DiffSinger
1.0.0
Implementasi PyTorch dari Diffsinger: menyanyikan sintesis suara melalui mekanisme difusi dangkal (difokuskan pada diffspeech).
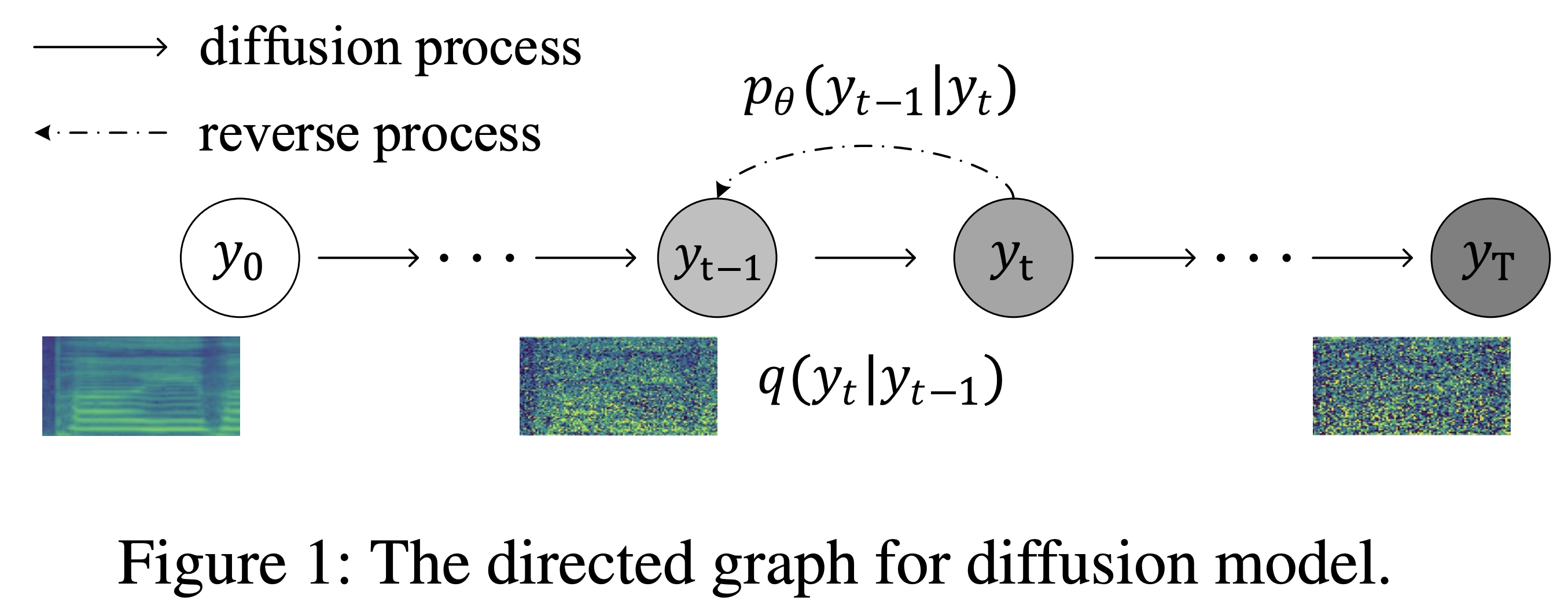
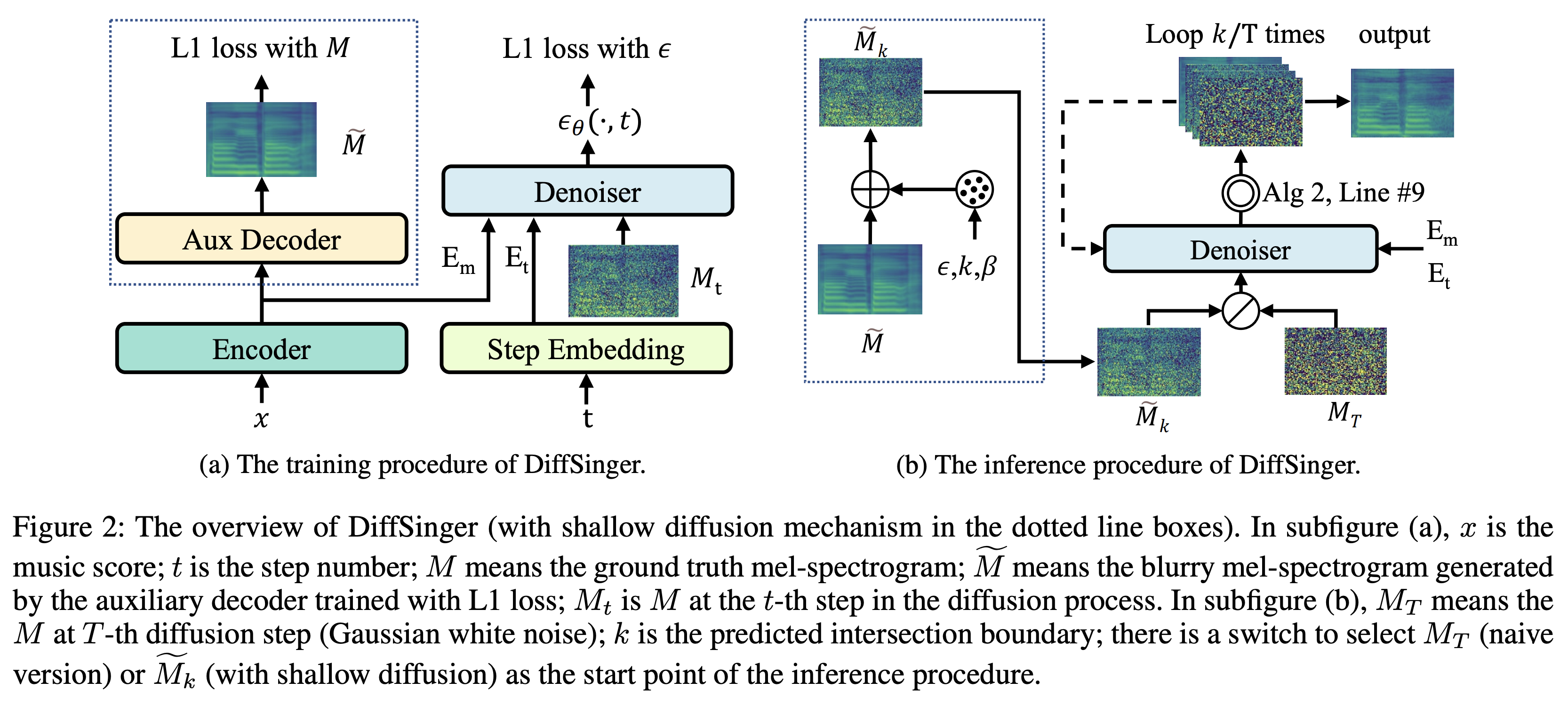
K K Sebagai Langkah Waktu Maksimum Dataset mengacu pada nama dataset seperti LJSpeech dalam dokumen berikut.
Model mengacu pada jenis model (pilih dari ' naif ', ' aux ', ' dangkal ').
Anda dapat menginstal dependensi Python dengan
pip3 install -r requirements.txt
Anda harus mengunduh model pretrained dan memasukkannya
output/ckpt/LJSpeech_naive/ untuk model ' naif '.output/ckpt/LJSpeech_shallow/ untuk model ' dangkal '. Harap dicatat bahwa pos pemeriksaan model ' dangkal ' berisi model ' dangkal ' dan ' aux ', dan kedua model ini akan berbagi semua direktori kecuali hasil di seluruh proses.Untuk TTS penutur tunggal bahasa Inggris, jalankan
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
Ucapan yang dihasilkan akan dimasukkan ke dalam output/result/ .
Inferensi batch juga didukung, coba
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
Untuk mensintesis semua ucapan di preprocessed_data/LJSpeech/val.txt .
Laju pitch/volume/berbicara dari ucapan yang disintesis dapat dikontrol dengan menentukan rasio pitch/energi/durasi yang diinginkan. Misalnya, seseorang dapat meningkatkan tingkat berbicara sebesar 20 % dan mengurangi volume sebesar 20 % dengan
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Harap dicatat bahwa kemampuan kontrol berasal dari FastSpeech2 dan bukan minat vital difspeech.
Dataset yang didukung adalah
Pertama, lari
python3 prepare_align.py --dataset DATASET
untuk beberapa persiapan.
Untuk penyelarasan paksa, Montreal memaksa Aligner (MFA) digunakan untuk mendapatkan keberpihakan antara ucapan dan urutan fonem. Penyelarasan yang telah diekstraksi untuk set data disediakan di sini. Anda harus membuka ritsleting file di preprocessed_data/DATASET/TextGrid/ . Bergantian, Anda dapat menjalankan pelurus sendiri.
