DiffSinger
1.0.0
การใช้ Pytorch ของ Diffsinger: การร้องเพลงสังเคราะห์ด้วยกลไกการแพร่กระจายแบบตื้น (มุ่งเน้นไปที่ diffSpeech)
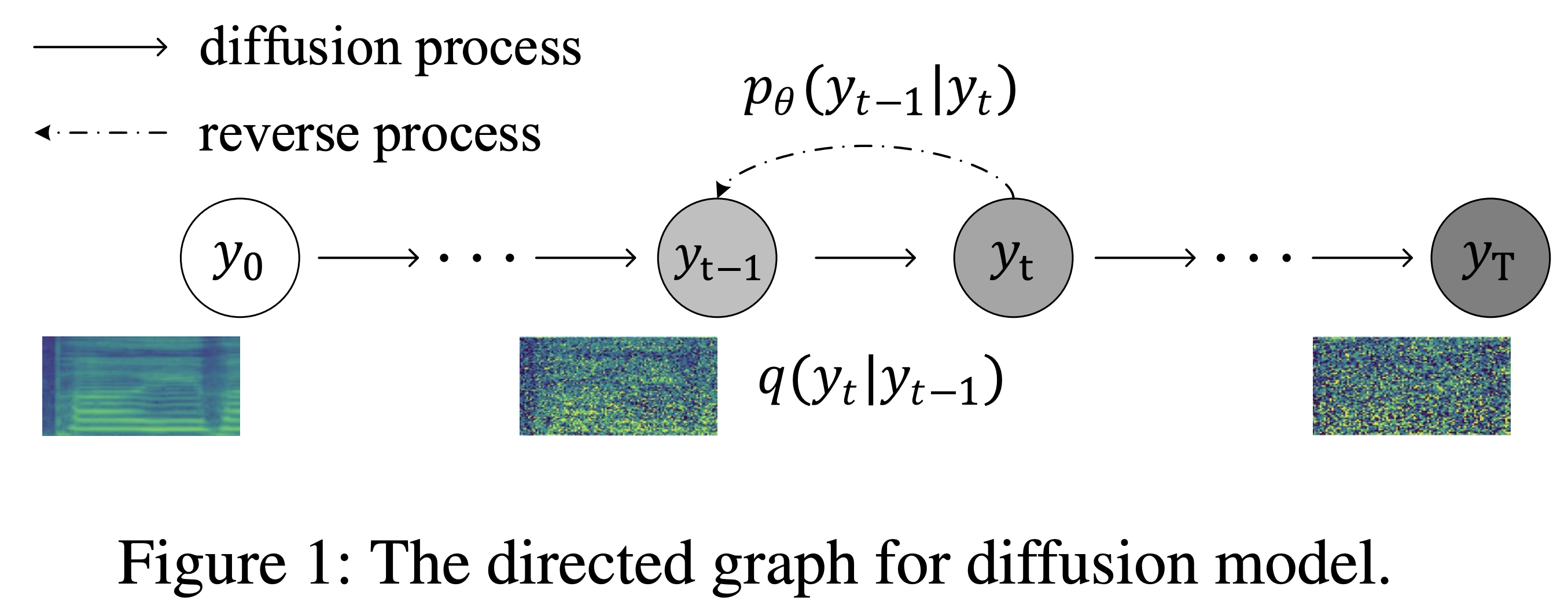
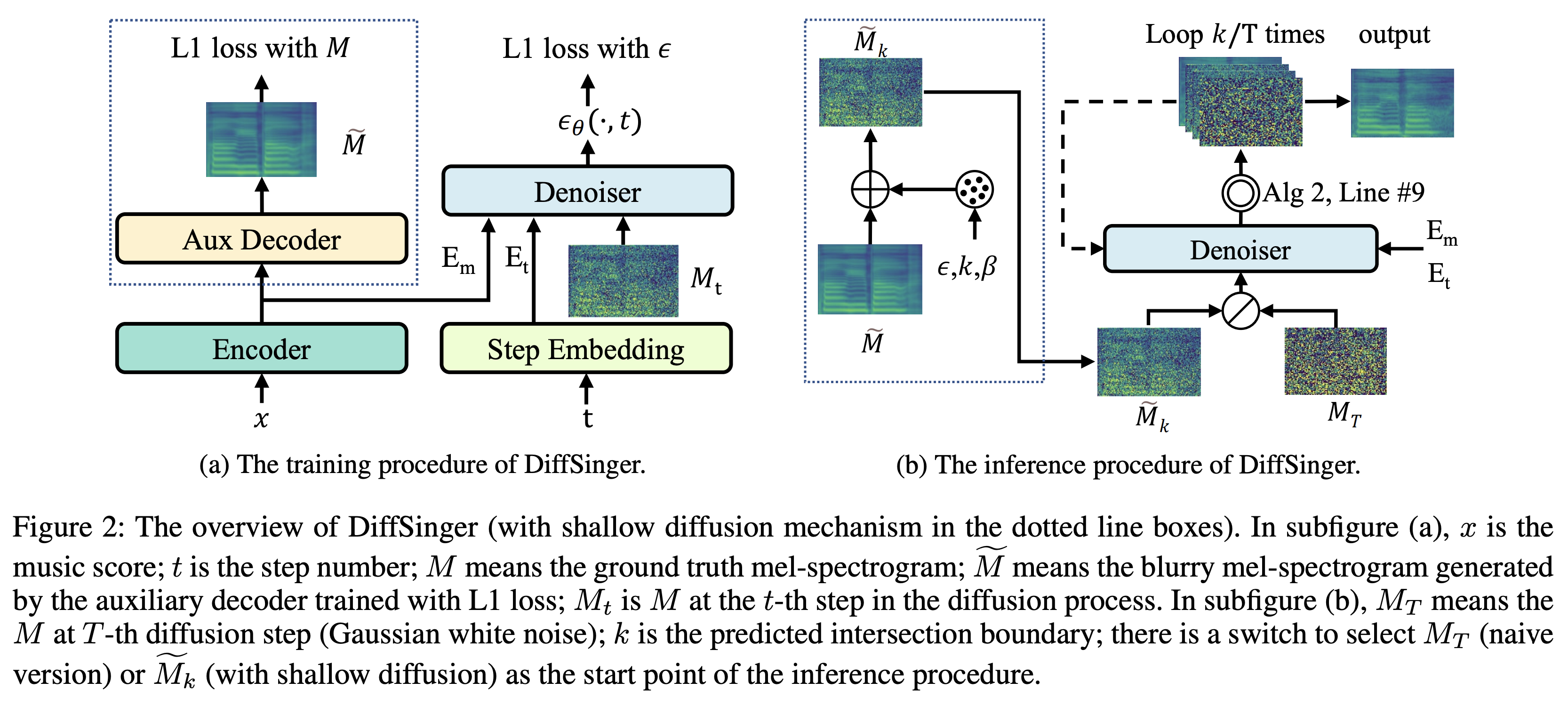
K K เป็นขั้นตอนเวลาสูงสุด ชุดข้อมูล หมายถึงชื่อของชุดข้อมูลเช่น LJSpeech ในเอกสารต่อไปนี้
โมเดล หมายถึงประเภทของโมเดล (เลือกจาก ' ไร้เดียงสา ', ' aux ', ' ตื้น ')
คุณสามารถติดตั้งการพึ่งพา Python ด้วย
pip3 install -r requirements.txt
คุณต้องดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมและใส่ไว้ใน
output/ckpt/LJSpeech_naive/ สำหรับโมเดล ' ไร้เดียงสา 'output/ckpt/LJSpeech_shallow/ สำหรับโมเดล ' ตื้น ' โปรดทราบว่าจุดตรวจของโมเดล ' ตื้น ' มีทั้งแบบจำลอง ' ตื้น ' และ ' AUX ' ทั้งสองรุ่นนี้จะแบ่งปันไดเรกทอรีทั้งหมดยกเว้นผลลัพธ์ตลอดกระบวนการทั้งหมดสำหรับ TTS ลำโพงเดี่ยวภาษาอังกฤษ Run
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
คำพูดที่สร้างขึ้นจะถูกนำไปใช้ใน output/result/
รองรับการอนุมานแบบแบทช์ด้วยลอง
