DiffSinger
1.0.0
Implementación de Pytorch de Diffsinger: síntesis de voz de canto a través del mecanismo de difusión poco profunda (centrado en la diferencia).
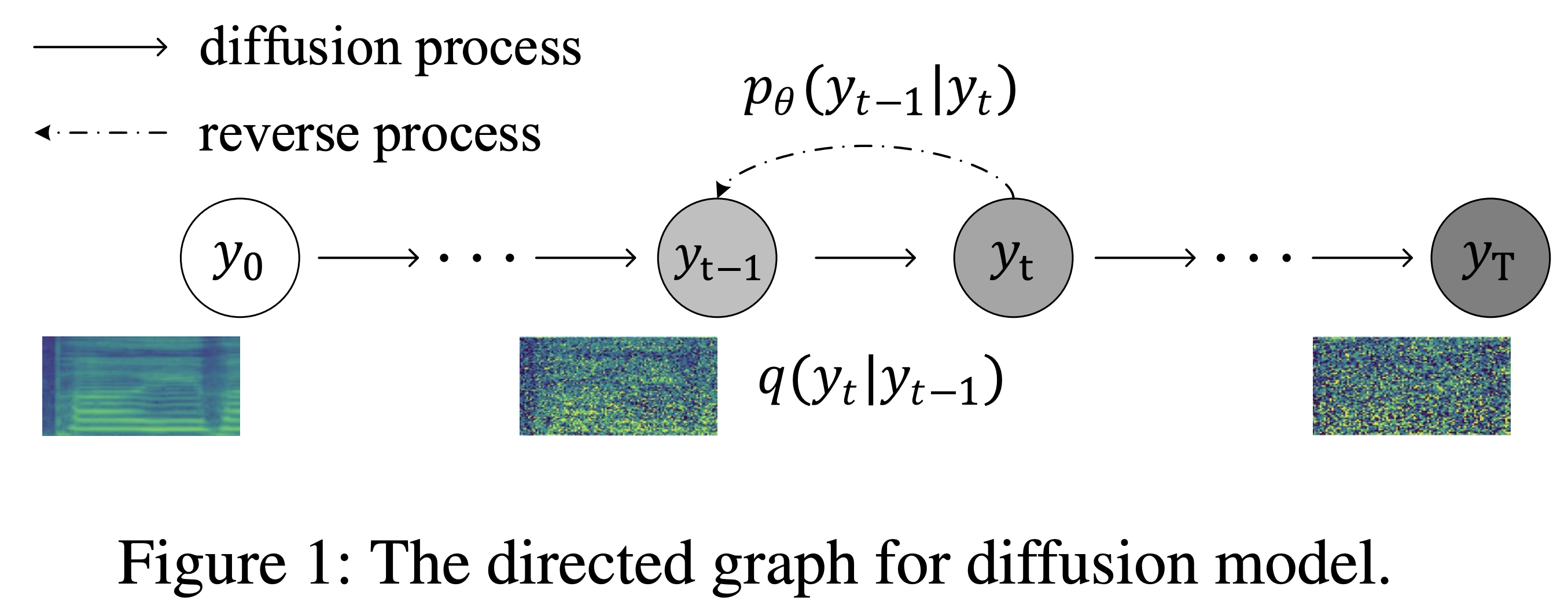
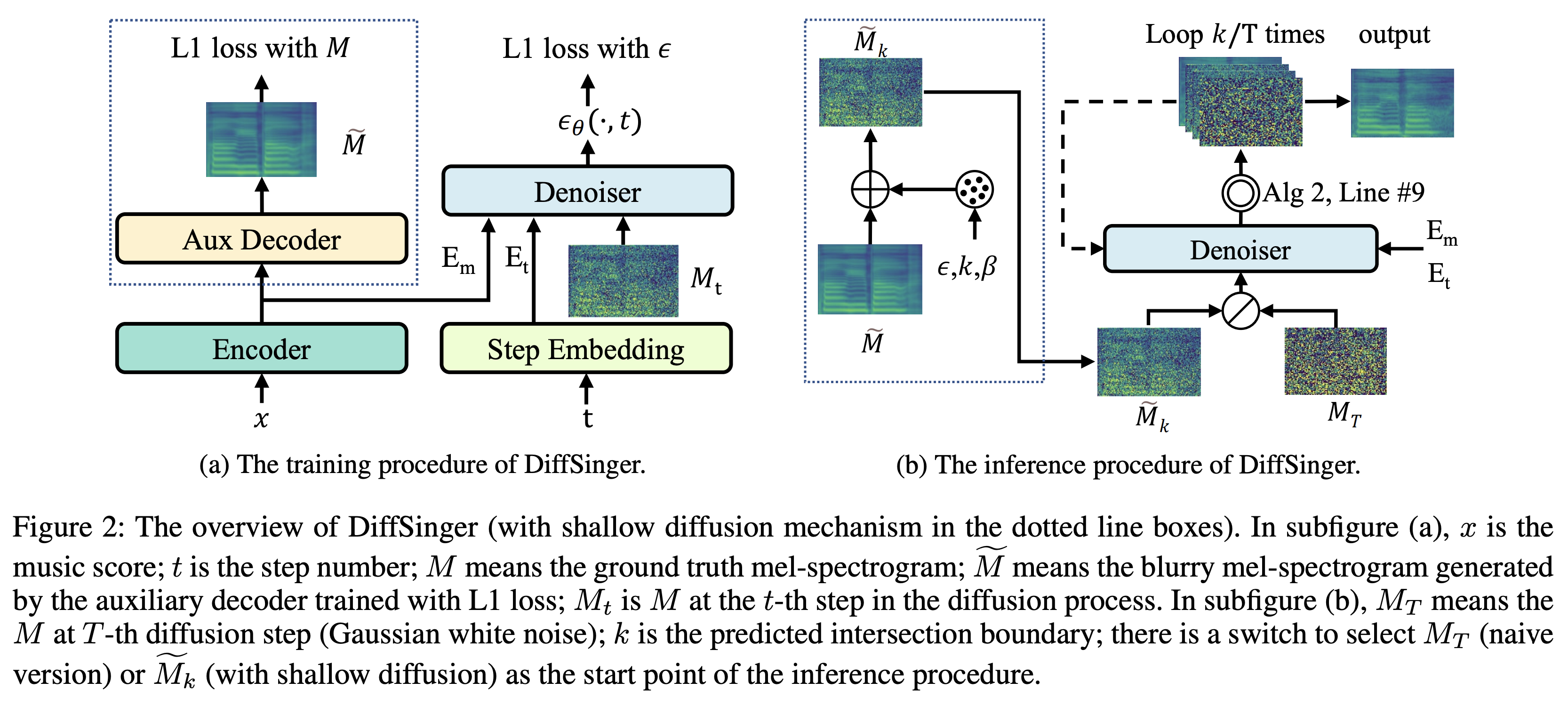
K K como paso de tiempo máximo El conjunto de datos se refiere a los nombres de conjuntos de datos como LJSpeech en los siguientes documentos.
El modelo se refiere a los tipos de modelo (elija entre ' ingenuo ', ' aux ', ' superficial ').
Puede instalar las dependencias de Python con
pip3 install -r requirements.txt
Tienes que descargar los modelos previos a la aparición y ponerlos en
output/ckpt/LJSpeech_naive/ para el modelo ' ingenuo '.output/ckpt/LJSpeech_shallow/ para el modelo ' Shallow '. Tenga en cuenta que el punto de control del modelo ' poco profundo ' contiene modelos ' superficiales ' y ' aux ', y estos dos modelos compartirán todos los directorios, excepto los resultados en todo el proceso.Para TTS de un solo hablante inglés, ejecute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
Las expresiones generadas se colocarán en output/result/ .
También es compatible con la inferencia por lotes, intente
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
Para sintetizar todas las expresiones en preprocessed_data/LJSpeech/val.txt .
La tasa de tono/volumen/habla de las expresiones sintetizadas se puede controlar especificando las relaciones de tono/energía/duración deseadas. Por ejemplo, uno puede aumentar la tasa de habla en un 20 % y disminuir el volumen en un 20 % en
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Tenga en cuenta que la capacidad de control se origina en FastSpeech2 y no es un interés vital de DiffSpeech.
Los conjuntos de datos compatibles son
Primero, corre
python3 prepare_align.py --dataset DATASET
para algunos preparativos.
Para la alineación forzada, el alineador forzado de Montreal (MFA) se usa para obtener las alineaciones entre las expresiones y las secuencias de fonema. Aquí se proporcionan alineaciones preextracidas para los conjuntos de datos. Debe descomprimir los archivos en preprocessed_data/DATASET/TextGrid/ . Alternativamente, puede ejecutar el alineador usted mismo.