Setelah itu, jalankan skrip preprocessing dengan
python3 preprocess.py --dataset DATASET
Anda dapat melatih tiga jenis model: ' naif ', ' aux ', dan ' dangkal '.
Melatih Versi Naif (' Naif '):
Latih versi naif dengan
python3 train.py --model naive --dataset DATASET
Pelatihan Decoder bantu untuk versi dangkal (' aux '):
Untuk melatih versi dangkal, kita membutuhkan fastspeech2 pra-terlatih. Perintah di bawah ini akan memungkinkan Anda melatih modul FastSpeech2, termasuk dekoder tambahan.
python3 train.py --model aux --dataset DATASET
Trik yang lebih mudah untuk prediksi batas:
Untuk mendapatkan batas K dari dataset validasi kami, Anda dapat menjalankan prediktor batas menggunakan FastSpeech2 tambahan yang terlatih dengan perintah berikut.
python3 boundary_predictor.py --restore_step RESTORE_STEP --dataset DATASET
Ini akan mencetak nilai yang diprediksi (katakanlah, K_STEP ) di log perintah.
Kemudian, atur konfigurasi dengan nilai yang diprediksi sebagai berikut
# In the model.yaml
denoiser :
K_step : K_STEPHarap dicatat bahwa ini didasarkan pada trik yang diperkenalkan dalam Lampiran B.
Pelatihan Versi Dangkal (' Dangkal '):
