DiffSinger
1.0.0
Pytorch -Implementierung von Diffsinger: Singen der Sprachsynthese über einen flachen Diffusionsmechanismus (konzentriert auf Diffspeech).
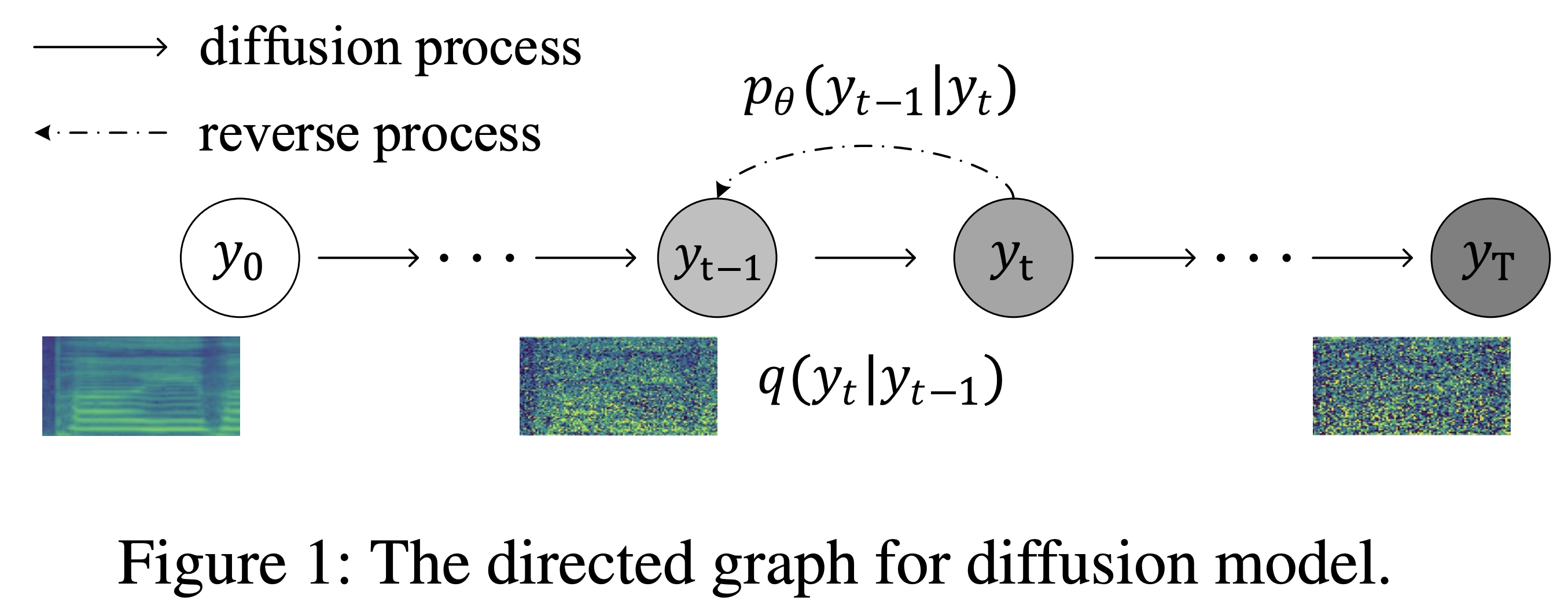
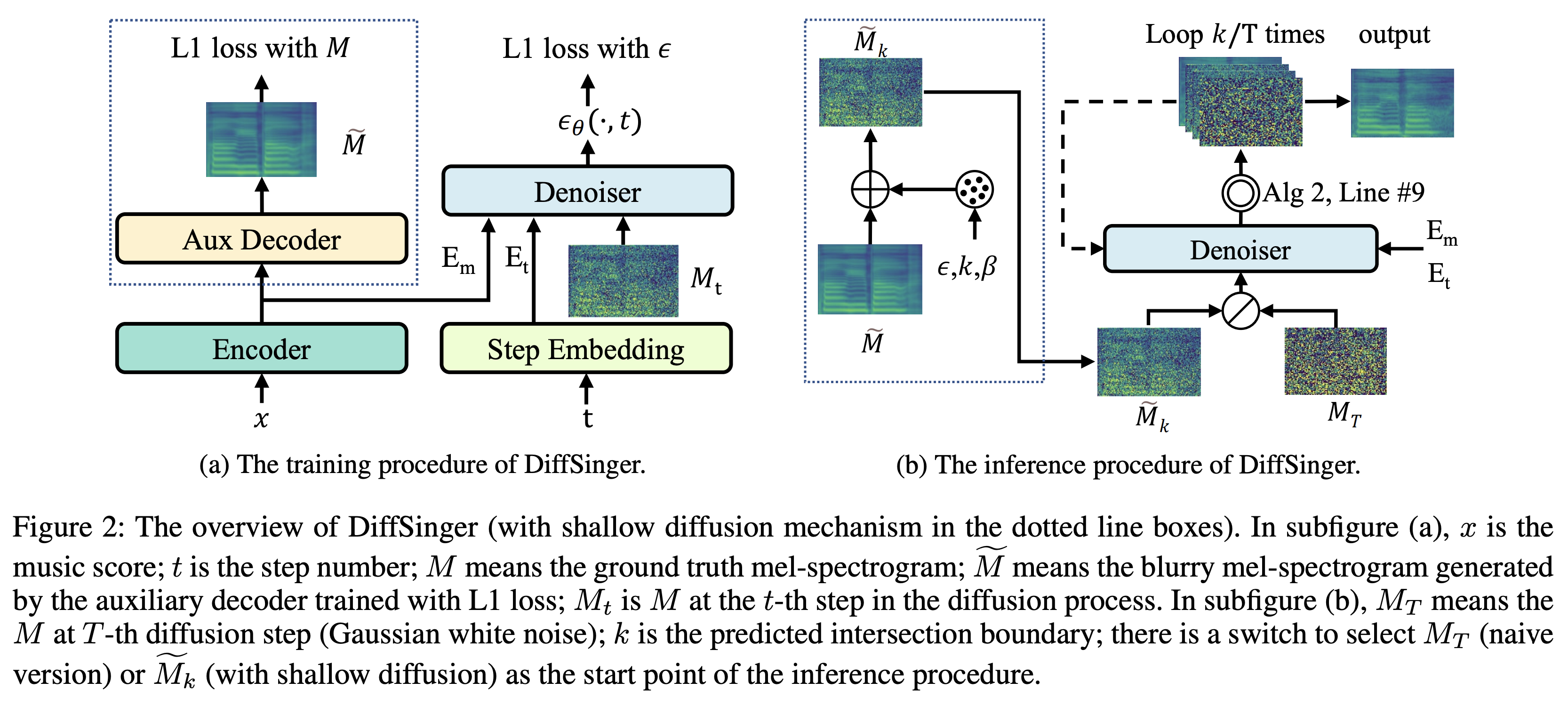
K K als maximale Zeitschritt Datensatz bezieht sich auf die Namen von Datensätzen wie LJSpeech in den folgenden Dokumenten.
Das Modell bezieht sich auf die Arten von Modell (wählen Sie aus " Naive ", " aux ", " flach ").
Sie können die Python -Abhängigkeiten mit installieren
pip3 install -r requirements.txt
Sie müssen die vorbereiteten Modelle herunterladen und sie einsetzen
output/ckpt/LJSpeech_naive/ für ' naive ' Modell.output/ckpt/LJSpeech_shallow/ für ' flaches ' Modell. Bitte beachten Sie, dass der Kontrollpunkt des " flachen " Modells sowohl " flache " als auch " Aux " -Modelle enthält, und diese beiden Modelle teilen alle Verzeichnisse mit Ausnahme der Ergebnisse im gesamten Prozess.Für englische TTS mit Single-Lautsprechern laufen Sie
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
Die erzeugten Äußerungen werden in output/result/ .
Batch -Inferenz wird ebenfalls unterstützt, versuchen Sie es
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
So synthetisieren Sie alle Äußerungen in preprocessed_data/LJSpeech/val.txt .
Die Tonhöhe/Volumen-/Sprechrate der synthetisierten Äußerungen kann durch Angabe der gewünschten Pitch/Energy/Dauer -Verhältnisse gesteuert werden. Zum Beispiel kann man die Sprechrate um 20 % erhöhen und das Volumen um 20 % verringern
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Bitte beachten Sie, dass die Kontrollierbarkeit aus Fastspeech2 und kein wesentliches Interesse an Diffspeech stammt.
Die unterstützten Datensätze sind
Zunächst rennen
python3 prepare_align.py --dataset DATASET
Für einige Vorbereitungen.
Für die erzwungene Ausrichtung wird Montreal erzwungene Aligner (MFA) verwendet, um die Ausrichtungen zwischen den Äußerungen und den Phonemsequenzen zu erhalten. Vorextrahierte Ausrichtungen für die Datensätze werden hier bereitgestellt. Sie müssen die Dateien in preprocessed_data/DATASET/TextGrid/ entpacken. Alternativ können Sie den Aligner selbst ausführen.
