DiffSinger
1.0.0
Pytorch Implémentation de Diffsinger: Singing Voice Synthesis via un mécanisme de diffusion superficiel (axé sur la diffspeech).
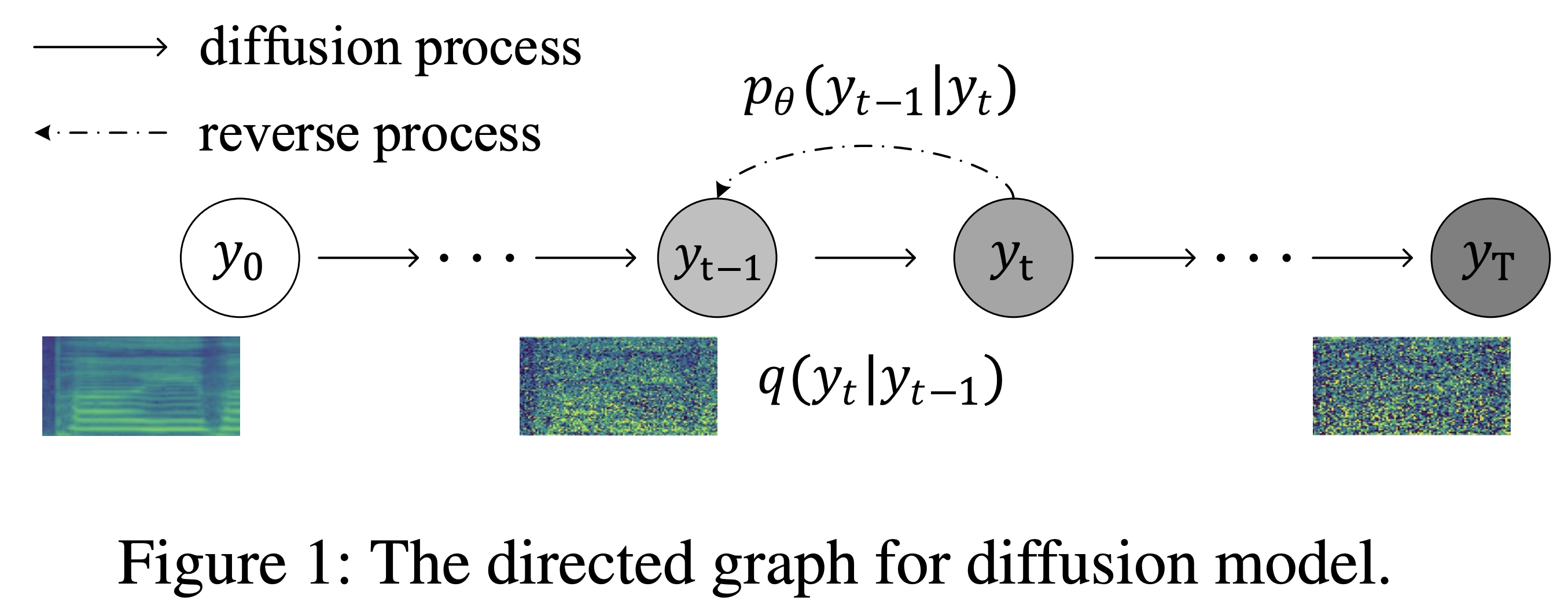
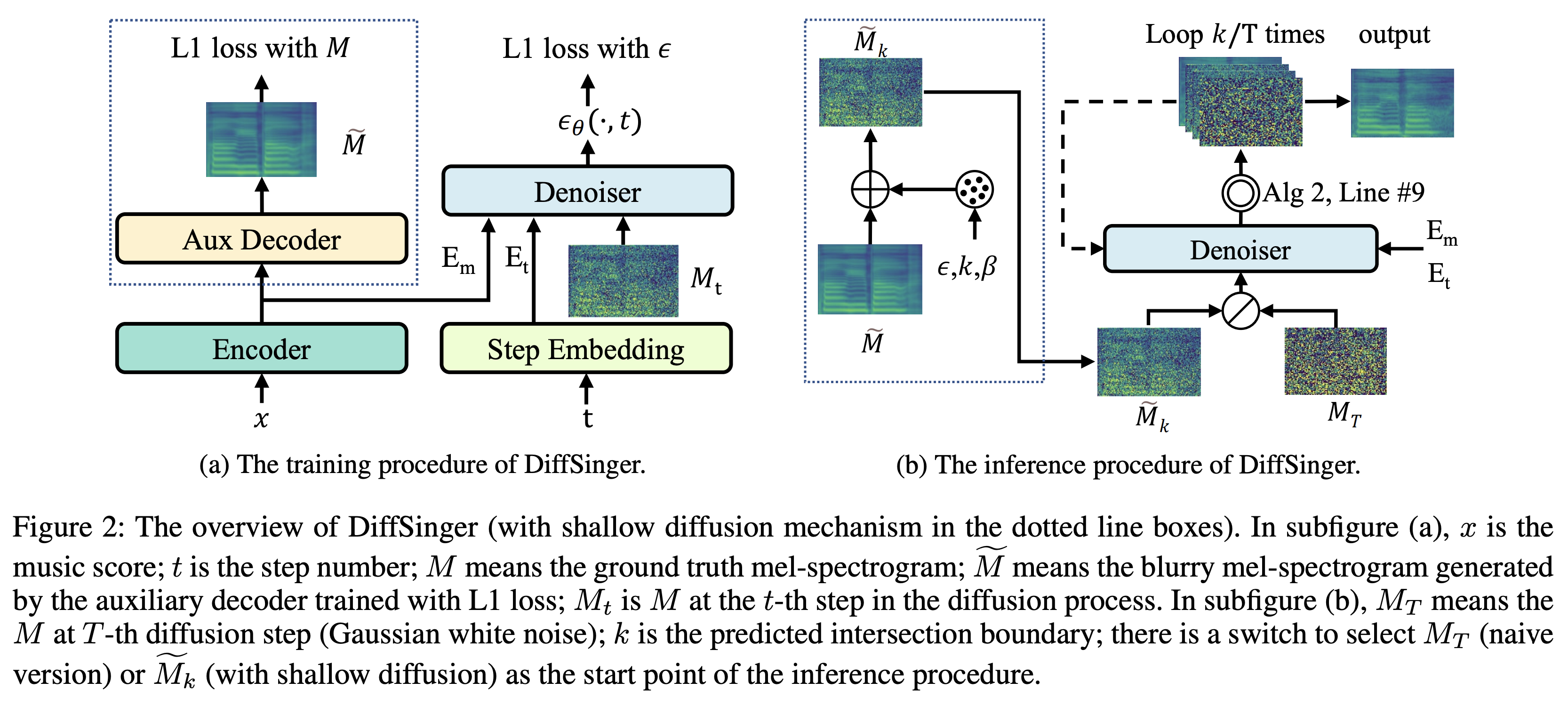
K K comme pas de temps maximum L'ensemble de données fait référence aux noms des ensembles de données tels que LJSpeech dans les documents suivants.
Le modèle fait référence aux types de modèle (choisissez parmi « naïf », « aux », « superficiel »).
Vous pouvez installer les dépendances Python avec
pip3 install -r requirements.txt
Vous devez télécharger les modèles pré-entraînés et les mettre
output/ckpt/LJSpeech_naive/ pour le modèle « naïf ».output/ckpt/LJSpeech_shallow/ pour le modèle « peu profond ». Veuillez noter que le point de contrôle du modèle « peu profond » contient à la fois des modèles « peu profonds » et « AUX », et ces deux modèles partageront tous les répertoires, sauf les résultats tout au long du processus.Pour les TTS à haut-parleur anglais, courez
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
Les énoncés générés seront placés en output/result/ .
L'inférence par lots est également prise en charge, essayez
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
Pour synthétiser toutes les énoncés dans preprocessed_data/LJSpeech/val.txt .
La hauteur / volume / le taux de parole des énoncés synthétisés peut être contrôlé en spécifiant les rapports de pitch / énergie / durée souhaités. Par exemple, on peut augmenter le taux de parole de 20% et diminuer le volume de 20% par
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Veuillez noter que la contrôlabilité est originaire de FastSpeech2 et non un intérêt vital de la diffspeech.