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
เพื่อสังเคราะห์คำพูดทั้งหมดใน preprocessed_data/LJSpeech/val.txt
ระดับเสียง/ปริมาตร/การพูดของคำพูดสังเคราะห์สามารถควบคุมได้โดยการระบุอัตราส่วนระดับเสียง/พลังงาน/ระยะเวลาที่ต้องการ ตัวอย่างเช่นหนึ่งสามารถเพิ่มอัตราการพูดได้ 20 % และลดปริมาณลง 20 % โดย
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
โปรดทราบว่าความสามารถในการควบคุมได้มาจาก FastSpeech2 และไม่ใช่ความสนใจที่สำคัญของ DiffSpeech
ชุดข้อมูลที่รองรับคือ
ก่อนอื่นวิ่ง
python3 prepare_align.py --dataset DATASET
สำหรับการเตรียมการบางอย่าง
สำหรับการจัดตำแหน่งที่ถูกบังคับมอนทรีออลบังคับให้ผู้จัดตำแหน่ง (MFA) ใช้เพื่อให้ได้การจัดตำแหน่งระหว่างคำพูดและลำดับฟอนิม การจัดตำแหน่งที่สกัดไว้ล่วงหน้าสำหรับชุดข้อมูลมีให้ที่นี่ คุณต้องคลายซิปไฟล์ใน preprocessed_data/DATASET/TextGrid/ อีกวิธีหนึ่งคุณสามารถเรียกใช้การจัดตำแหน่งด้วยตัวเอง
หลังจากนั้นเรียกใช้สคริปต์การประมวลผลล่วงหน้าโดย