Führen Sie danach das Vorverarbeitungskript durch
python3 preprocess.py --dataset DATASET
Sie können drei Arten von Modellen trainieren: " naiv ", " aux " und " flach ".
Training naive Version (' naive '):
Trainieren Sie die naive Version mit
python3 train.py --model naive --dataset DATASET
Trainingshilfsdecoder für flache Version (' Aux '):
Um die flache Version zu trainieren, benötigen wir einen vorgebliebenen Fastspeech22. Mit dem folgenden Befehl können Sie die Fastspeech2 -Module, einschließlich Auxiliary Decoder, trainieren.
python3 train.py --model aux --dataset DATASET
Ein einfacher Trick für die Grenzvorhersage:
Um die Grenze K aus unserem Validierungsdatensatz zu erhalten, können Sie den Grenzprädiktor mithilfe von PreAnrained Auxiliary Fastspeech2 mit dem folgenden Befehl ausführen.
python3 boundary_predictor.py --restore_step RESTORE_STEP --dataset DATASET
Es wird den vorhergesagten Wert (z. B. K_STEP ) im Befehlsprotokoll ausdrucken.
Stellen Sie dann die Konfiguration mit dem vorhergesagten Wert wie folgt ein
# In the model.yaml
denoiser :
K_step : K_STEPBitte beachten Sie, dass dies auf dem in Anhang B eingeführten Trick basiert
Training flache Version (' flach '):
