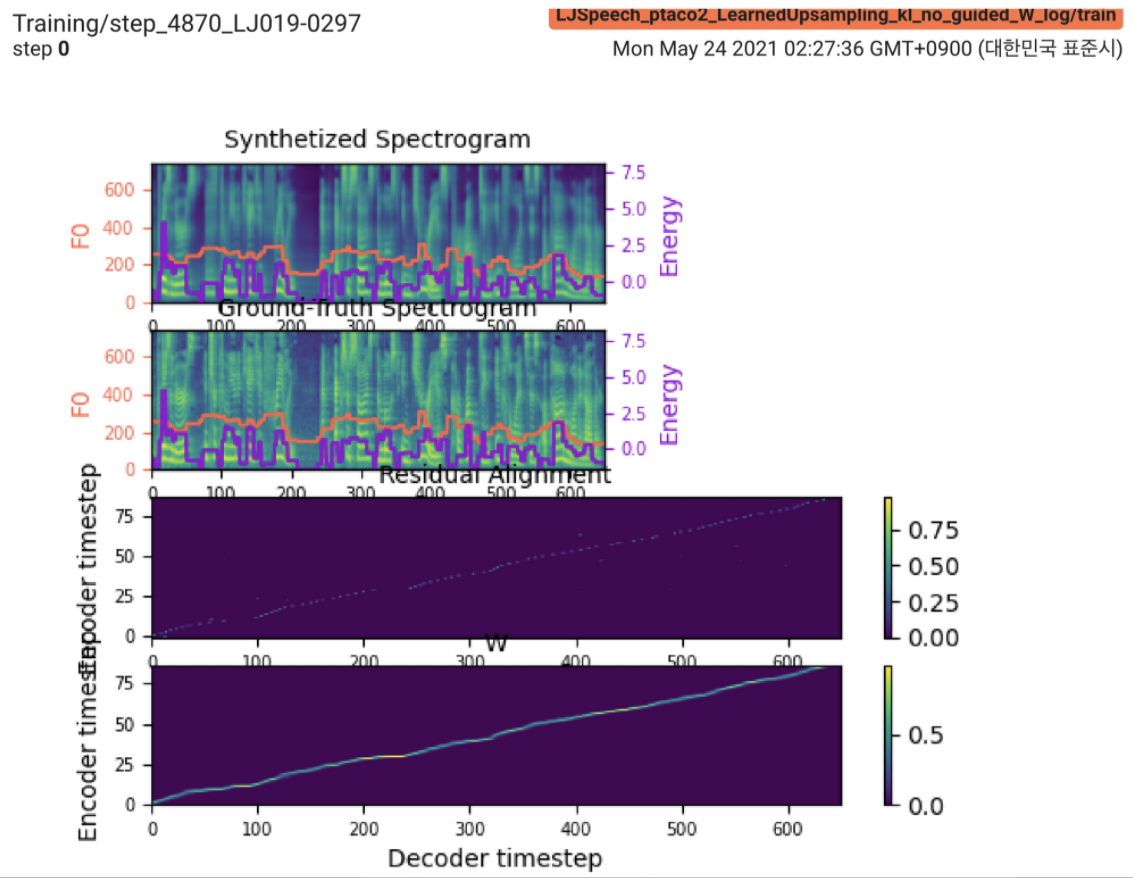
Para obter detalhes, verifique o log mais recente e a seção de problemas de implementação atualizada. Além disso, você pode encontrar os experimentos em andamento em https://github.com/keonlee9420/fastspeech2/commits/ptaco2.
2021.05.15: Implementação realizada. A sanidade verifica o treinamento e a inferência. Mas ainda assim o modelo não pode convergir.
I'm waiting for your contribution! Por favor, informe -me se você encontrar algum erro na minha implementação ou qualquer conselho valioso para treinar o modelo com sucesso. Consulte a seção de problemas de implementação.
Você pode instalar as dependências do Python com
pip3 install -r requirements.txt Instale o Fairseq (documento oficial, GitHub) para utilizar LConvBlock . Verifique o #5 para resolver qualquer problema na instalação.
Os conjuntos de dados suportados:
Depois de baixar os conjuntos de dados, defina o corpus_path no preprocess.yaml e execute o script de preparação:
python3 prepare_data.py config/LJSpeech/preprocess.yaml
Em seguida, execute o script de pré -processamento:
python3 preprocess.py config/LJSpeech/preprocess.yaml
Treine seu modelo com
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
O modelo ainda não pode convergir. Estou depurando, mas seria impulsionado se sua incrível contribuição estivesse pronta!
Para uma única inferência, execute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 900000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Os enunciados gerados serão salvos na output/result/ .
A inferência em lote também é suportada, tente
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step 900000 --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Para sintetizar todos os enunciados em preprocessed_data/LJSpeech/val.txt .
Usar
tensorboard --logdir output/log/LJSpeech
Para servir o Tensorboard em sua localhost.
No geral, a normalização ou ativação, que não é sugerida no artigo original, é adequadamente organizada para impedir o valor da NAN (gradiente) nos cálculos para a frente e para trás. (NAN indica que algo está errado na rede)
FFTBlock do FastSpeech2 para o bloco de transformadores do codificador de texto.0.2 para o ConvBlock do codificador de texto.grapheme_to_phoneme Função. (Veja ./Text/ init ). 80 channels MEL-Spectrogroma em vez de 128-bin .nn.SiLU() para a ativação swish.W e C , a operação de concatenação é aplicada entre a transmissão S , E e V após o domínio do quadro (domínio T) de V LConvBlock e incorporação posicional sinusoidal regular.nn.Tanh() a cada saída LConvBLock (seguindo o padrão de ativação da parte do decodificador no FastSpeech2). model/soft_dtw_cuda.py , refletindo a recursão sugerida no papel original.E é calculada. Mas empregado como uma função de perda, o produto jacobiano é adicionado para retornar o derivamento do destino da entrada R wrt X .8 na GPU 24GIB (Titan RTX) devido ao problema da complexidade espacial na perda de DTW soft-dtw. @misc{lee2021parallel_tacotron2,
author = {Lee, Keon},
title = {Parallel-Tacotron2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/Parallel-Tacotron2}}
}