python3 preprocess.py --dataset DATASET
คุณสามารถฝึกอบรมแบบจำลองสามประเภท: ' ไร้เดียงสา ', ' aux ' และ ' ตื้น '
การฝึกอบรมเวอร์ชันไร้เดียงสา (' ไร้เดียงสา '):
ฝึกอบรมเวอร์ชั่นที่ไร้เดียงสาด้วย
python3 train.py --model naive --dataset DATASET
การฝึกอบรมตัวถอดรหัสสำหรับรุ่นตื้น (' aux '):
ในการฝึกอบรมรุ่นตื้นเราจำเป็นต้องได้รับการฝึกอบรมล่วงหน้า 2 คำสั่งด้านล่างจะช่วยให้คุณฝึกอบรมโมดูล FastSpeech2 รวมถึงตัวถอดรหัสเสริม
python3 train.py --model aux --dataset DATASET
เคล็ดลับง่ายขึ้นสำหรับการทำนายขอบเขต:
ในการรับขอบเขต K จากชุดข้อมูลการตรวจสอบของเราคุณสามารถเรียกใช้ตัวทำนายขอบเขตโดยใช้ FastSpeech2 เสริมที่ได้รับการฝึกอบรมล่วงหน้า 2 โดยคำสั่งต่อไปนี้
python3 boundary_predictor.py --restore_step RESTORE_STEP --dataset DATASET
มันจะพิมพ์ค่าที่คาดการณ์ไว้ (พูด K_STEP ) ในบันทึกคำสั่ง
จากนั้นตั้งค่าการกำหนดค่าด้วยค่าที่คาดการณ์ไว้ดังนี้
# In the model.yaml
denoiser :
K_step : K_STEPโปรดทราบว่าสิ่งนี้ขึ้นอยู่กับเคล็ดลับที่แนะนำในภาคผนวก B.