Untuk memanfaatkan FASTSPEECH2 pra-terlatih, termasuk Decoder Auxiliary, Anda harus mengatur restore_step dengan langkah terakhir pelatihan Auxiliary FastSpeech2 sebagai perintah berikut.
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
Misalnya, jika pos pemeriksaan terakhir disimpan pada 160000 langkah selama pelatihan tambahan, Anda harus mengatur restore_step dengan 160000 . Maka itu akan memuat model AUX dan kemudian melanjutkan pelatihan di bawah mekanisme pelatihan yang dangkal.
Menggunakan
tensorboard --logdir output/log/LJSpeech
untuk melayani Tensorboard di Localhost Anda. Kurva kehilangan, sintesis mel-spectrograms, dan audio ditampilkan.
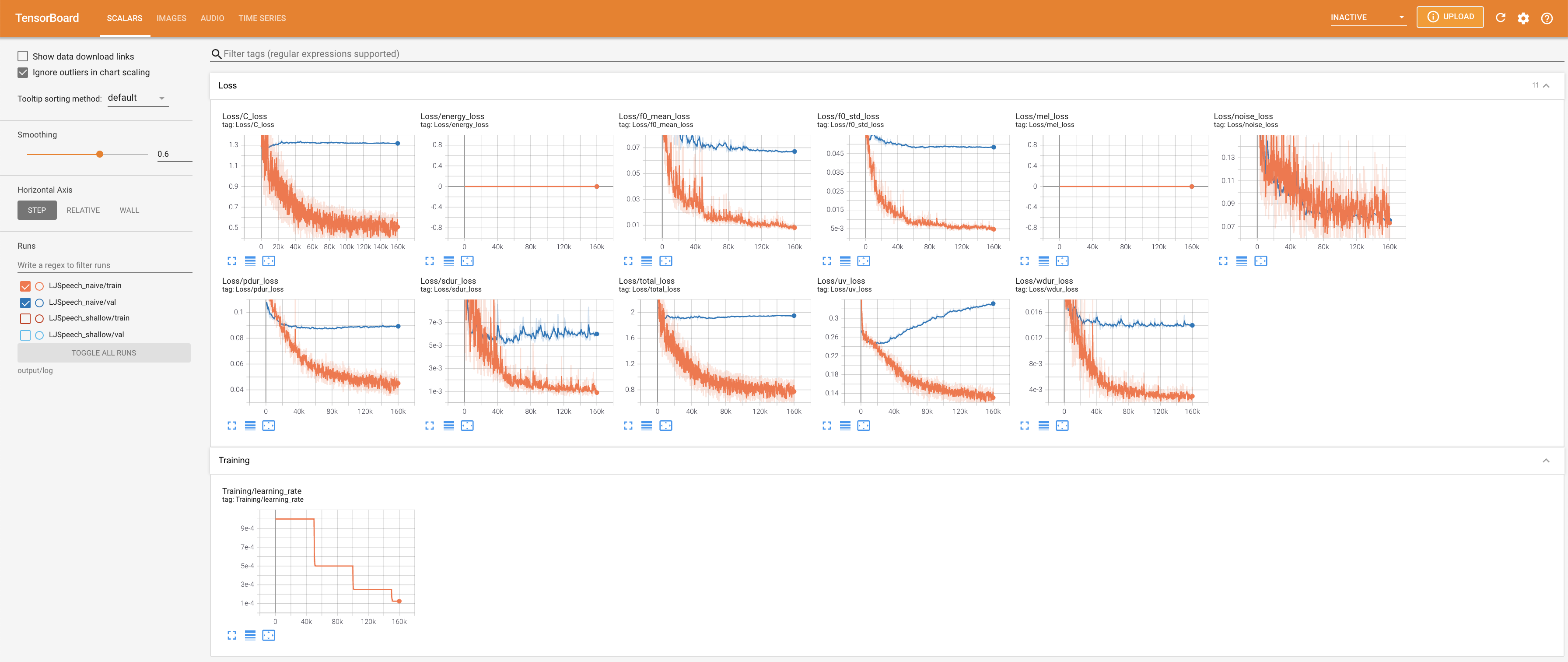
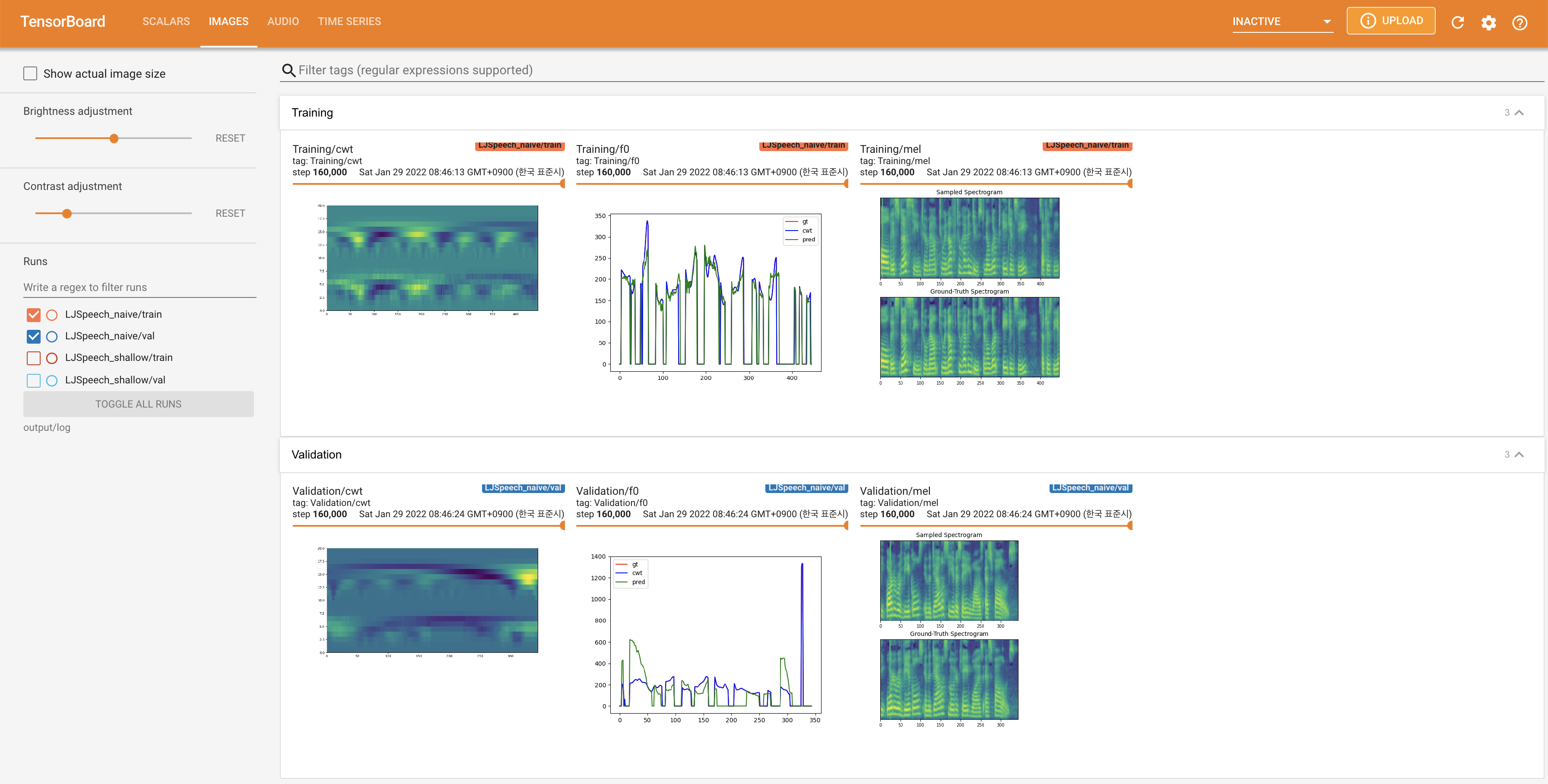
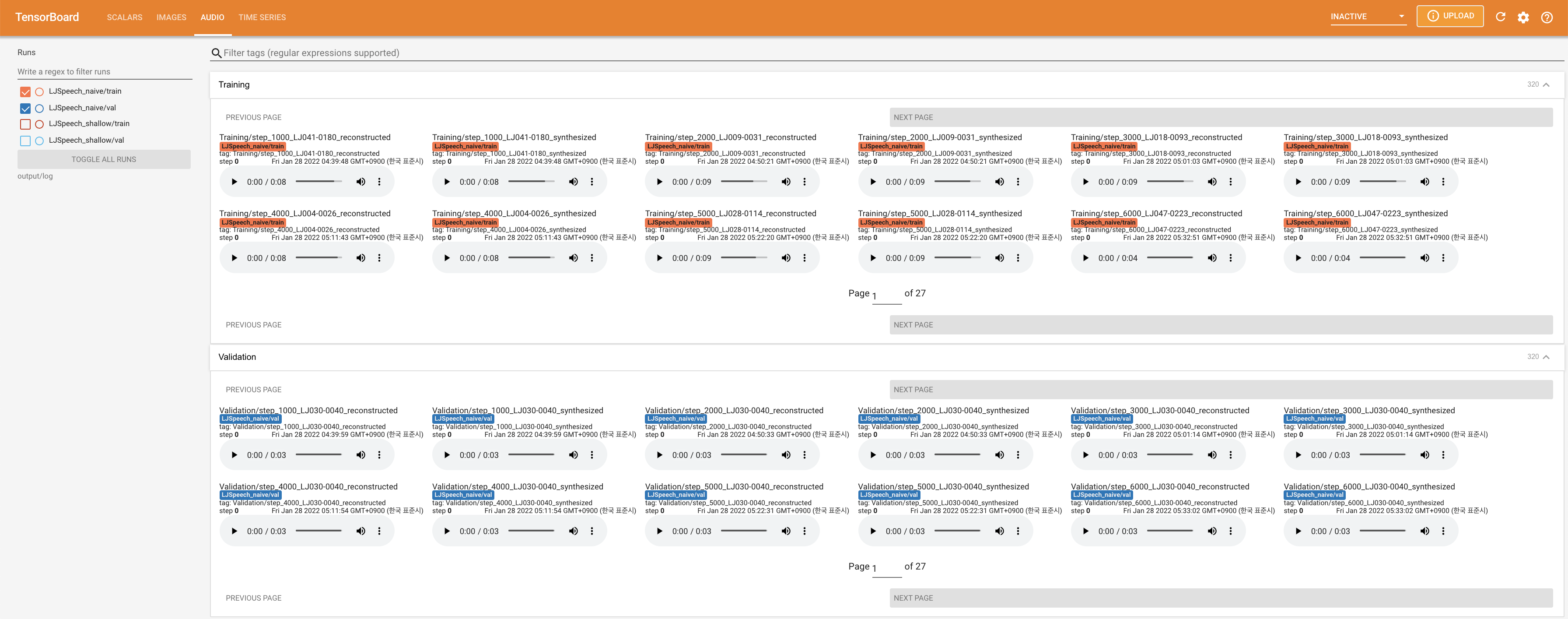
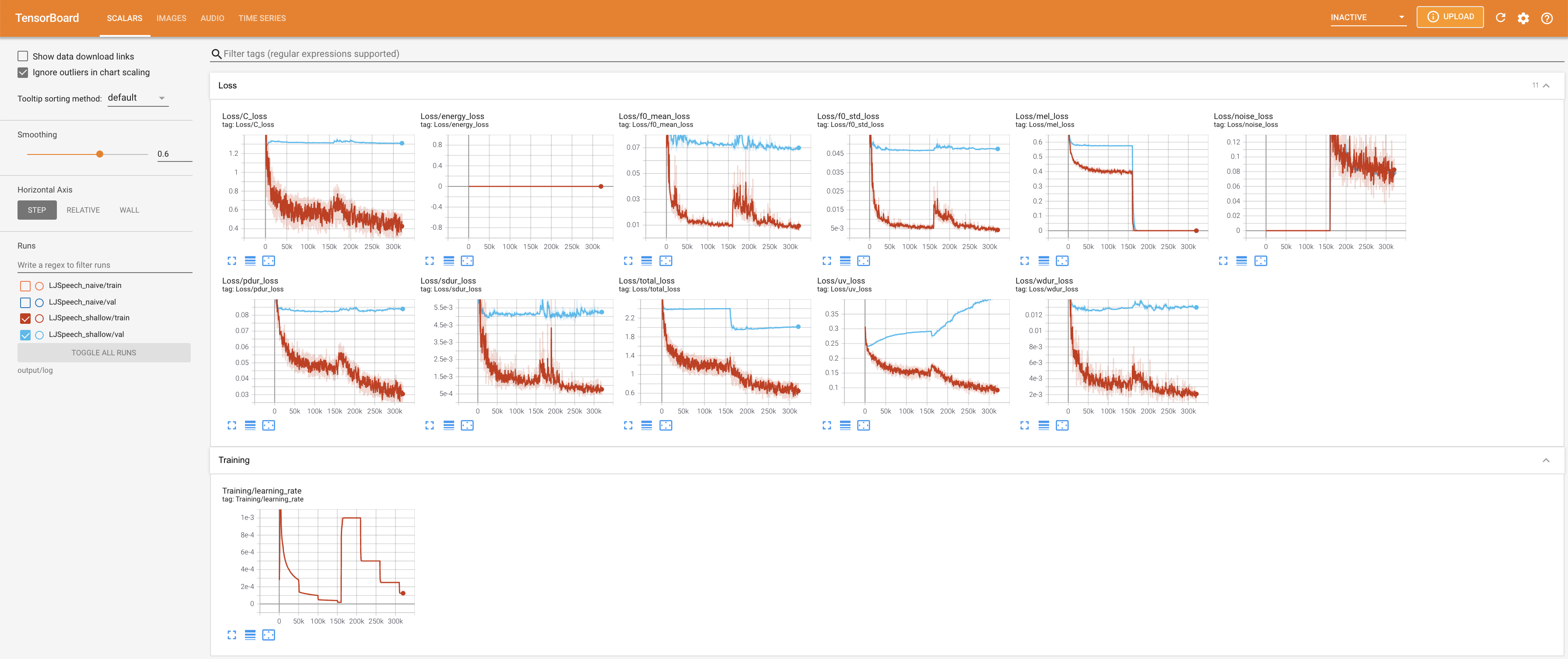