Um vorgeborenes Fastspeech2, einschließlich Auxiliary Decoder, zu nutzen, müssen Sie restore_step mit dem letzten Schritt des Hilfstrainings Fastspeech2 als folgenden Befehl festlegen.
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
Wenn der letzte Kontrollpunkt beispielsweise während des Hilfstrainings bei 160000 Schritten gespeichert wird, müssen Sie restore_step mit 160000 festlegen. Dann lädt es das Aux -Modell und setzt dann das Training unter einem flachen Trainingsmechanismus fort.
Verwenden
tensorboard --logdir output/log/LJSpeech
Tensorboard auf Ihrem örtlichen Haus servieren. Die Verlustkurven, synthetisierte Melspektrogramme und Audios werden gezeigt.
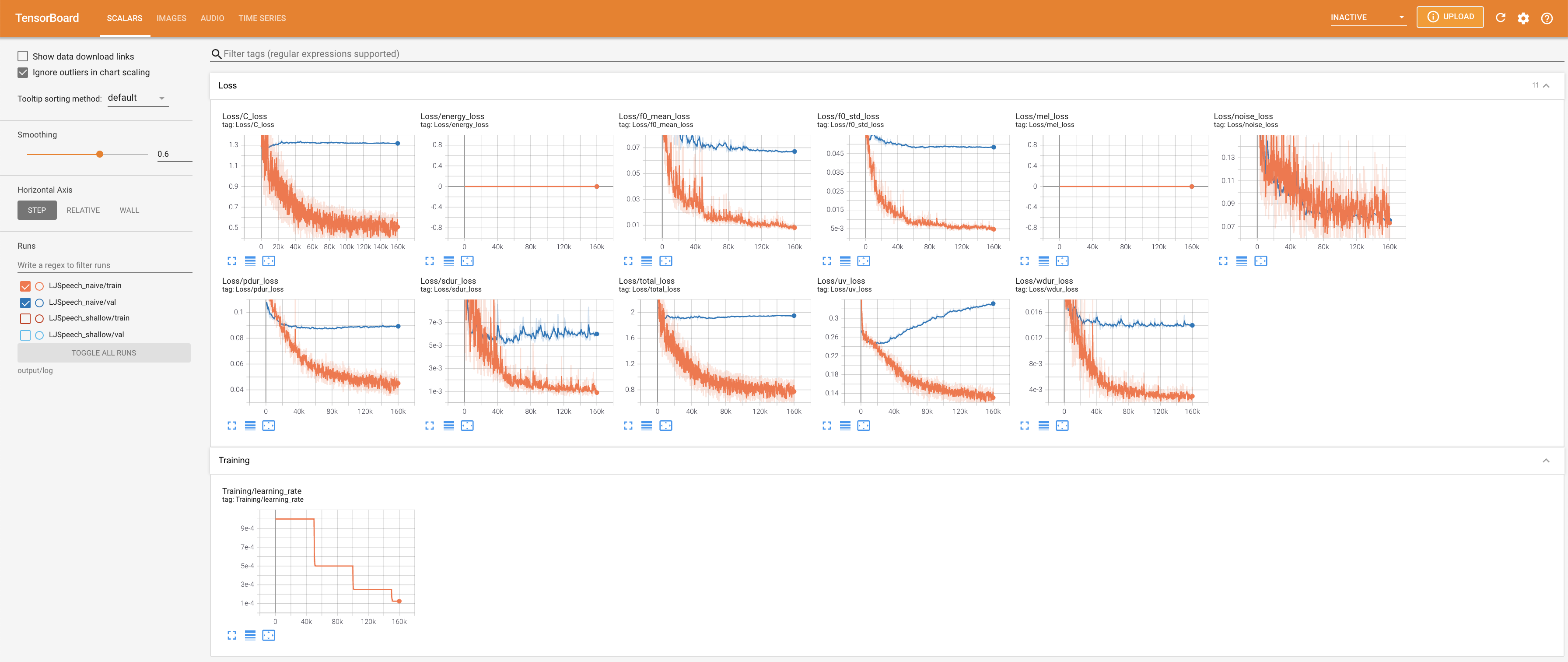
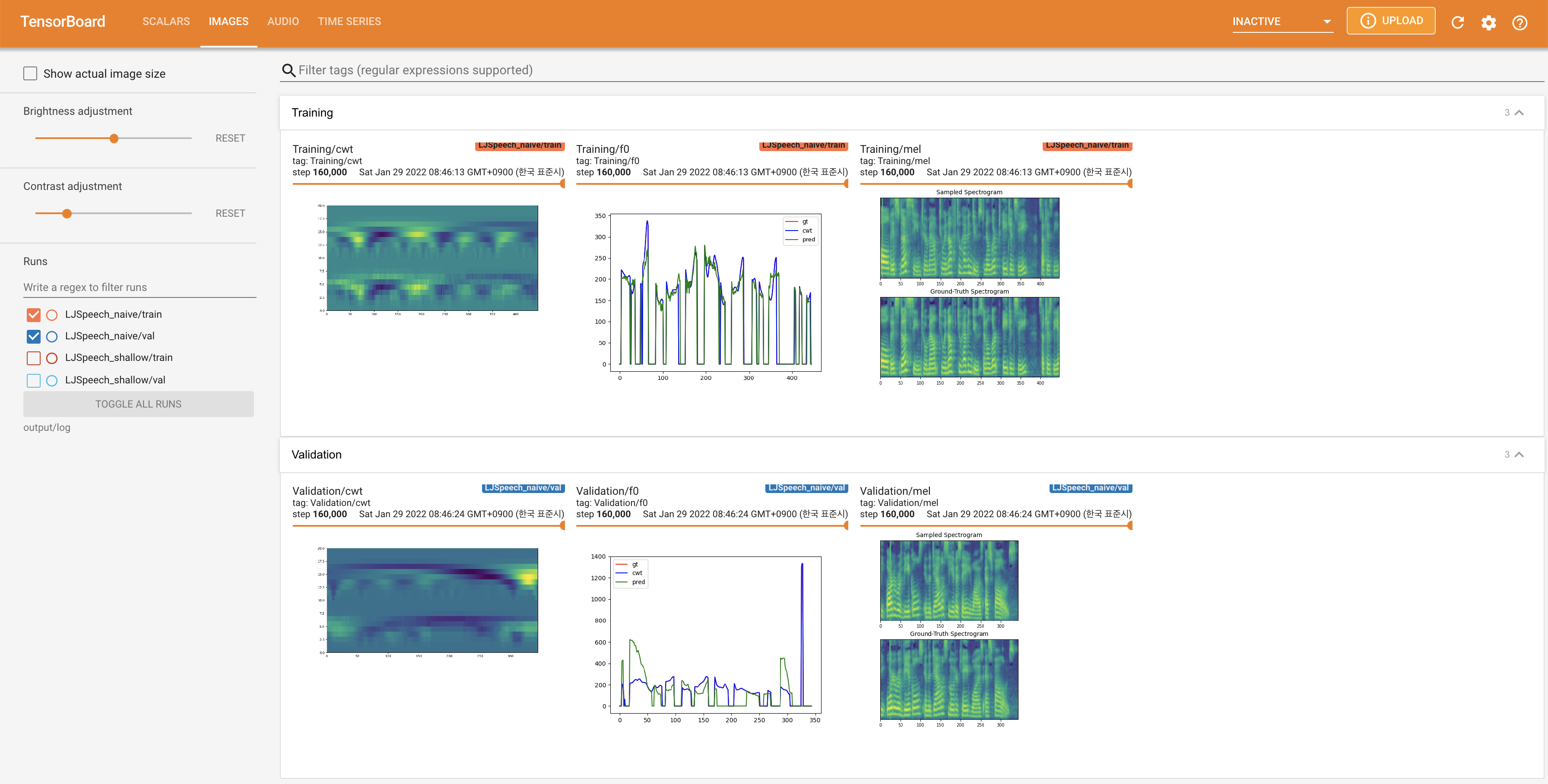
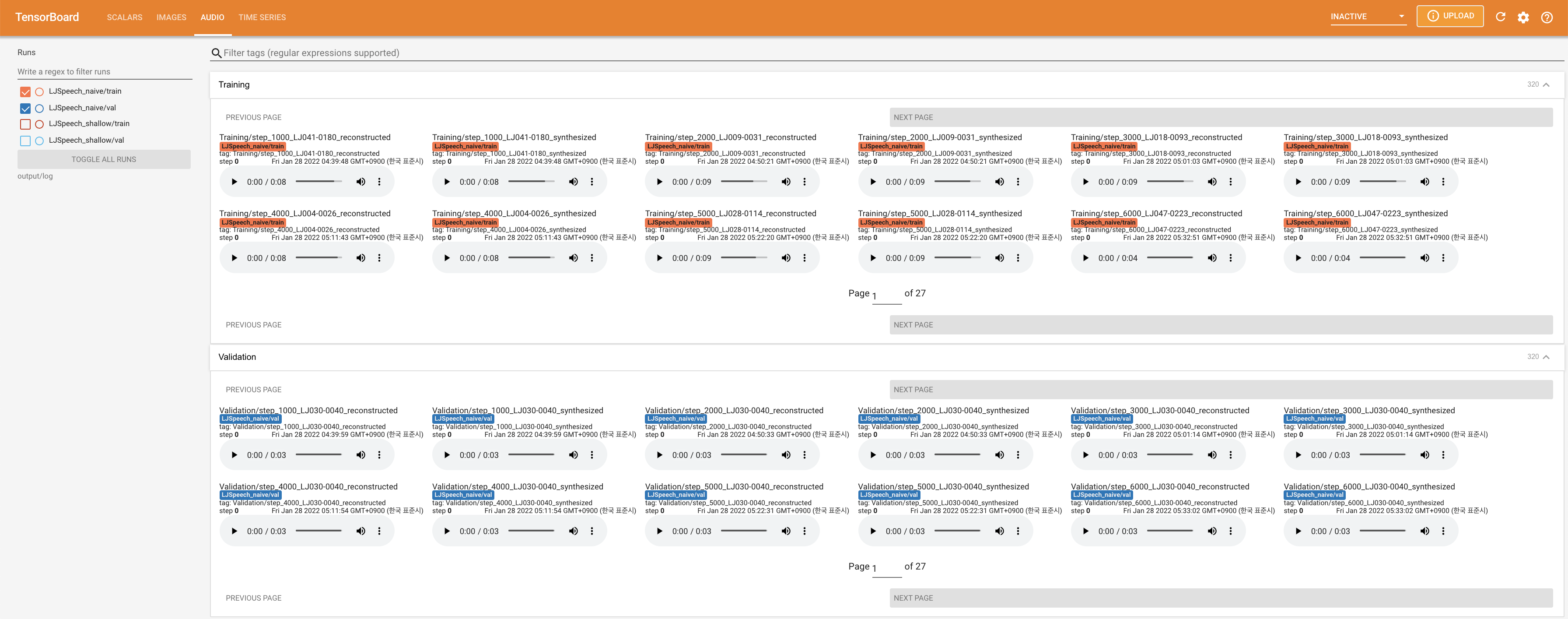
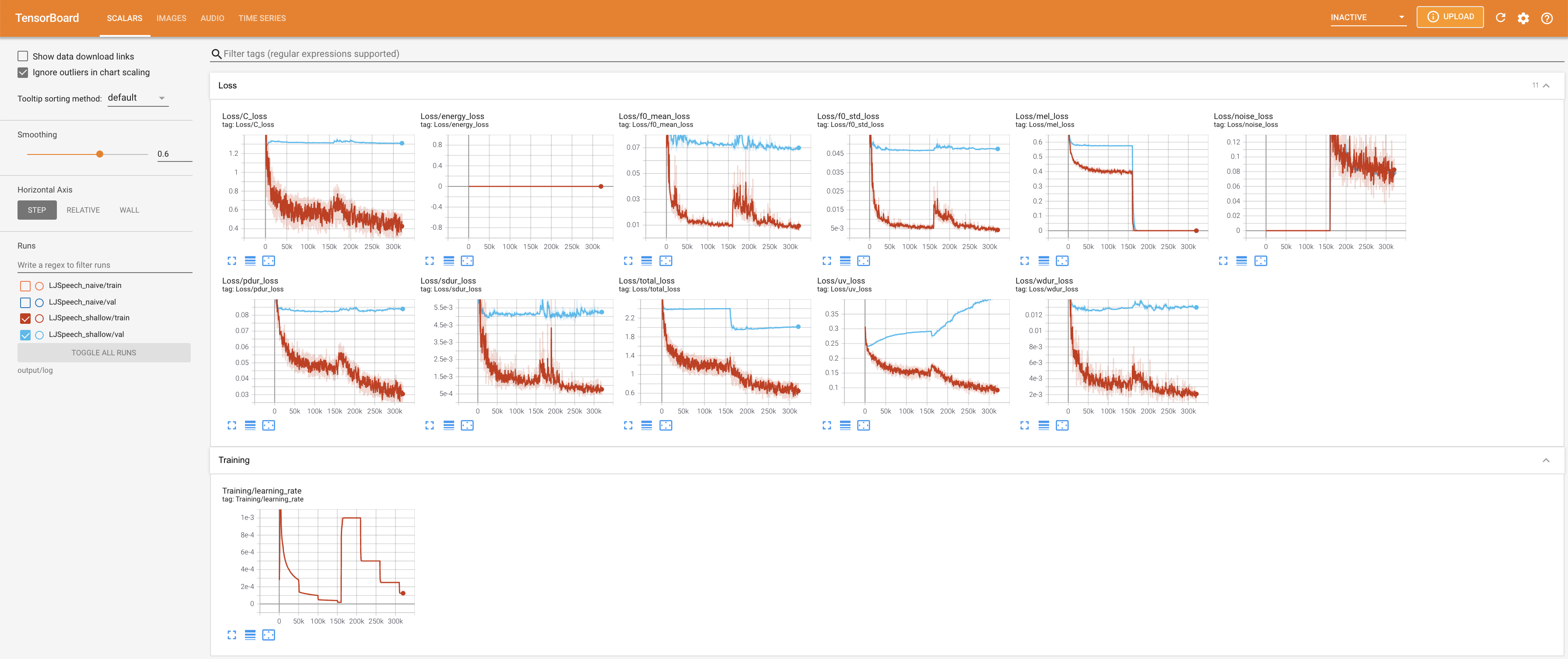