การฝึกอบรมเวอร์ชันตื้น (' ตื้น '):
ในการใช้ประโยชน์จาก FastSpeech2 ที่ผ่านการฝึกอบรมมาแล้วรวมถึงตัวถอดรหัสเสริมคุณต้องตั้งค่า restore_step ด้วยขั้นตอนสุดท้ายของการฝึกอบรมเสริม FastSpeech2 เป็นคำสั่งต่อไปนี้
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
ตัวอย่างเช่นหากจุดตรวจสอบล่าสุดถูกบันทึกไว้ที่ 160000 ขั้นตอนในระหว่างการฝึกอบรมเสริมคุณต้องตั้งค่า restore_step ด้วย 160000 จากนั้นมันจะโหลดโมเดล AUX จากนั้นทำการฝึกอบรมต่อภายใต้กลไกการฝึกอบรมตื้น
ใช้
tensorboard --logdir output/log/LJSpeech
เพื่อให้บริการ Tensorboard บนบ้านของคุณ เส้นโค้งการสูญเสีย mel-spectrograms สังเคราะห์และเสียงจะแสดง
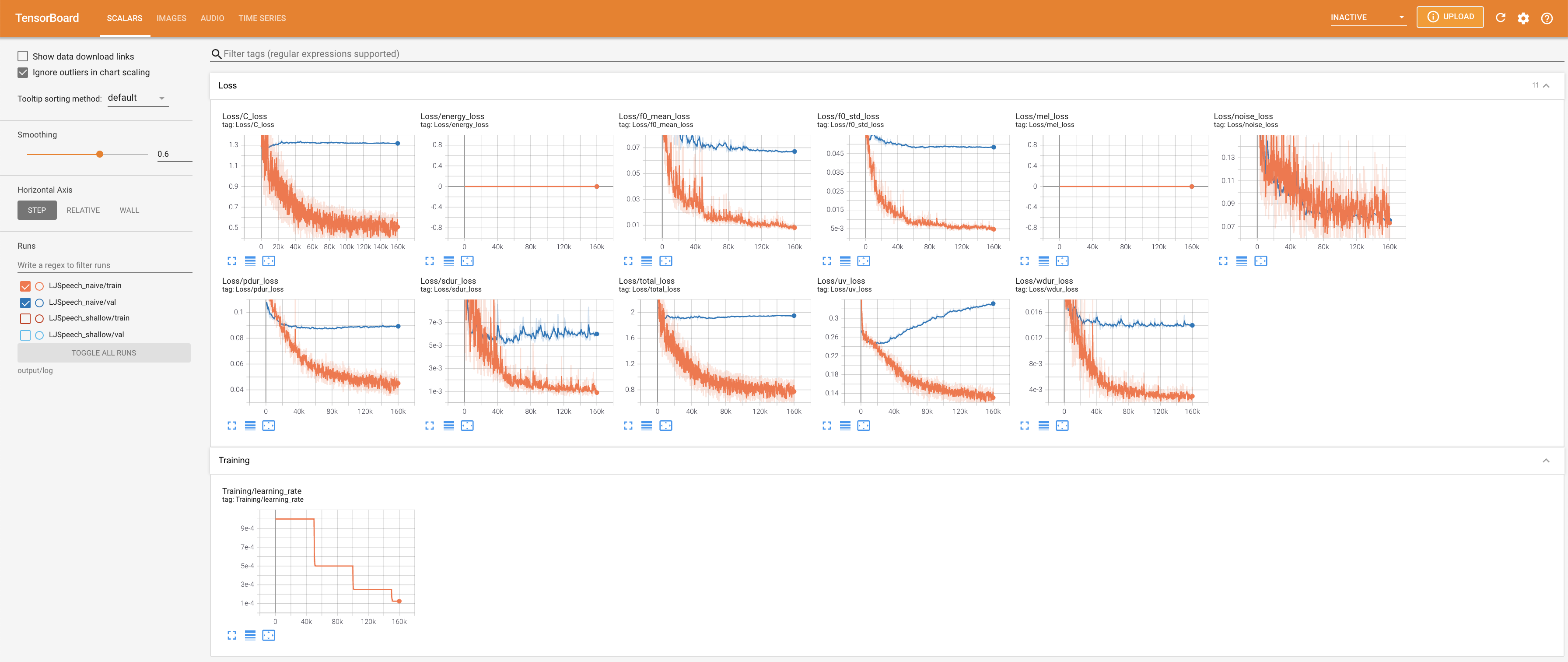