Les ensembles de données pris en charge sont
Tout d'abord, courez
python3 prepare_align.py --dataset DATASET
pour certaines préparatifs.
Pour l'alignement forcé, l'aligneur forcé de Montréal (MFA) est utilisé pour obtenir les alignements entre les énoncés et les séquences de phonèmes. Les alignements pré-extractés pour les ensembles de données sont fournis ici. Vous devez décompresser les fichiers dans preprocessed_data/DATASET/TextGrid/ . Alternativement, vous pouvez exécuter l'aligneur par vous-même.
Après cela, exécutez le script de prétraitement par
python3 preprocess.py --dataset DATASET
Vous pouvez former trois types de modèle: « naïf », « aux » et « peu profonds ».
Formation Version naïve (« naïve »):
Former la version naïve avec
python3 train.py --model naive --dataset DATASET
Formation Decoder auxiliaire pour la version peu profonde (« AUX »):
Pour entraîner la version peu profonde, nous avons besoin d'un FastSpeech2 pré-formé. La commande ci-dessous vous permettra de former les modules FastSpeech2, y compris le décodeur auxiliaire.
python3 train.py --model aux --dataset DATASET
Une astuce plus facile pour la prédiction des limites:
Pour obtenir la limite K de notre ensemble de données de validation, vous pouvez exécuter le prédicteur de la limite en utilisant FastSpeech2 auxiliaire pré-formé par la commande suivante.
python3 boundary_predictor.py --restore_step RESTORE_STEP --dataset DATASET
Il imprimera la valeur prévue (disons, K_STEP ) dans le journal des commandes.
Ensuite, définissez la configuration avec la valeur prévue comme suit
# In the model.yaml
denoiser :
K_step : K_STEPVeuillez noter que cela est basé sur l'astuce introduite à l'annexe B.
Formation Version superficielle (« superficielle »):