Después de eso, ejecute el script de preprocesamiento por
python3 preprocess.py --dataset DATASET
Puede entrenar tres tipos de modelo: ' ingenuo ', ' aux ' y ' superficial '.
Entrenamiento de la versión ingenua (' ingenuo '):
Entrena la versión ingenua con
python3 train.py --model naive --dataset DATASET
Capacitación del decodificador auxiliar para la versión poco profunda (' aux '):
Para entrenar la versión poco profunda, necesitamos un FastSpeech2 pre-entrenado. El siguiente comando le permitirá entrenar los módulos FastSpeech2, incluido el decodificador auxiliar.
python3 train.py --model aux --dataset DATASET
Un truco más fácil para la predicción de límites:
Para obtener el límite K de nuestro conjunto de datos de validación, puede ejecutar el predictor de límite utilizando FastSpeech2 auxiliar pre-entrenado por el siguiente comando.
python3 boundary_predictor.py --restore_step RESTORE_STEP --dataset DATASET
Imprimirá el valor predicho (digamos, K_STEP ) en el registro de comando.
Luego, establezca la configuración con el valor predicho de la siguiente manera
# In the model.yaml
denoiser :
K_step : K_STEPTenga en cuenta que esto se basa en el truco introducido en el Apéndice B.
Entrenamiento de la versión superficial (' superficial '):