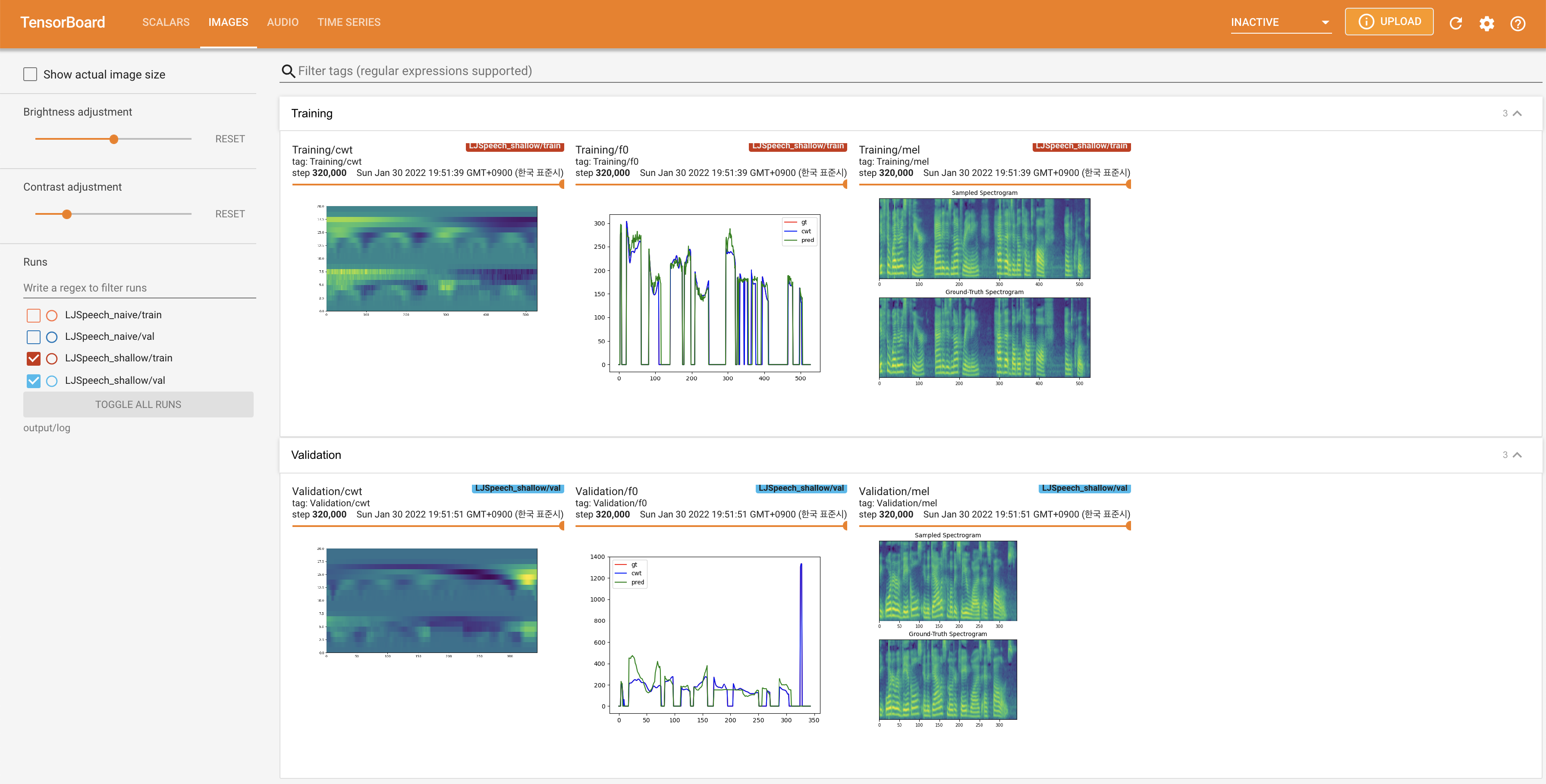
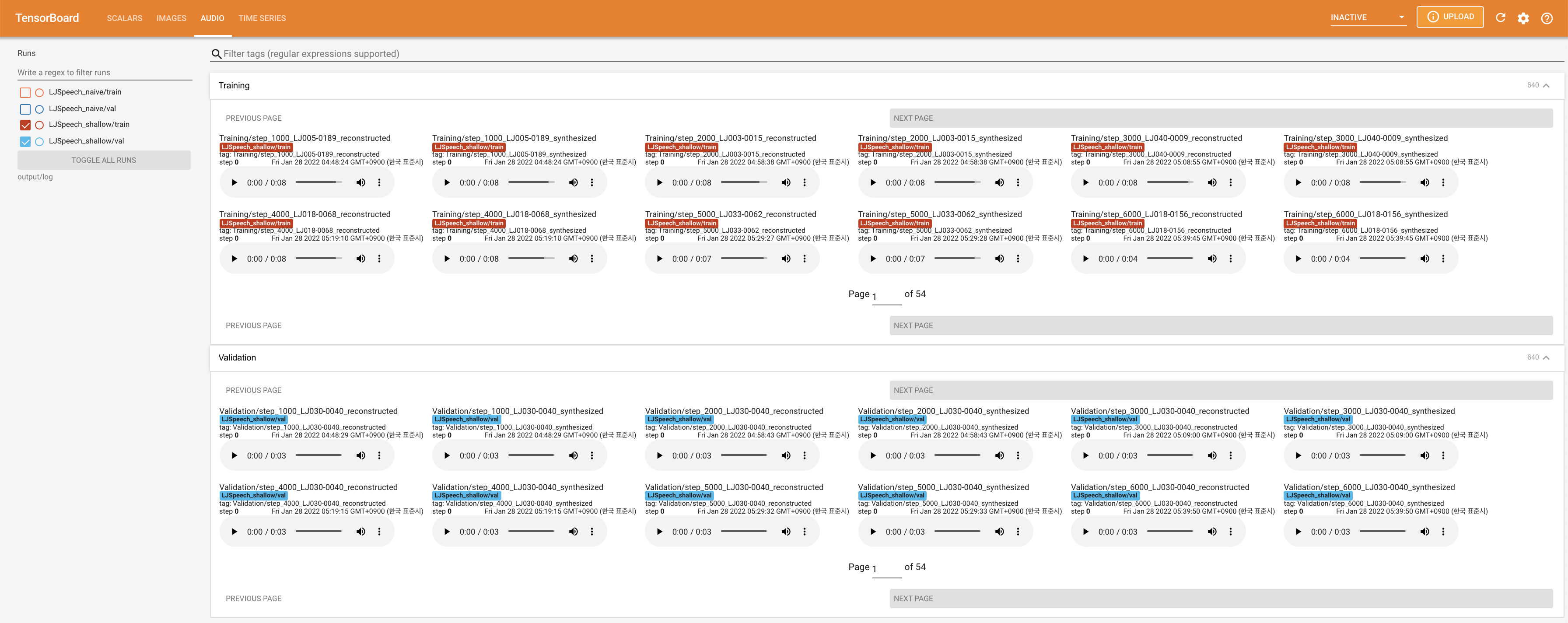
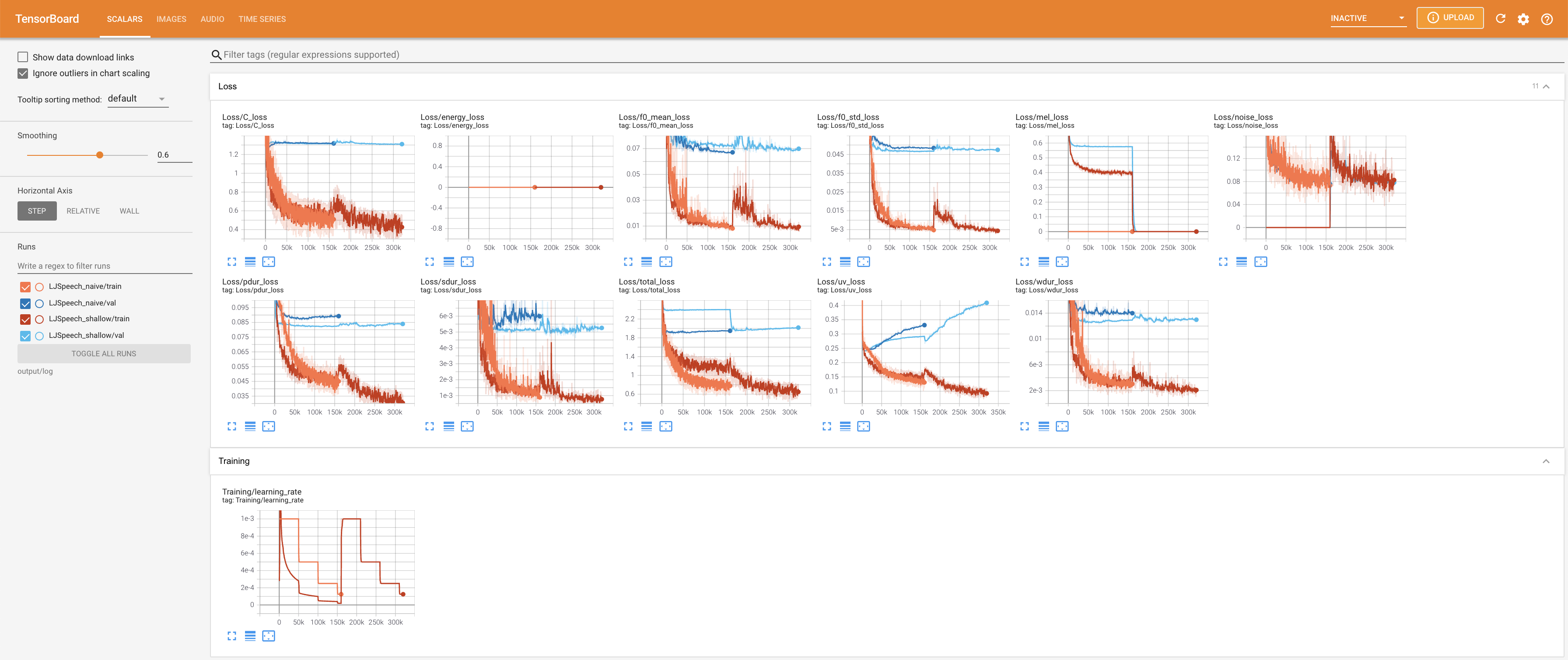
27.767M , yang mirip dengan kertas asli ( 27.722M ).100 , yang merupakan waktu penuh dari difusi naif sehingga tidak ada keuntungan pada langkah difusi. @misc{lee2021diffsinger,
author = {Lee, Keon},
title = {DiffSinger},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/DiffSinger}}
}