Pour tirer parti de FastSpeech2 pré-formé, y compris le décodeur auxiliaire, vous devez définir restore_step avec la dernière étape de la formation Auxiliaire FastSpeech2 comme la commande suivante.
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
Par exemple, si le dernier point de contrôle est enregistré à 160000 étapes pendant la formation auxiliaire, vous devez définir restore_step avec 160000 . Ensuite, il chargera le modèle AUX, puis continuera la formation sous un mécanisme de formation peu profond.
Utiliser
tensorboard --logdir output/log/LJSpeech
pour servir Tensorboard sur votre hôte local. Les courbes de perte, les spectrogrammes de MEL synthétisés et les audios sont affichés.
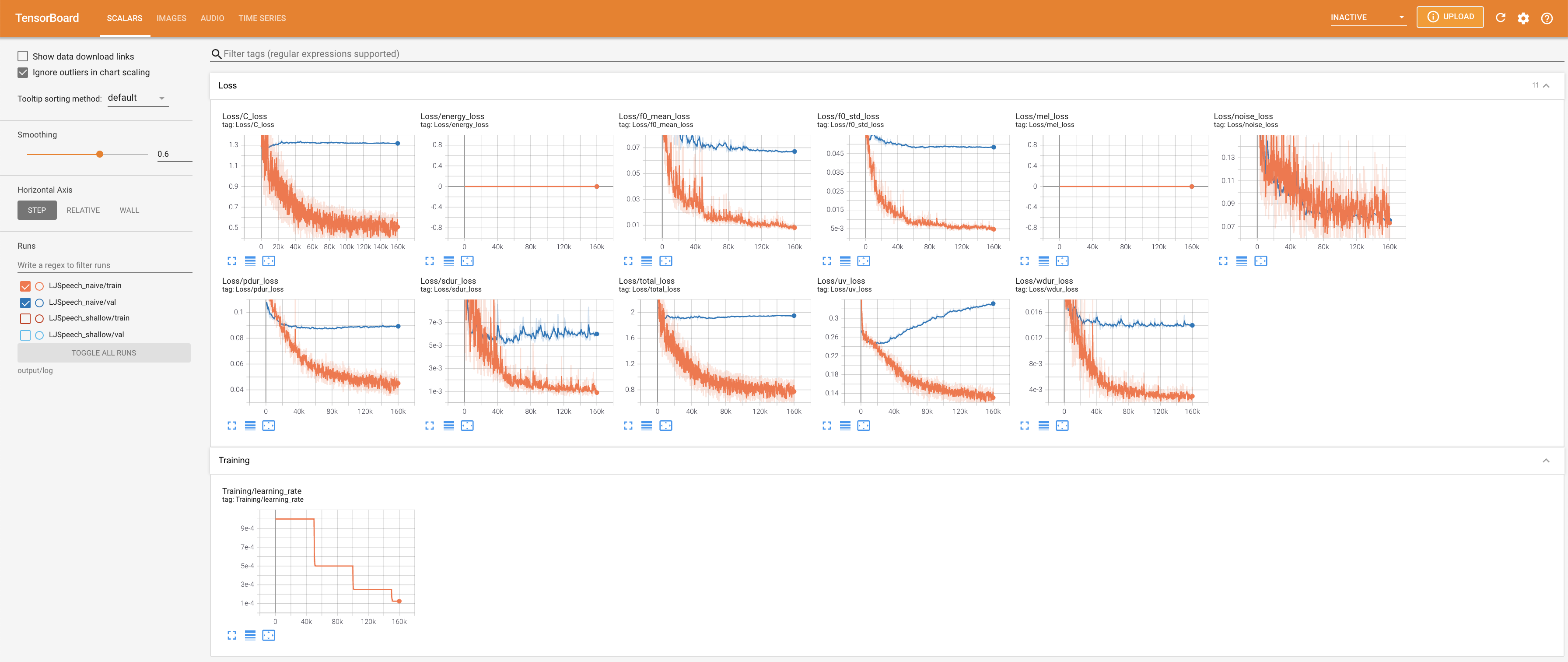
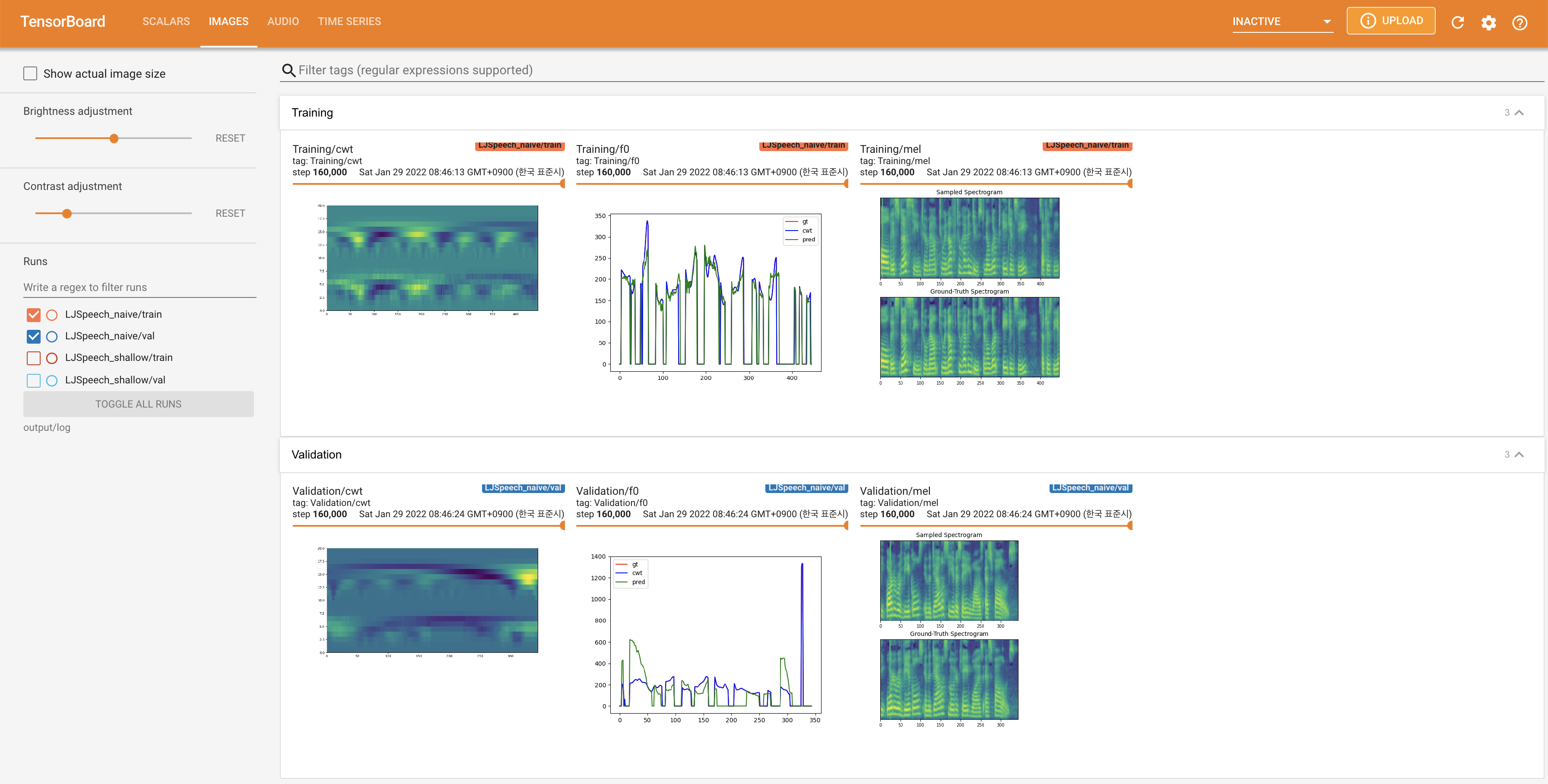
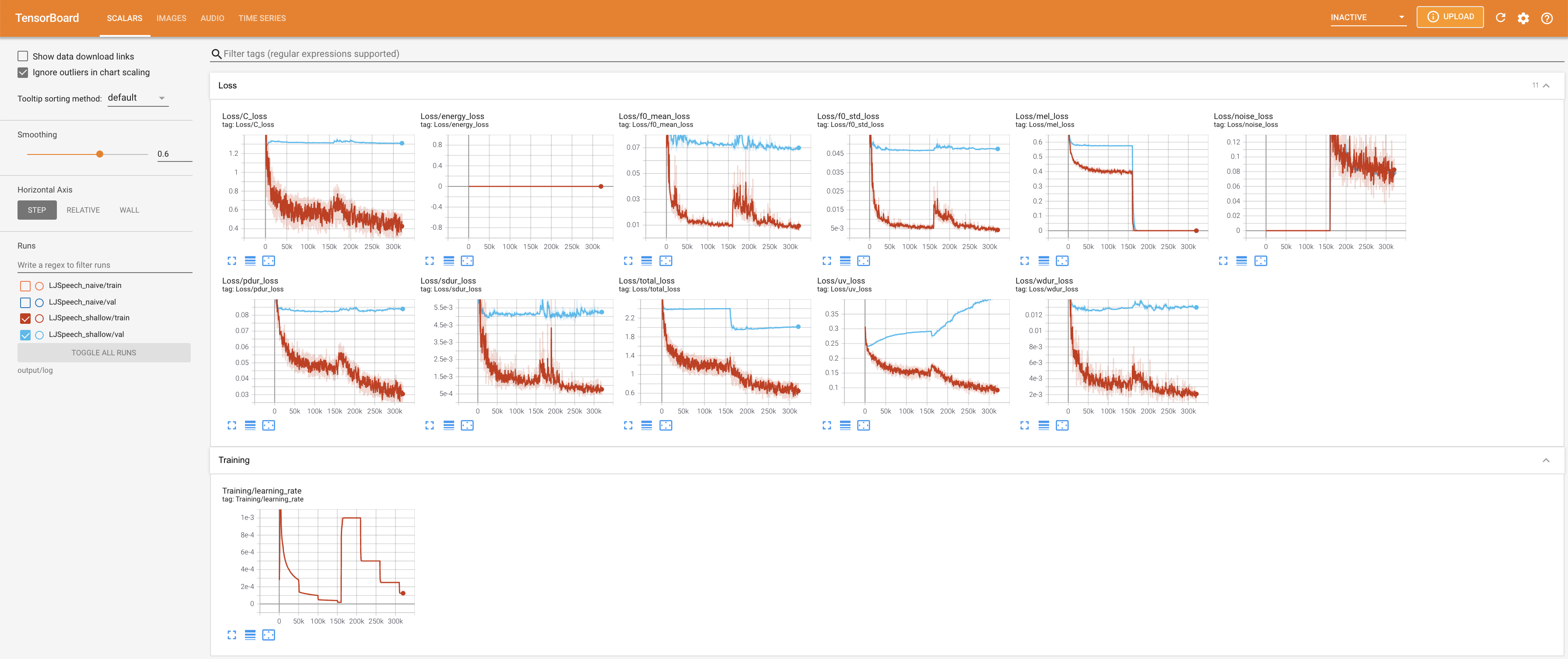
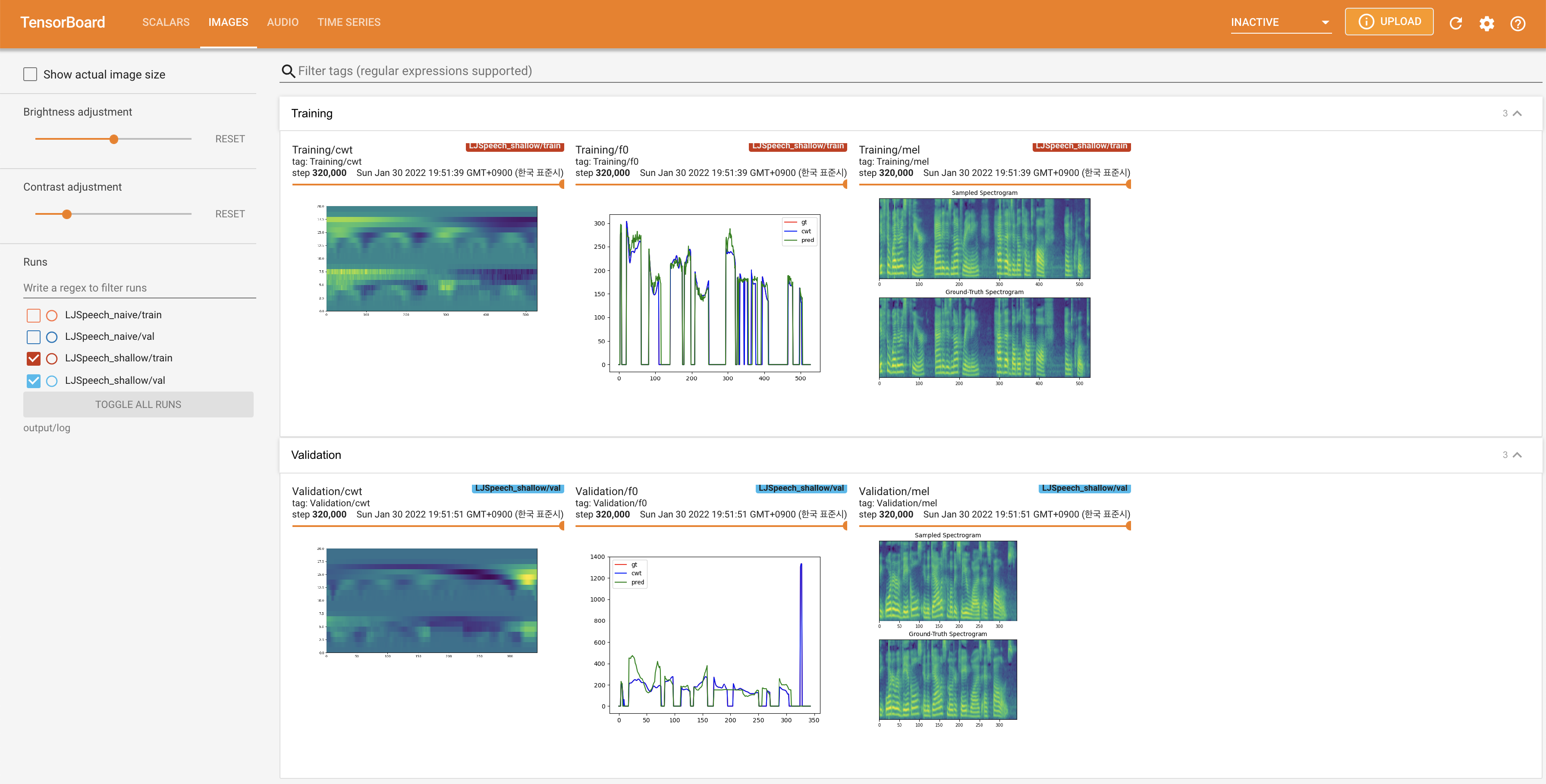
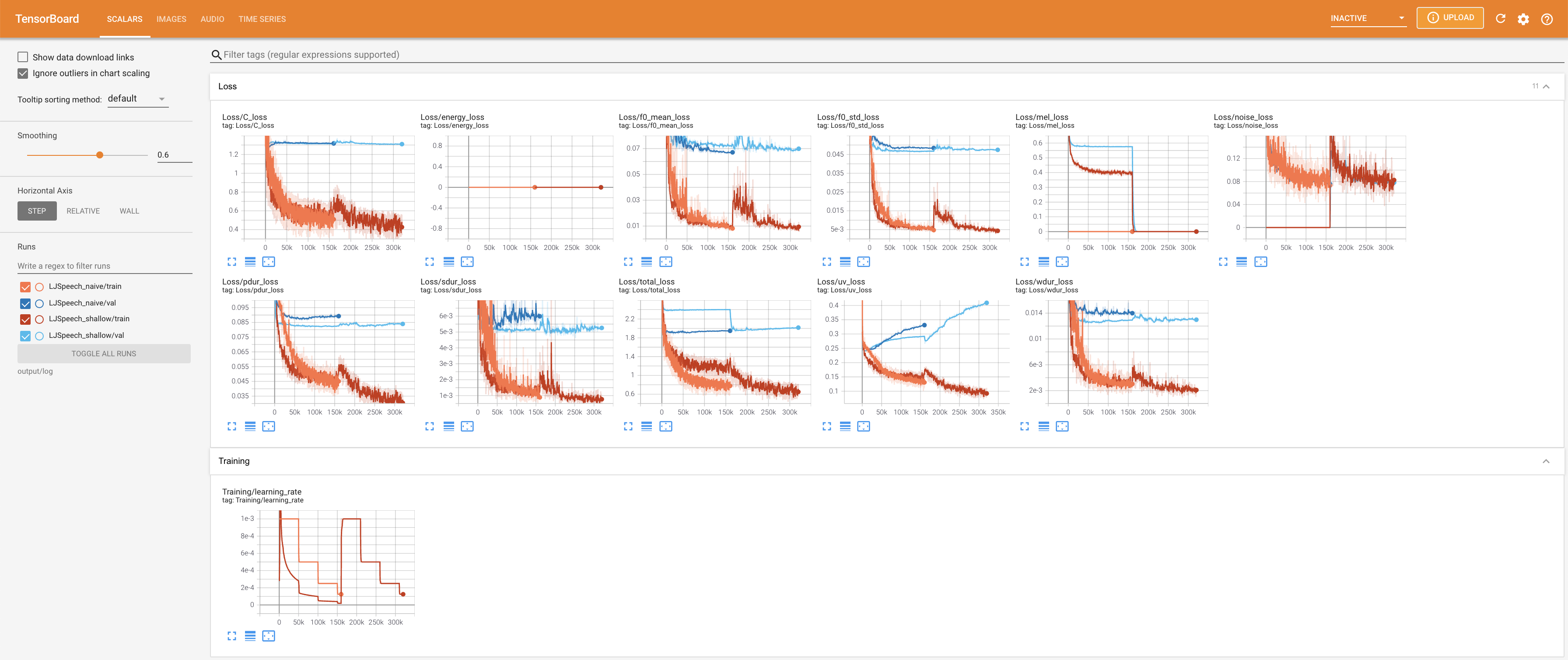
27.767M , ce qui est similaire au papier d'origine ( 27.722M ).100 , ce qui est le temps complet de la diffusion naïve afin qu'il n'y ait aucun avantage sur les étapes de diffusion. @misc{lee2021diffsinger,
author = {Lee, Keon},
title = {DiffSinger},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/DiffSinger}}
}