Para aprovechar FastSpeech2 previamente capacitado, incluido el decodificador auxiliar, debe establecer restore_step con el paso final del entrenamiento auxiliar de FastSpeech2 como el siguiente comando.
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
Por ejemplo, si el último punto de control se guarda en 160000 pasos durante la capacitación auxiliar, debe configurar restore_step con 160000 . Luego cargará el modelo AUX y luego continuará la capacitación bajo un mecanismo de entrenamiento poco profundo.
Usar
tensorboard --logdir output/log/LJSpeech
para servir tensorboard en su localhost. Se muestran las curvas de pérdida, los espectrogramas MEL sintetizados y los audios.
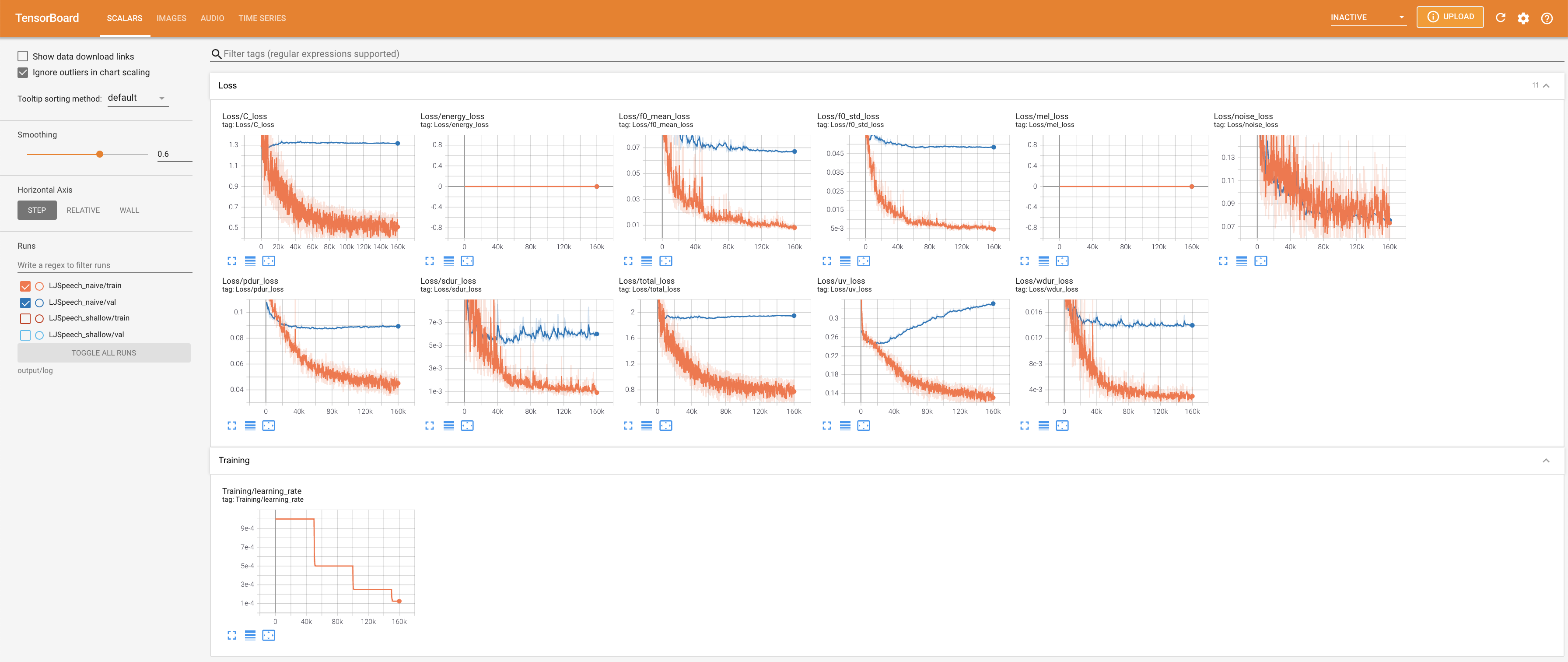
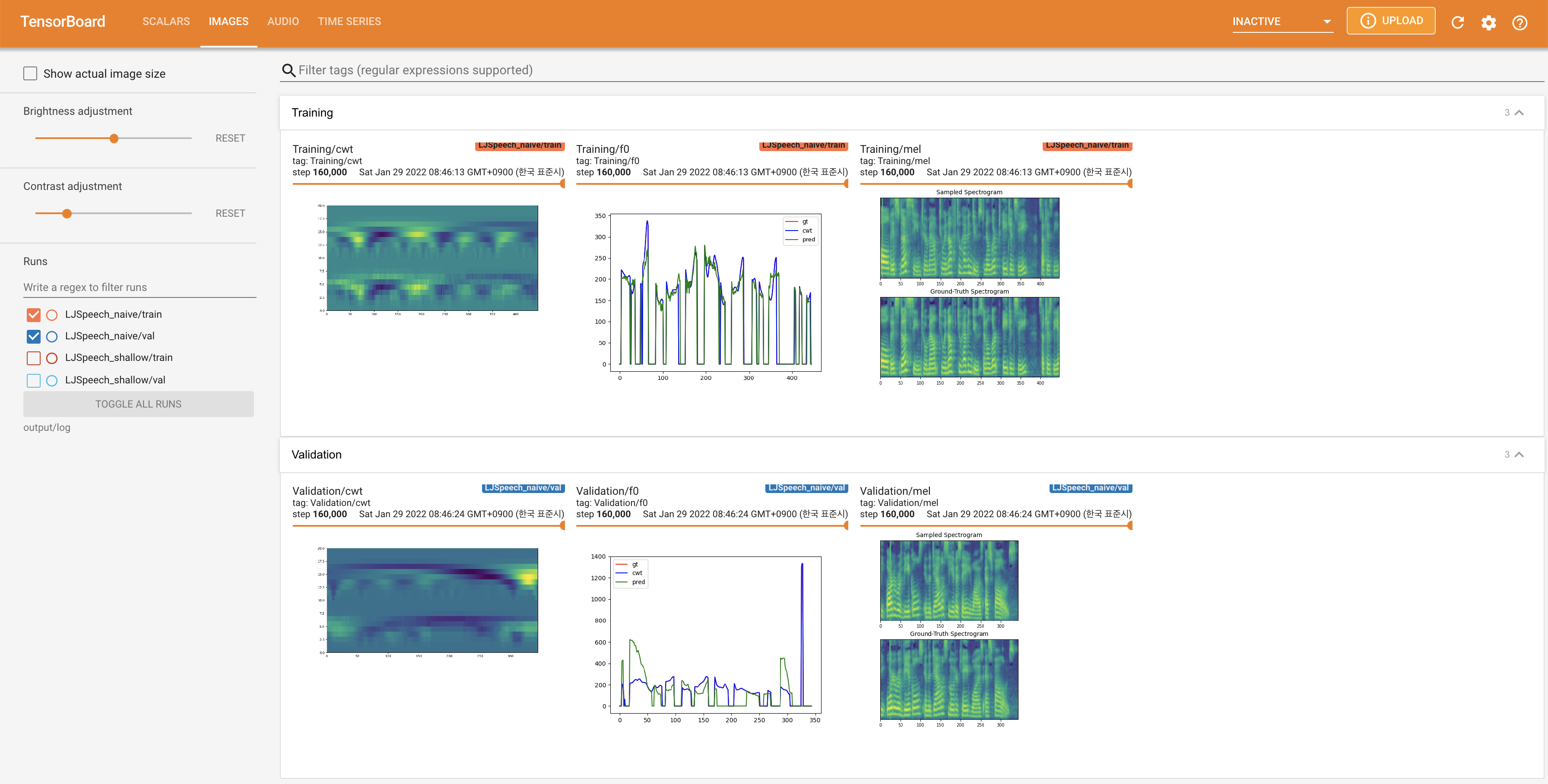
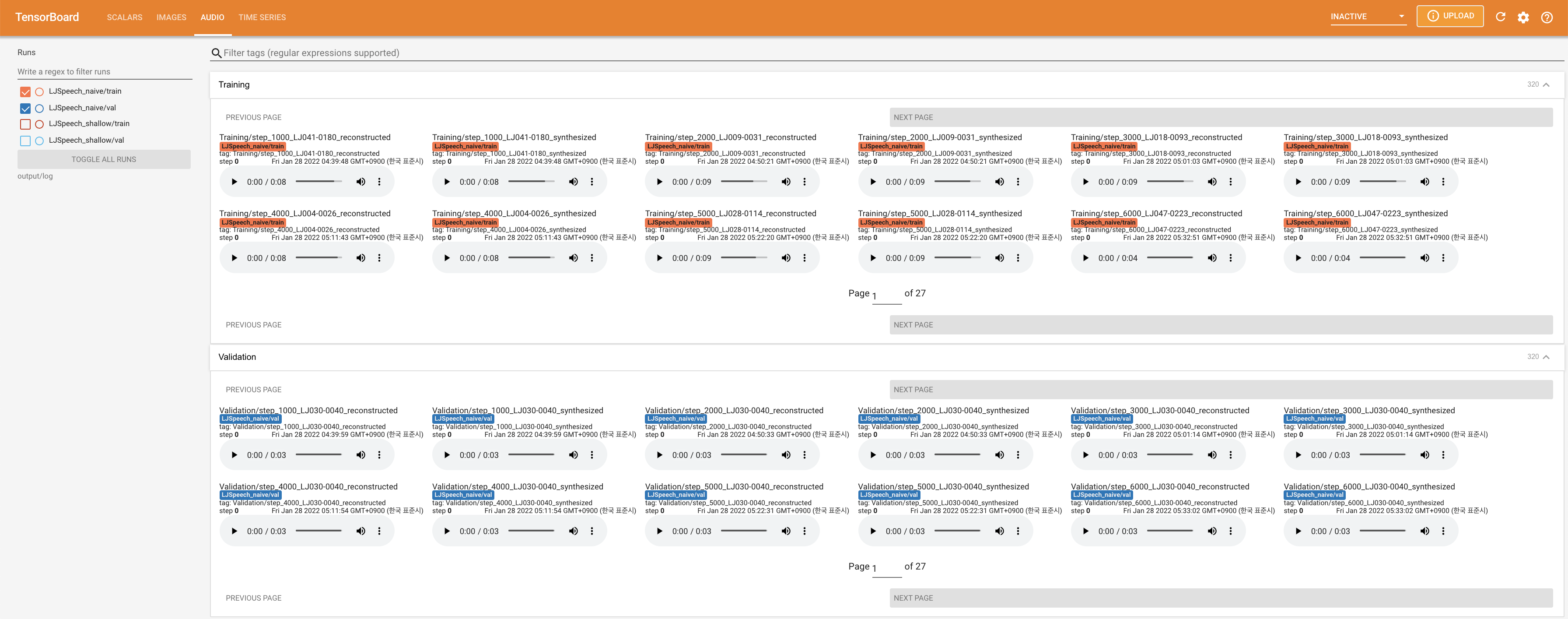
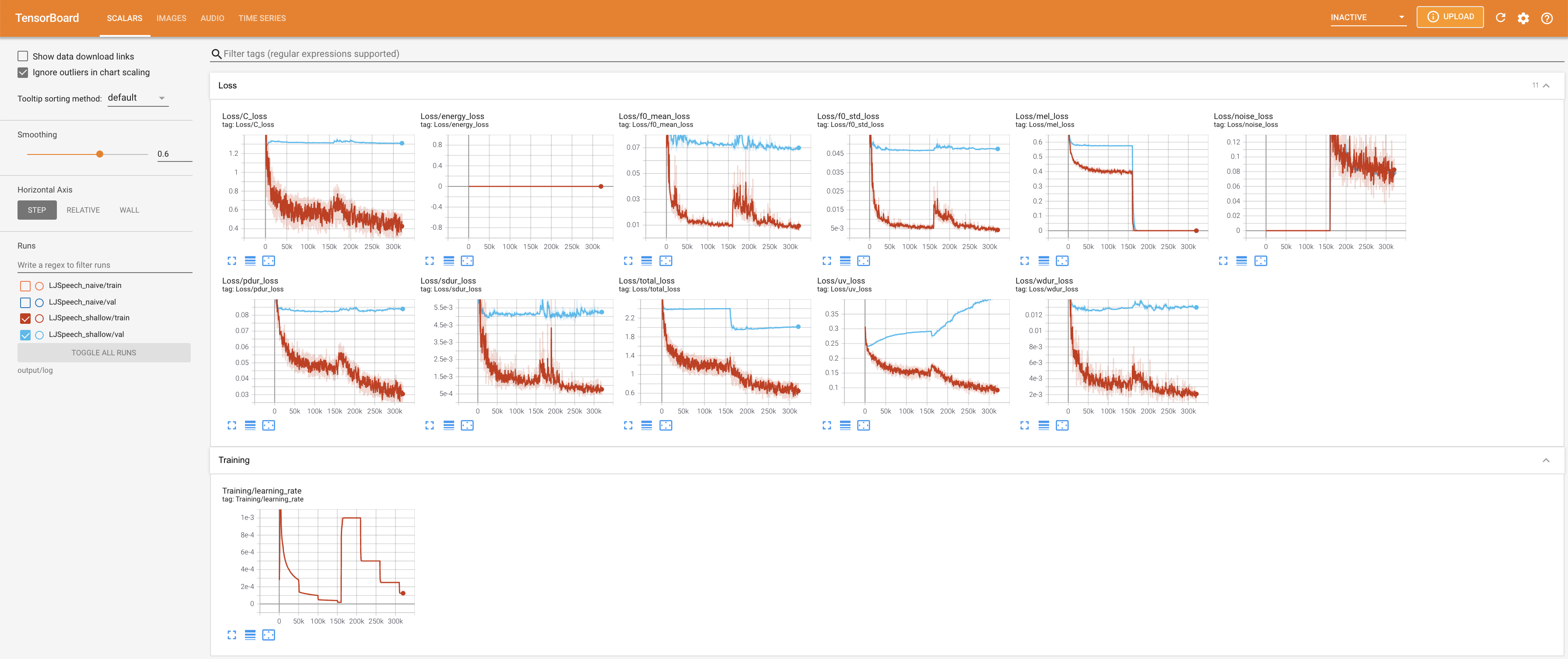