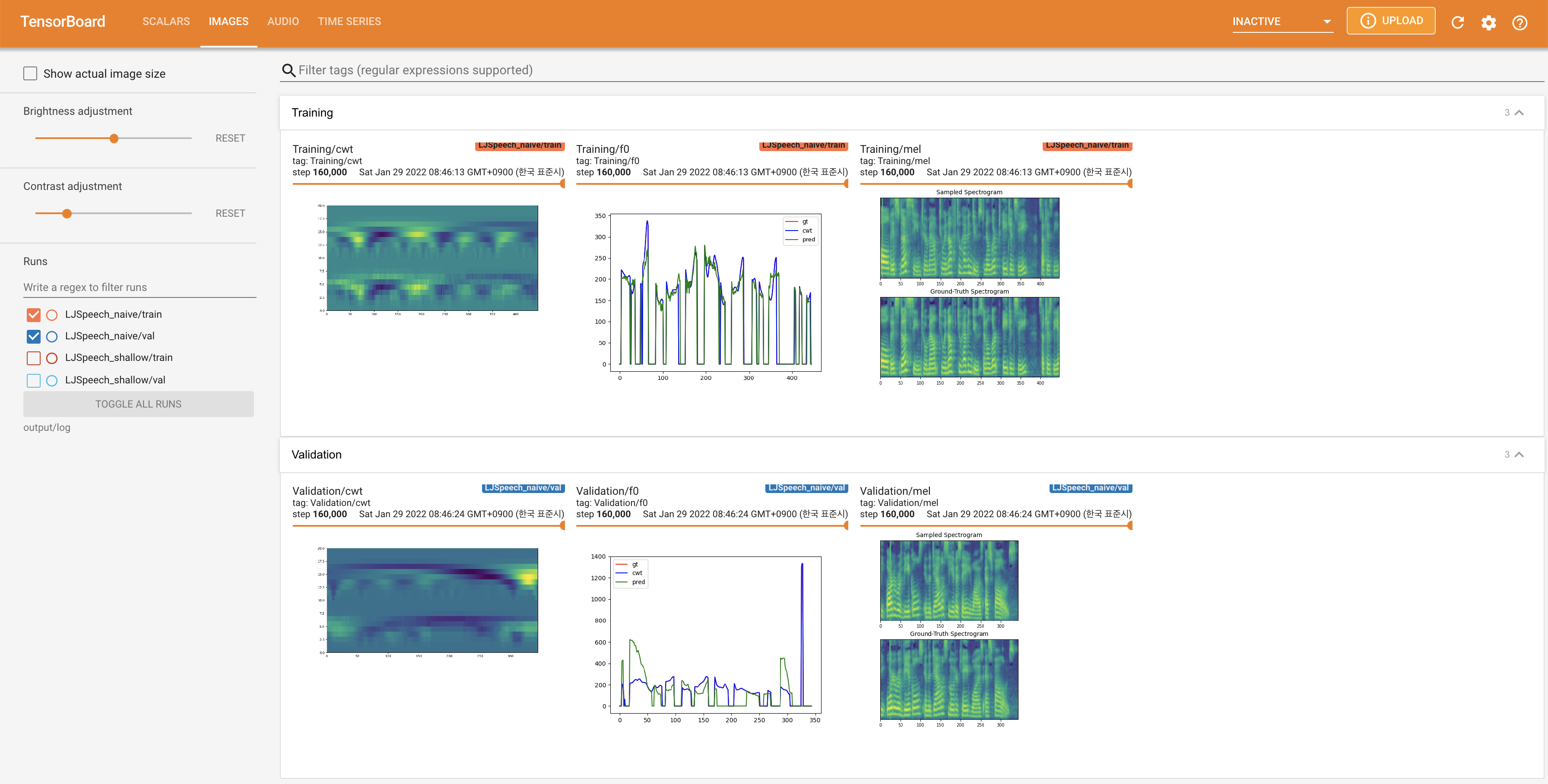
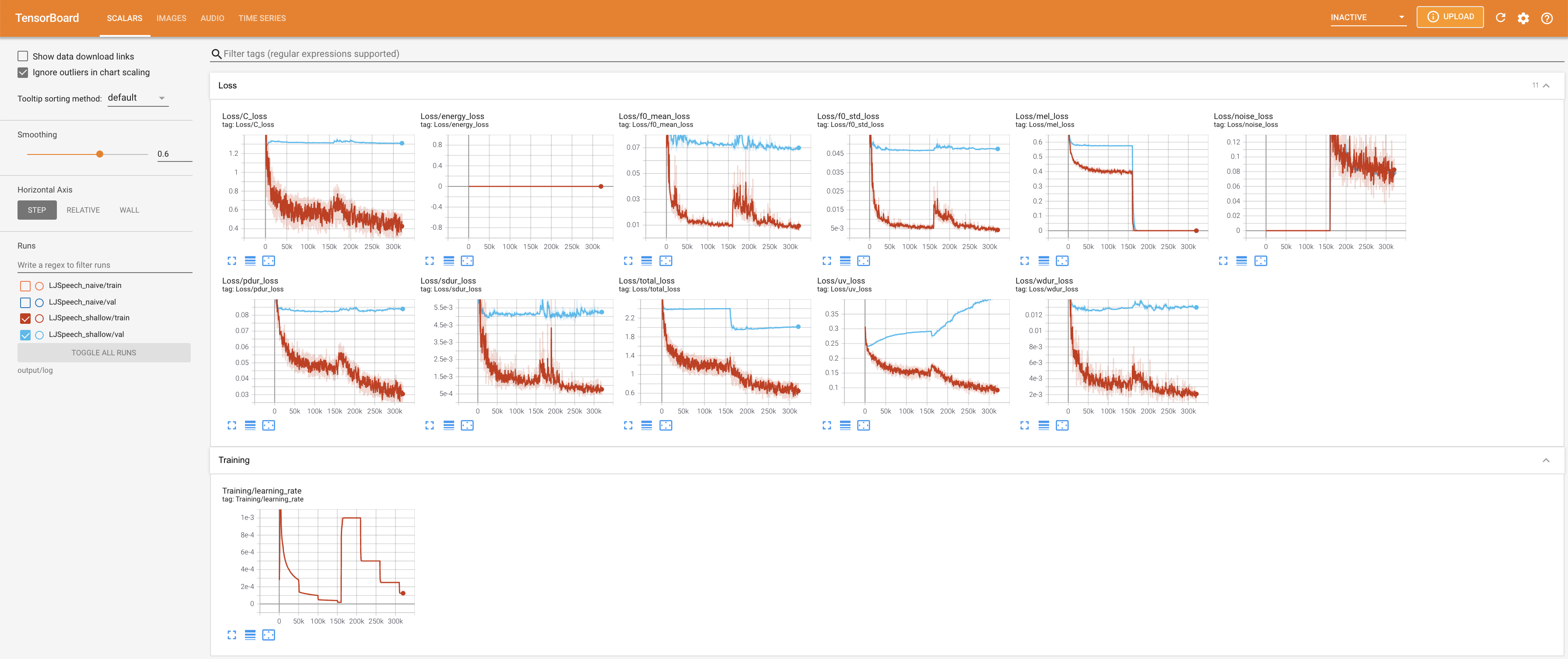
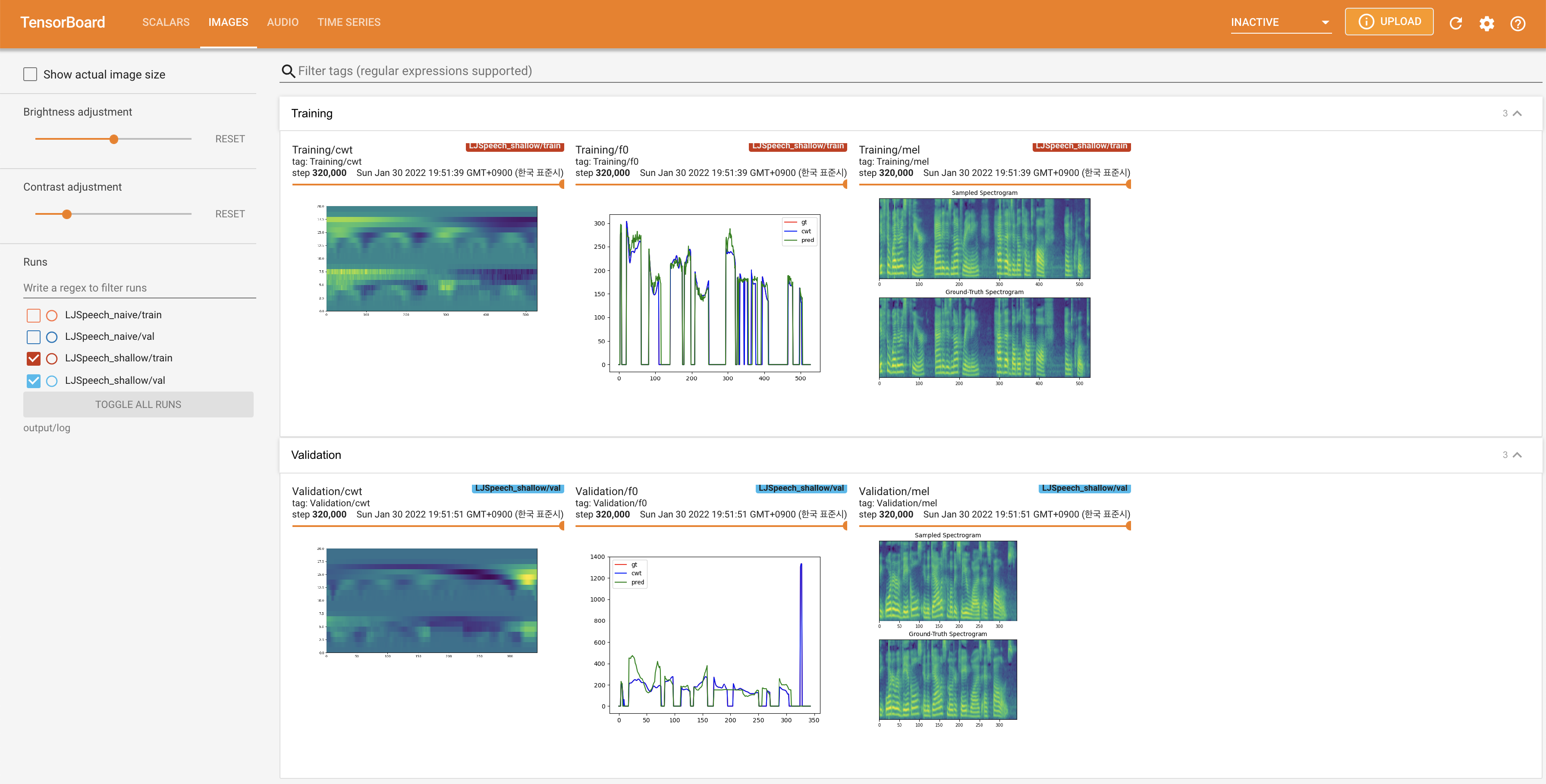
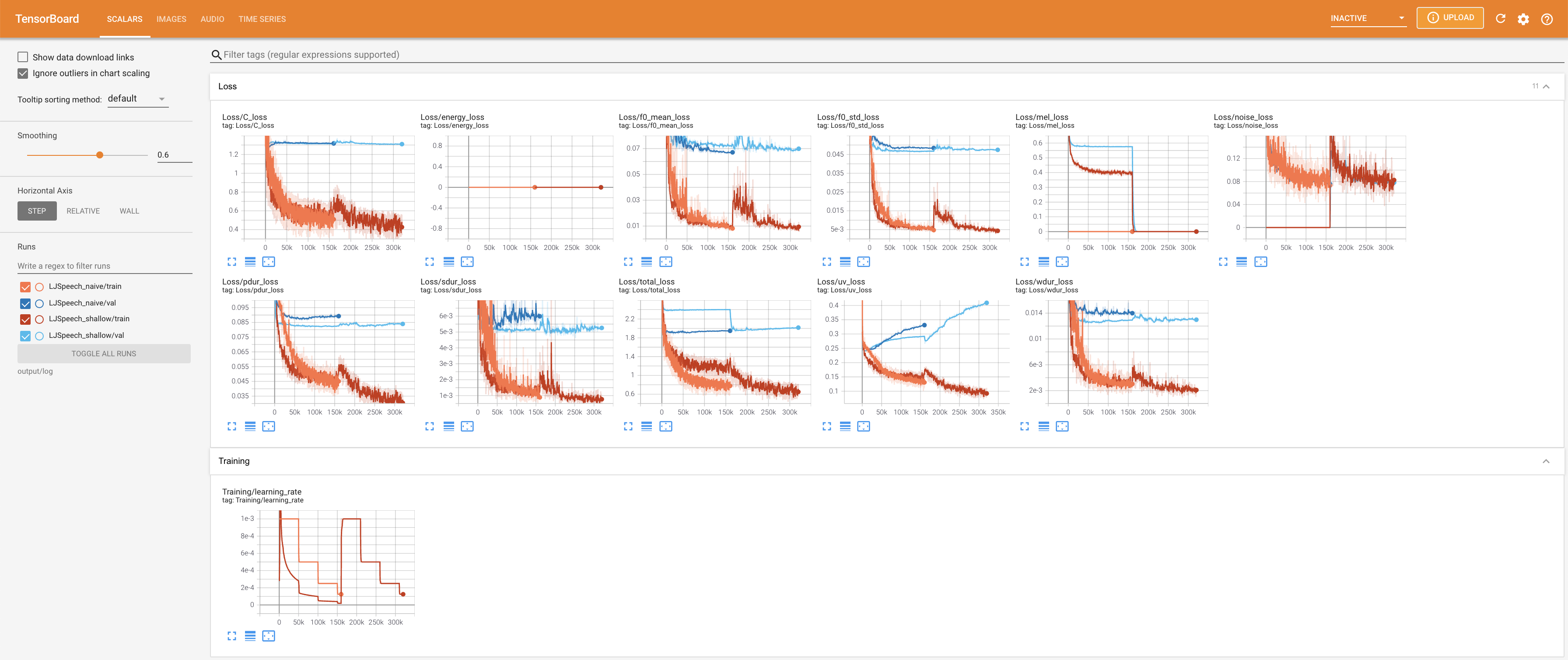
27.767M ซึ่งคล้ายกับกระดาษต้นฉบับ ( 27.722M )100 ซึ่งเป็นช่วงเวลาที่เต็มไปด้วยการแพร่กระจายที่ไร้เดียงสาเพื่อให้ไม่มีข้อได้เปรียบในขั้นตอนการแพร่กระจาย @misc{lee2021diffsinger,
author = {Lee, Keon},
title = {DiffSinger},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/DiffSinger}}
}