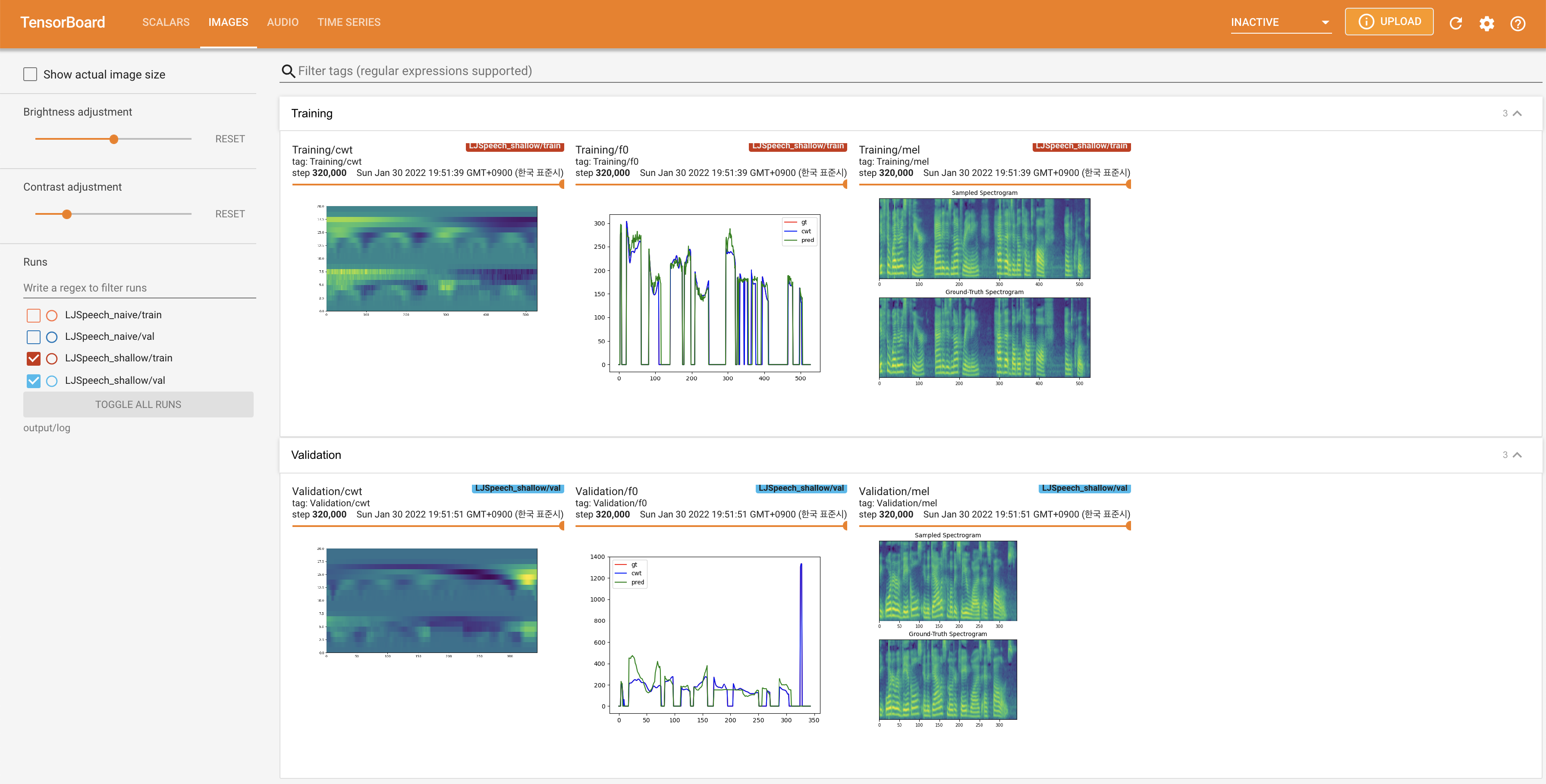
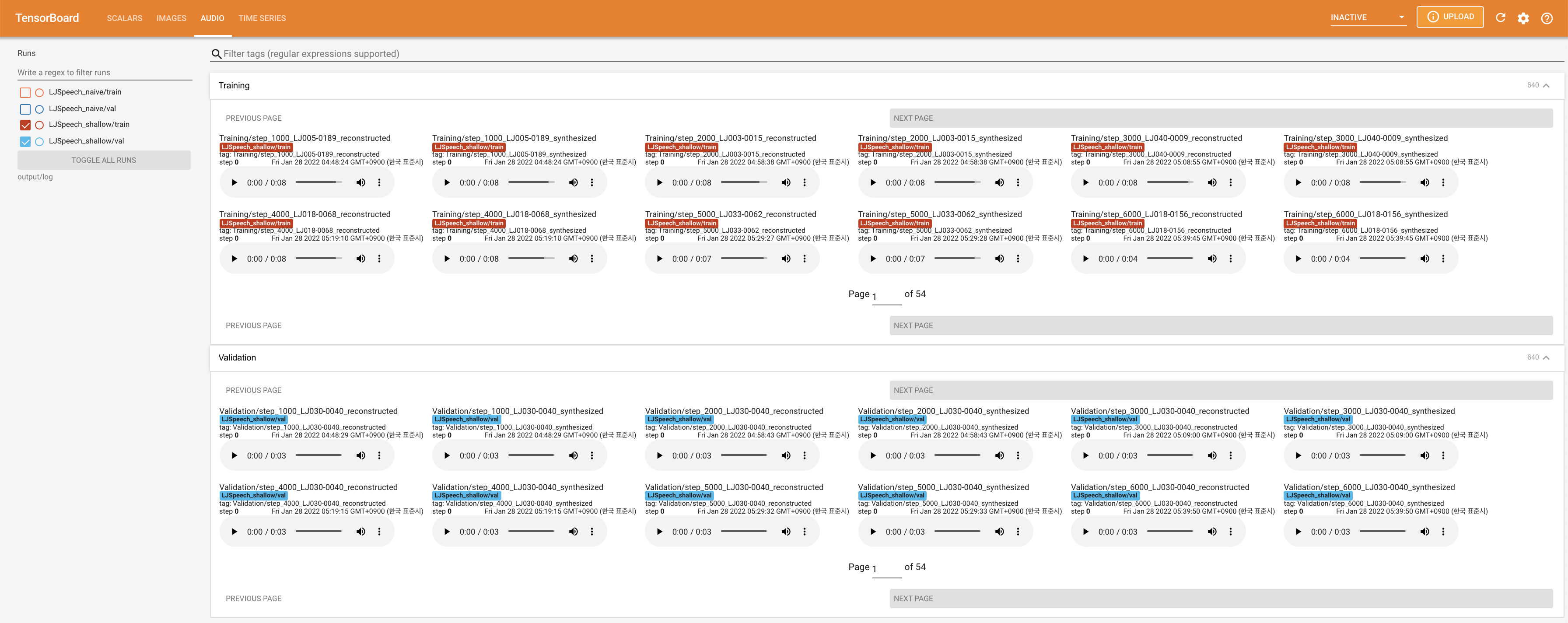
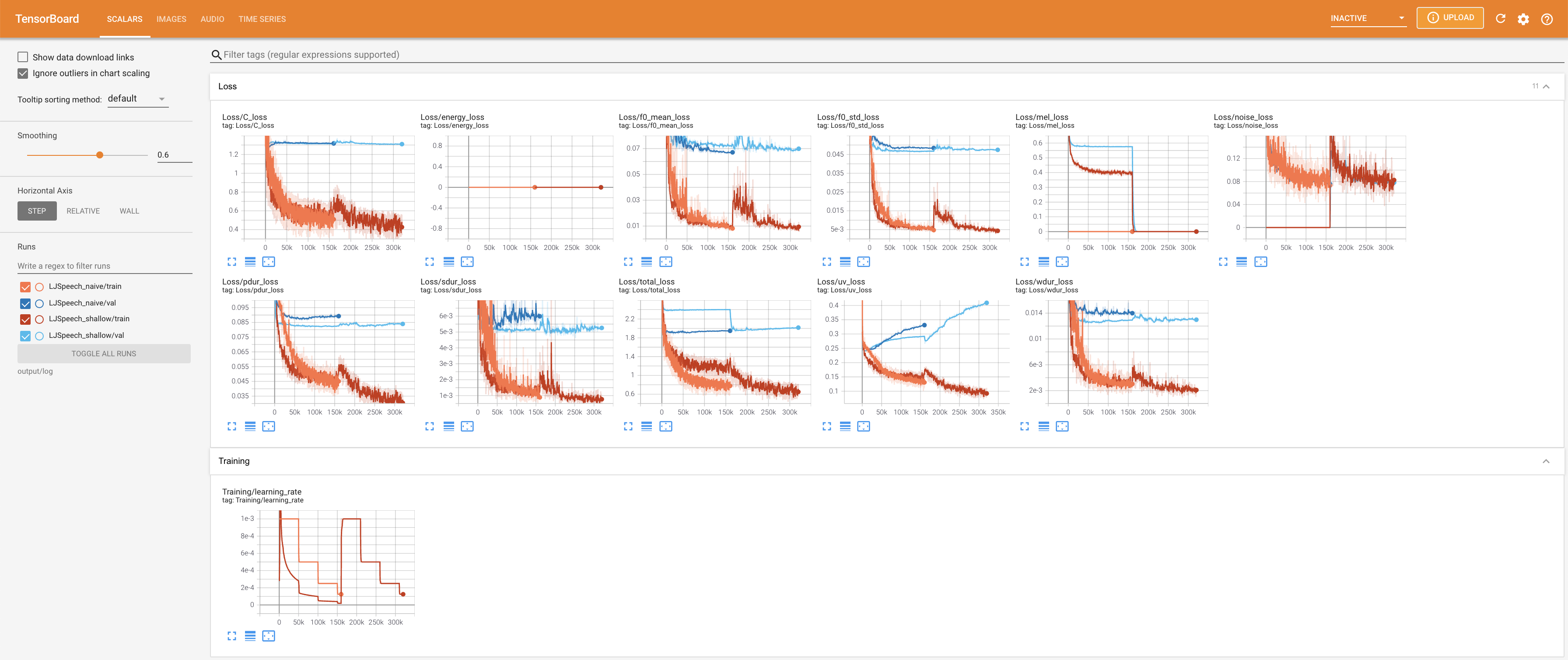
27.767M , was dem Originalpapier ( 27.722M ) ähnelt.100 , was die vollen Zeitschritte der naiven Diffusion ist, so dass bei Diffusionsschritten keinen Vorteil hat. @misc{lee2021diffsinger,
author = {Lee, Keon},
title = {DiffSinger},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/DiffSinger}}
}