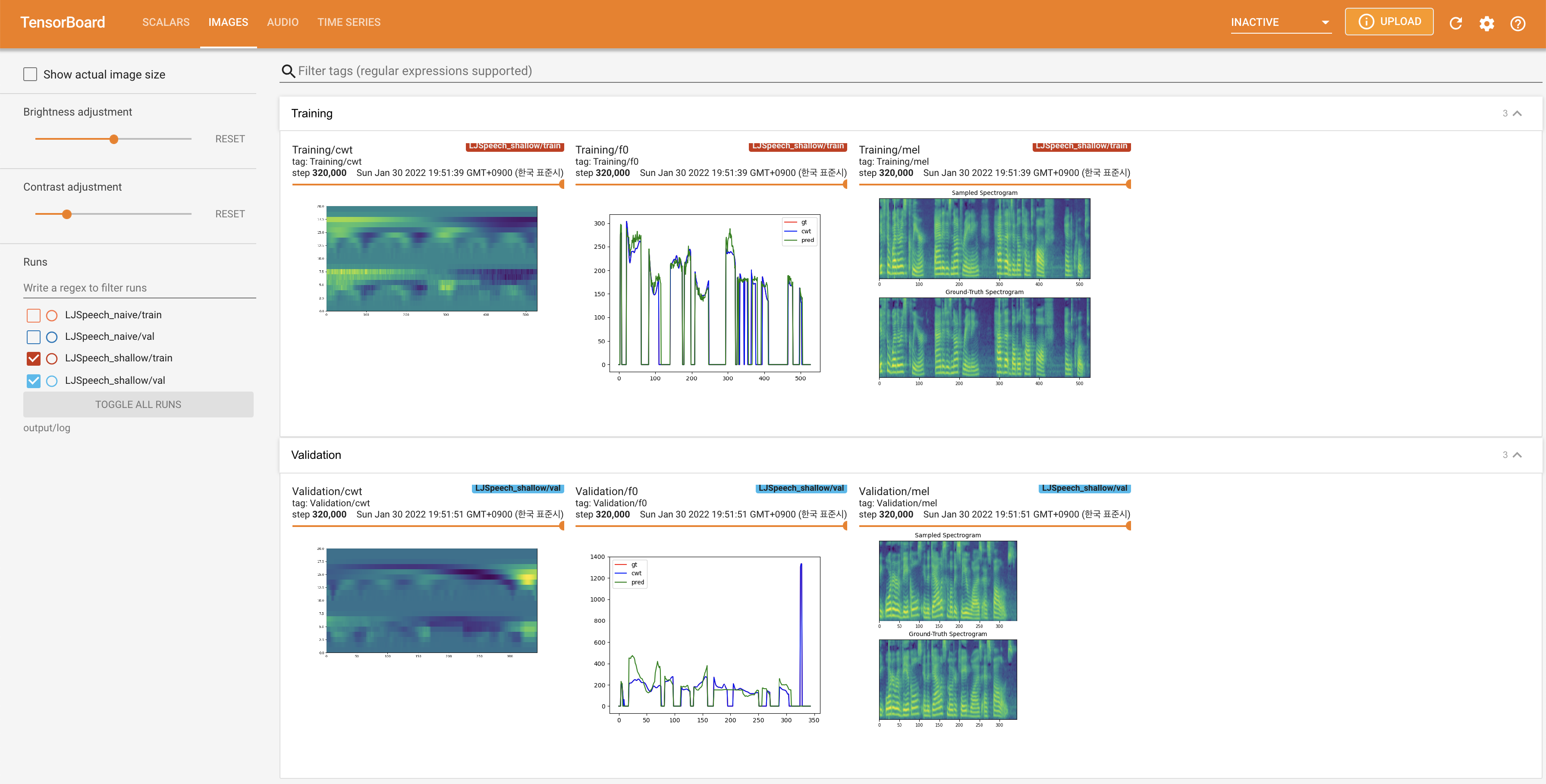
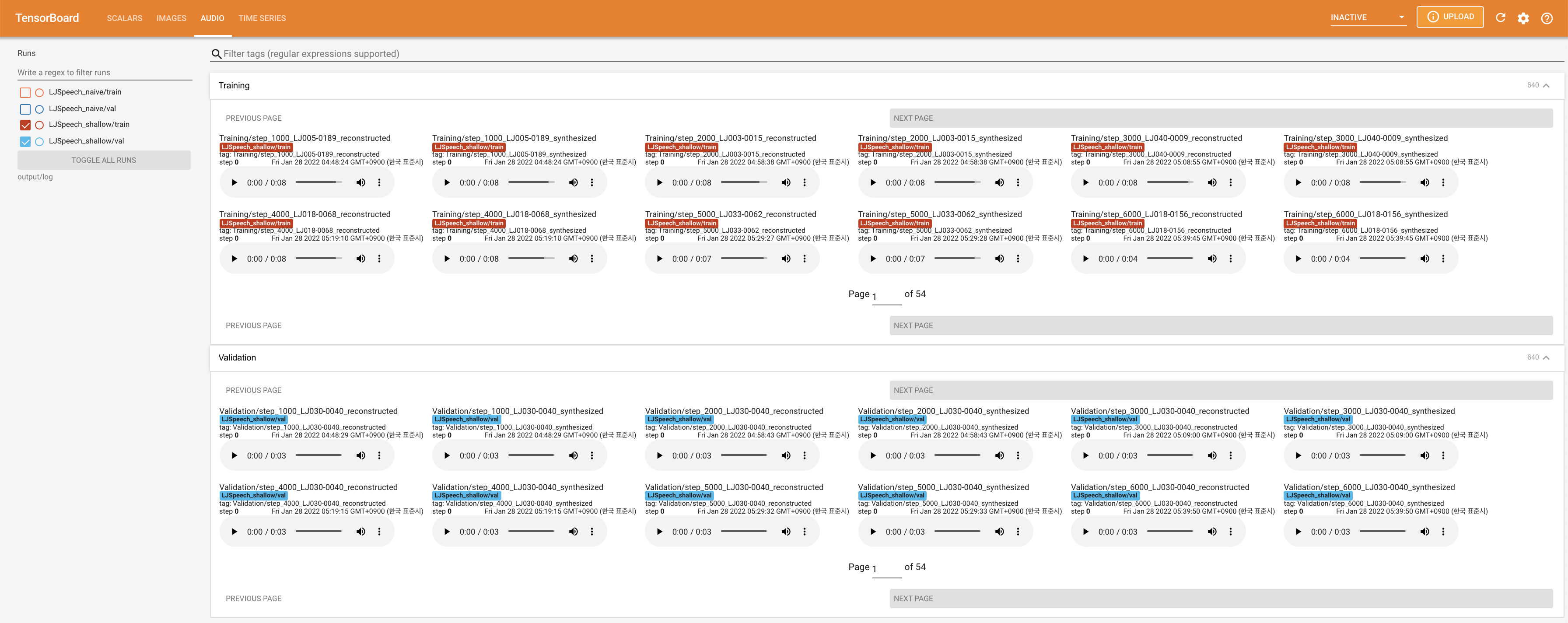
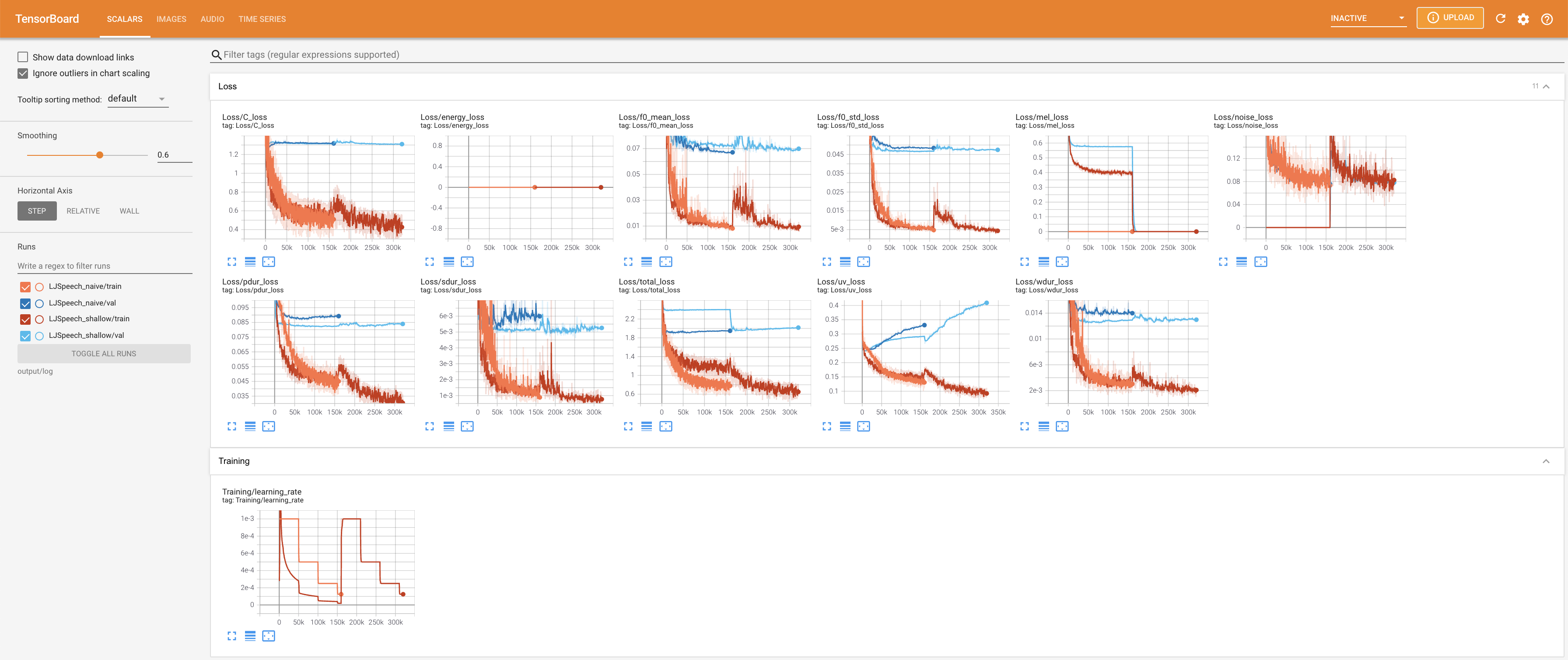
27.767M , que es similar al documento original ( 27.722M ).100 , que son los puntos de tiempo completos de la difusión ingenua para que no haya ventaja en los pasos de difusión. @misc{lee2021diffsinger,
author = {Lee, Keon},
title = {DiffSinger},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/DiffSinger}}
}


